







1.迭代器(以string为例)
(1)基本理解:在我们刚接触迭代器的时候,我们可以将迭代器理解为改造过的“指针”,这是一个新的类型,指向对应容器中的各个元素。我们可以像指针那样对迭代器进行++,*等操作,只不过++是指向下一个元素而非下一个字节,*得到的是对应的元素而非一个字节的内容。我们发现虽然迭代器并不能完全和指针划等号,但是它们的功能基本相同,而且在迭代器更安全、方便,支持所有容器,因此它是主流、通用的访问方式。
(2)begin、end:
begin和end是对应类的成员函数,在不同容器有不同的实现方法。
要得到对应容器的迭代器,我们需要调用实例化对象的成员函数。

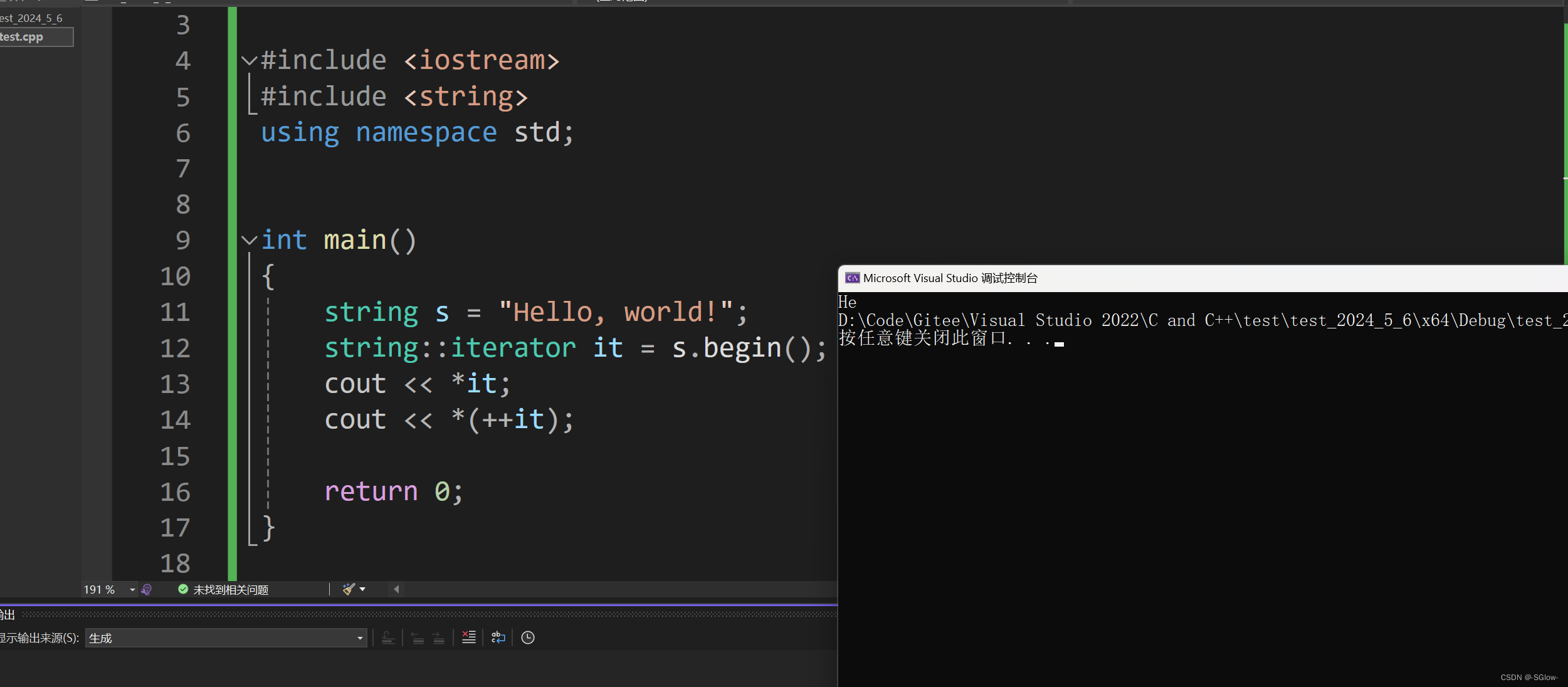
迭代器在不同的容器里面访问的大小、方式都有所区别,因此迭代器是根据不同容器设计的,所以注意迭代器类型前面要确定类域,写作string::iterator
同样我们也可以获取末尾元素(有效字符)的下一个元素\0的迭代器

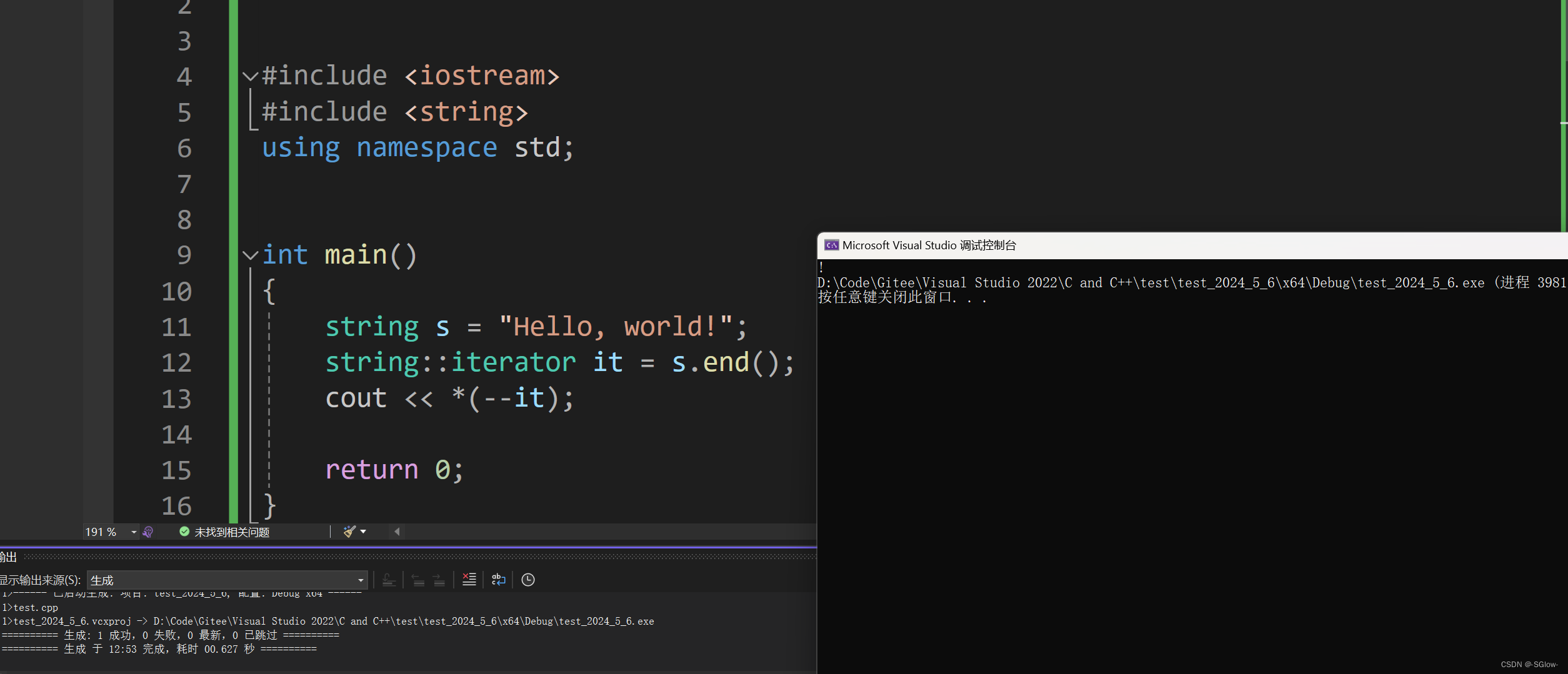
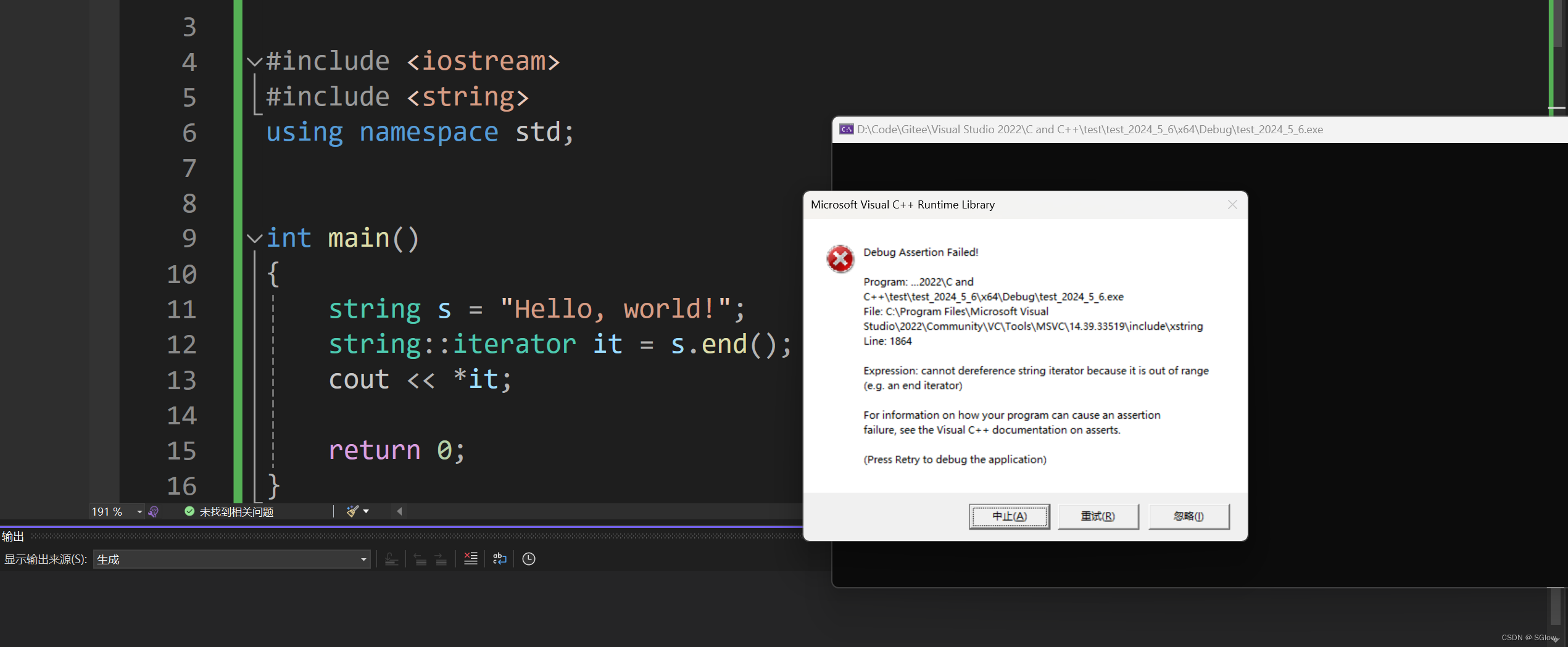
注意左闭右开的规则,不要越界访问,虽然我们知道\0也是字符串的一部分,本质上说也不算越界,但是考虑到实际使用没正常人会去对这个\0动手脚(如果单独改了这个\0,就会导致字符串没有\0,会引发一系列隐患),所以只要访问\0或者越界,就会断言。
(3)范围for的运用
利用迭代器,我们可以很轻松的访问对象里面的数据,就像指针一样。
但我们还有其它更简洁的方法。
C++借鉴了其它语言的范围for用法,使用for (type e : arr)可以快速遍历数组,不会发生越界,也不需要自己去算数组的大小,很方便。范围for的实现本质上是迭代器,遍历的时候是自动调用函数begin得到初始位置的迭代器并“解引用”,自动++直到和end迭代器相同为止,这也是范围for知道从哪里开始,从哪里结束的原因。因此我们可以应用于string中,实现快速遍历。
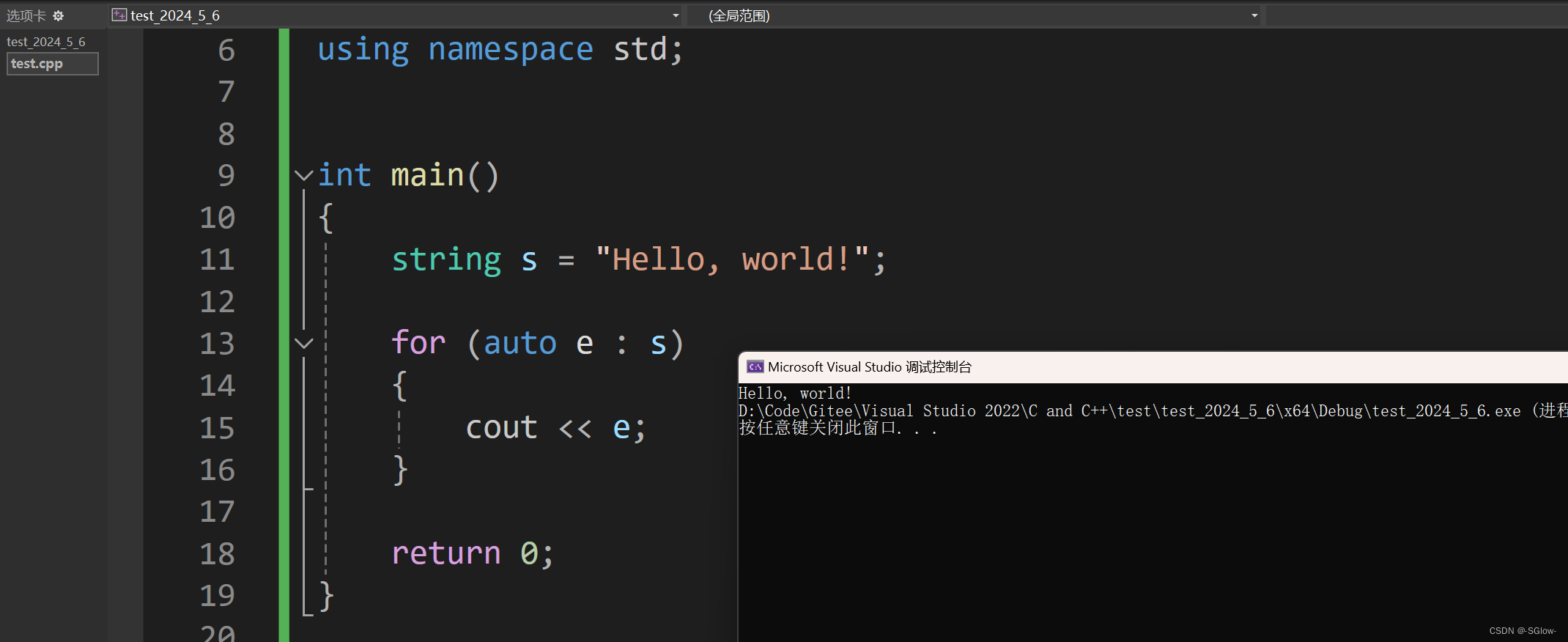
这里值得注意的是,我们得到迭代器后可以对对应的数据进行修改,这并没有影响封装的特性,因为迭代器本身就是类里面定义出来的,修改数据的手段受到迭代器本身的限制(不能随便针对某个字节进行修改,只能对有效部分的数据修改),数据方法集为一体。
注意要使用引用才能修改,否则e是临时变量
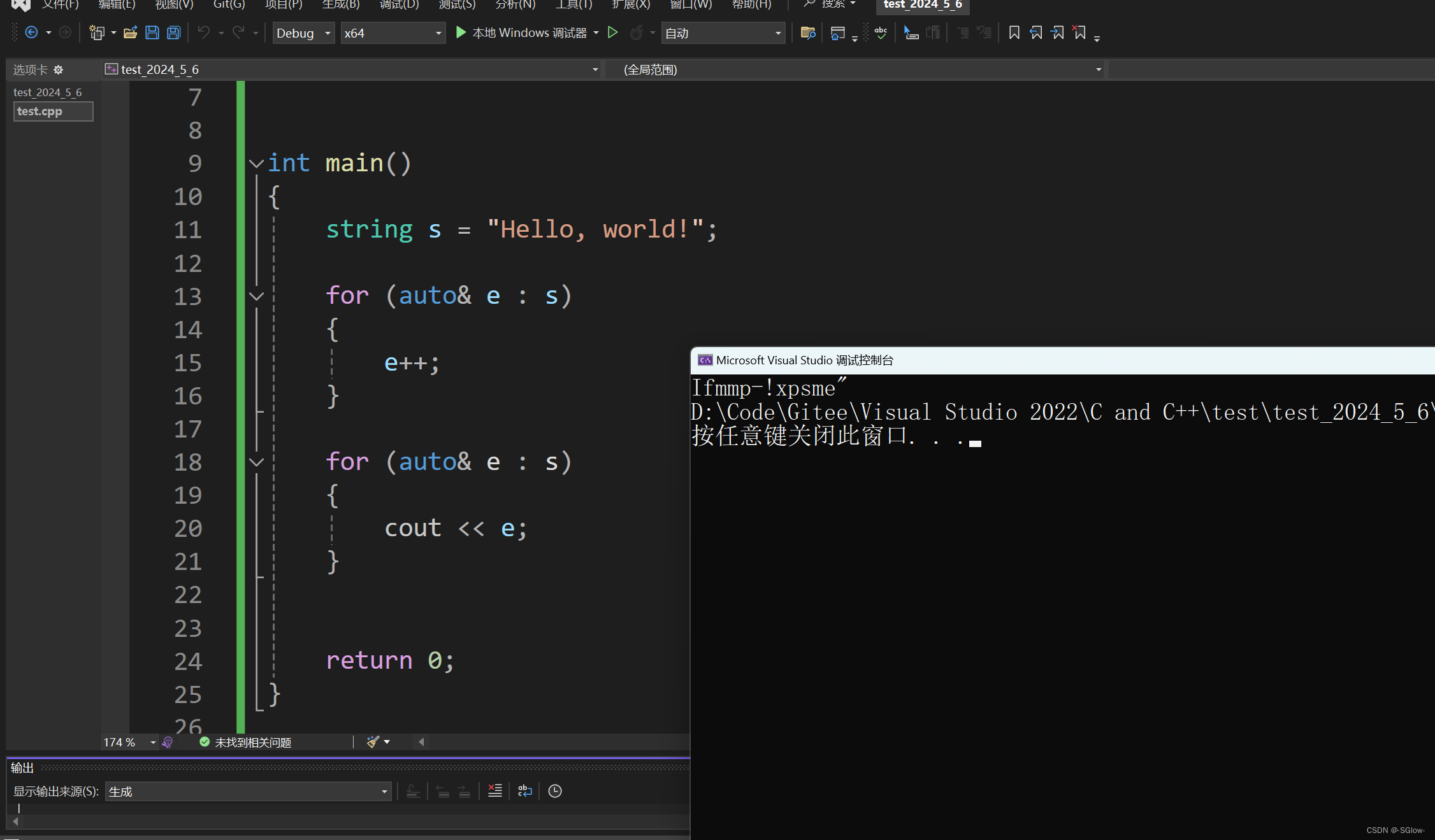
而相对应的,c_str得到的就是string的地址,我们不能修改解引用的值,因为这个时候如何修改完全不受控制,会影响封装的特性。

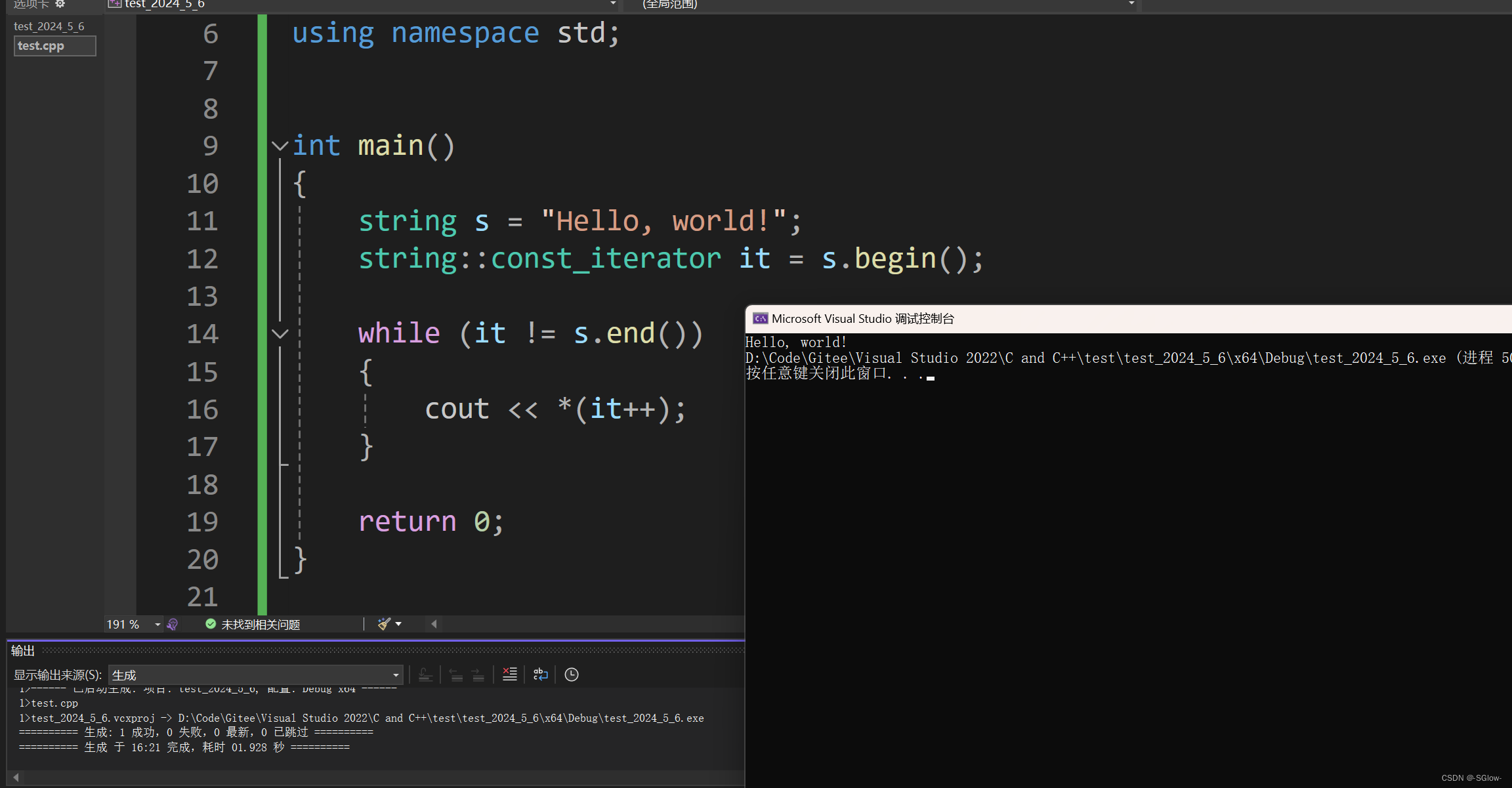
(4)iterator begin() 和 const_iterator begin() const 的区别
我们要注意,迭代器根据访问权限的区别分为了iterator和const_iterator,这和指针一样,限制在于加了const的迭代器没有办法进行解引用再修改值的操作,也就是只读不写。一般当我们使用const string实例化对象的时候就只能用const_iterator,其调用的所有成员函数后面都要有const修饰(修饰的是this指针)
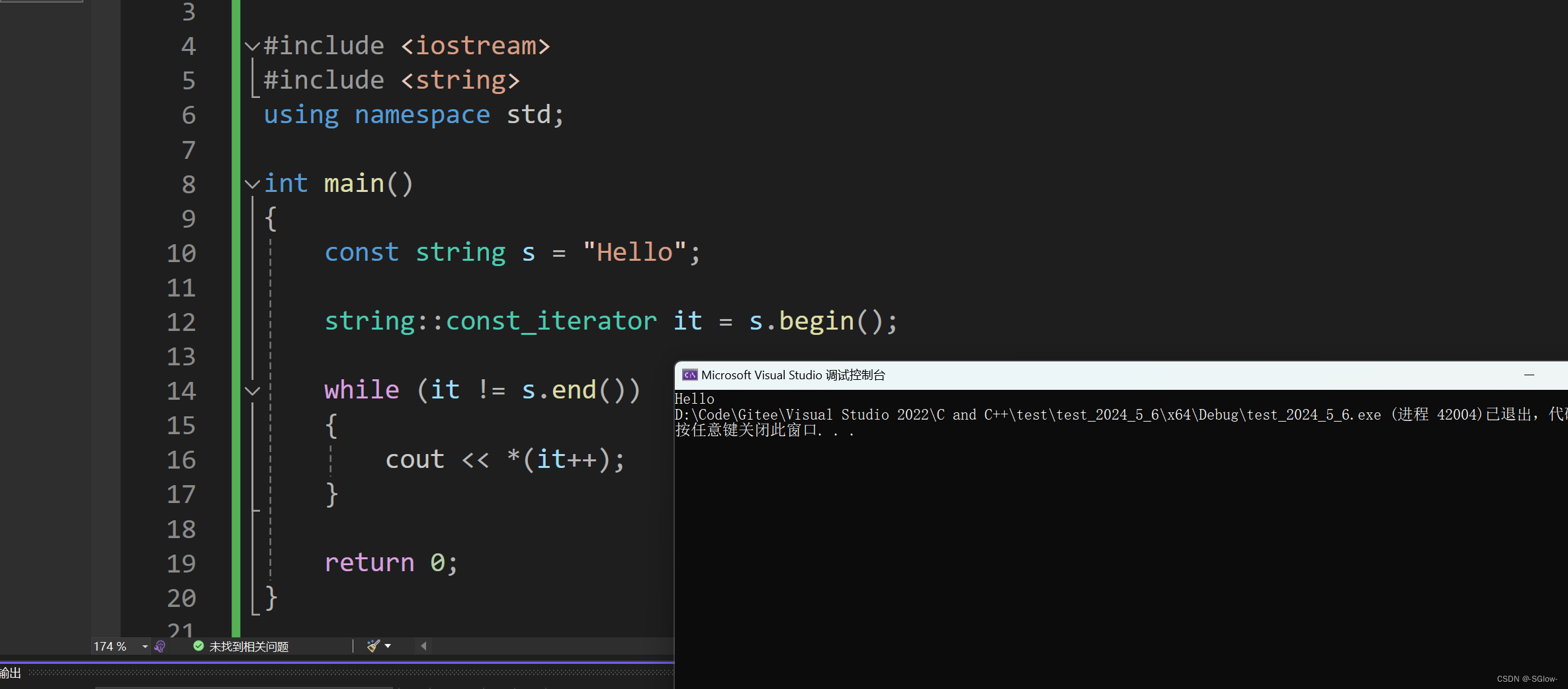
其中s.end()会去自动调用匹配const_iterator end() const,原因在于end成员函数构成了函数重载,会根据this的类型去自动匹配合适的。
但是注意有无const修饰的迭代器之间不能隐式类型转换。如果接收返回值的迭代器类型错误的话,会报错。
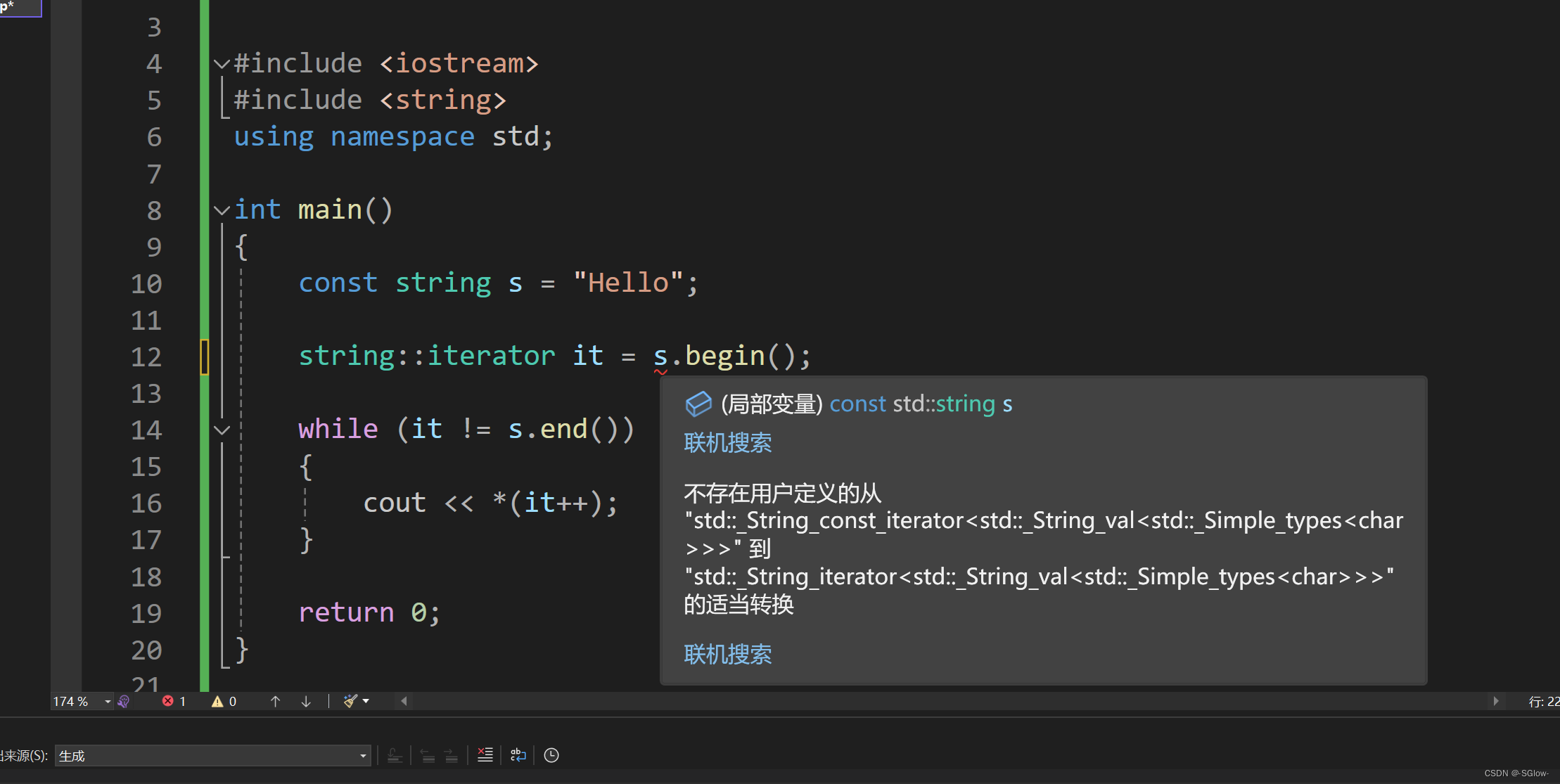
可能还有人会混淆const_iterator和const iterator。const iterator修饰的是iterator,即不能修改iterator本身,那么迭代器本身就失去了意义,所以没有这种迭代器。const_iterator修饰的是iterator解引用后的值,不能修改。这个区别和指针的const规则类似,只不过指针是根据const和*的相对位置来区分的,迭代器iterator就一个单词,不存在相对位置的概念,所以使用const_放在iterator前面表示区分。
(5)反向迭代器
反向迭代器和正向迭代器的主要区别在于反向迭代器是用于从后向前遍历的。
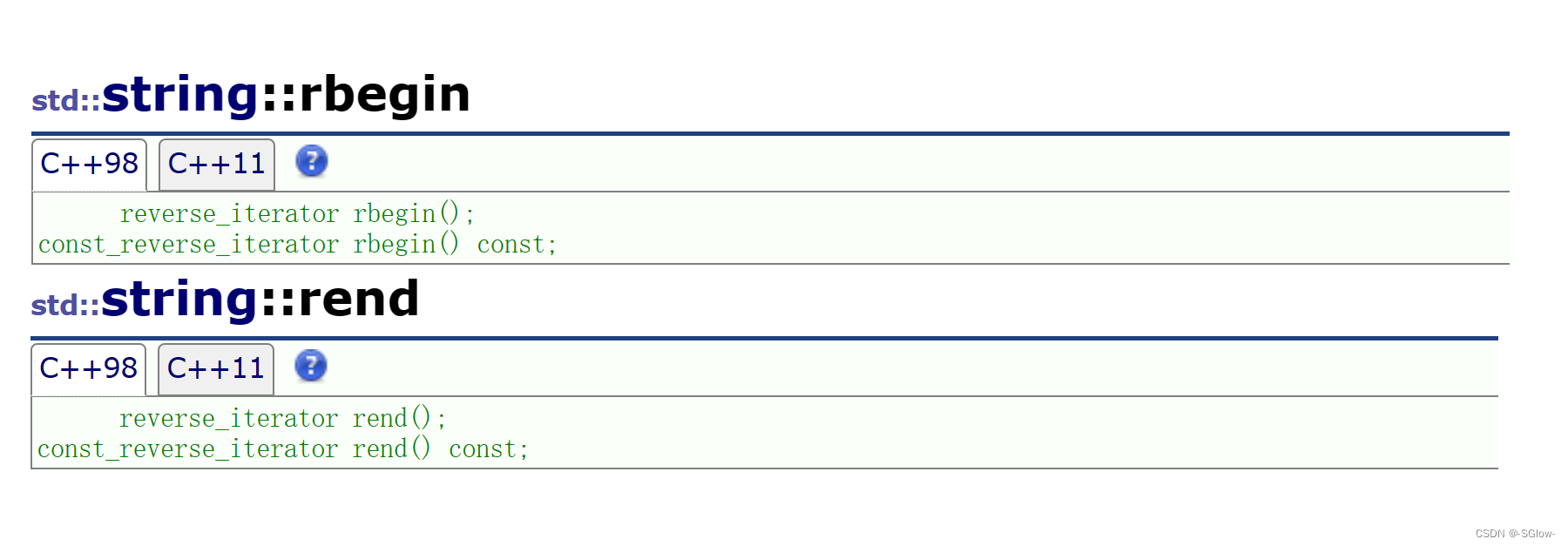
当我们用rbegin时,得到的是串中最后一个有效字符(不包含\0)
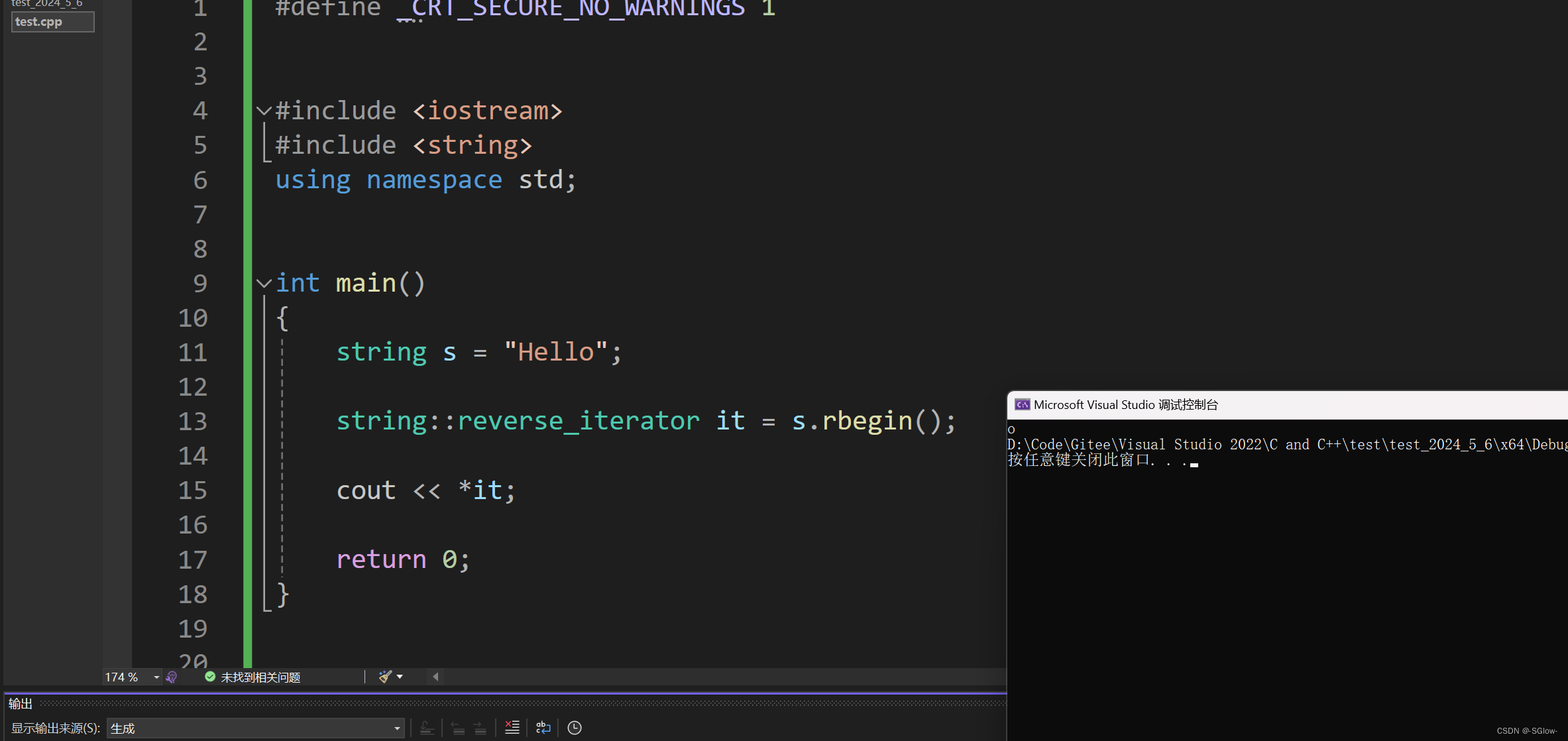
而rend返回的是串中第一个字符的前一个理论字符的迭代器(这个字符不存在,是假设出来的,这里实际上已经越界了,和end有区别)
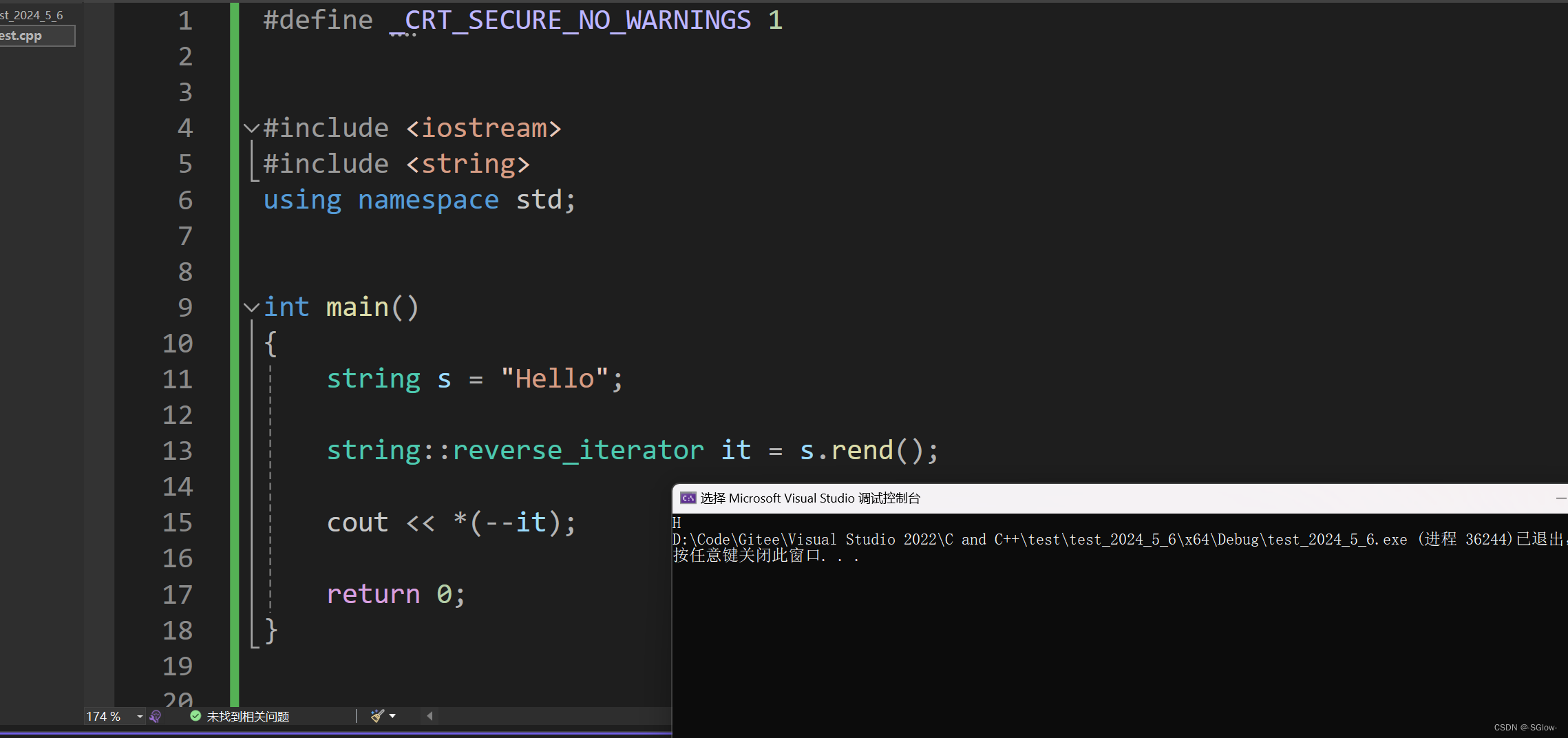
值得注意的是返回的迭代器类型是反向的,和正向的不相通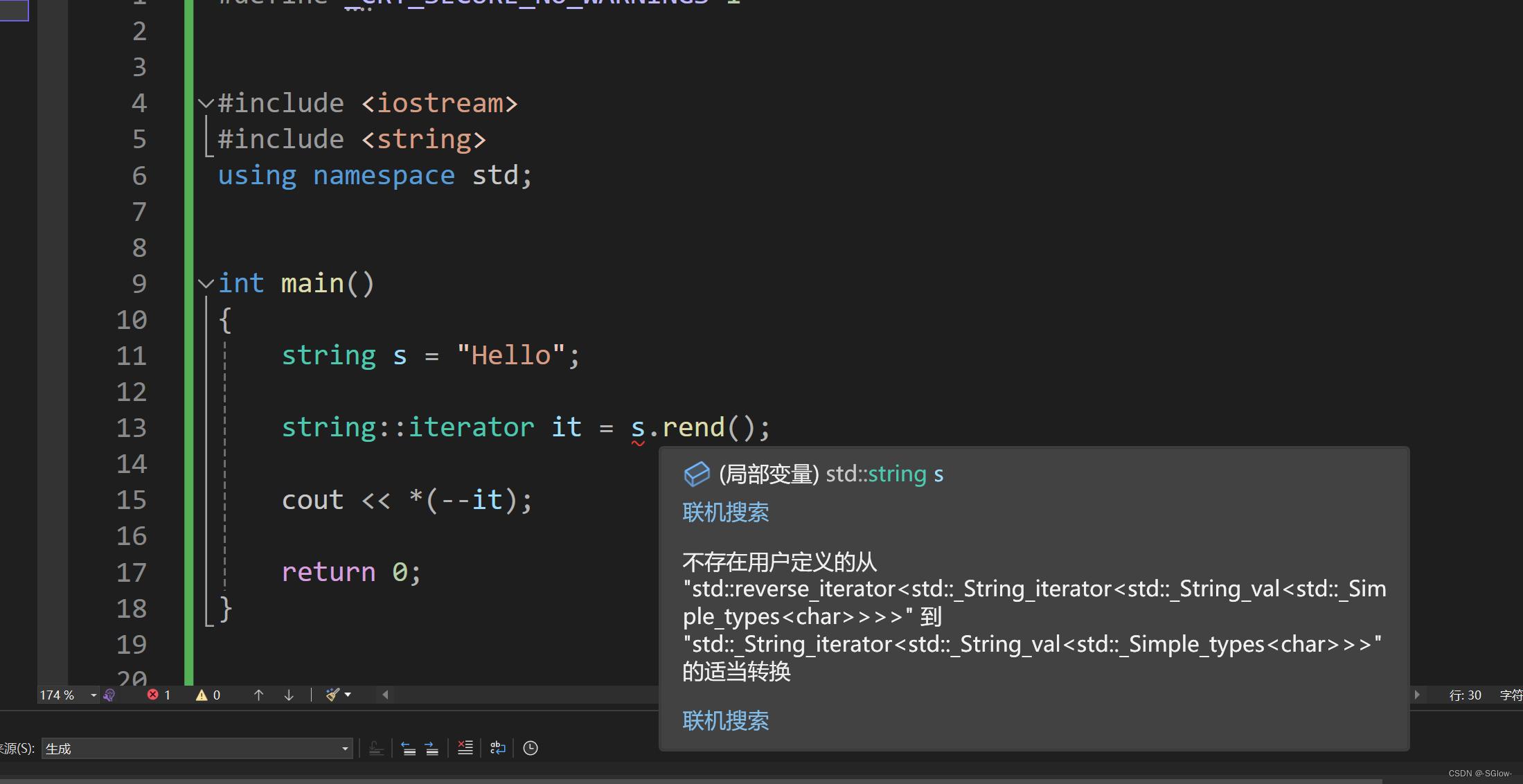
反向迭代器的其它特性和正向迭代器的相同,都存在const修饰问题。即返回值reverse_iterator和const_reverse_iterator,这里就不重复讲它们的区别了。
但是反向迭代器不能直接支持范围for,范围for自动调用的是正向迭代器,即从前向后遍历。
我们只有自己手动实现从后向前遍历。
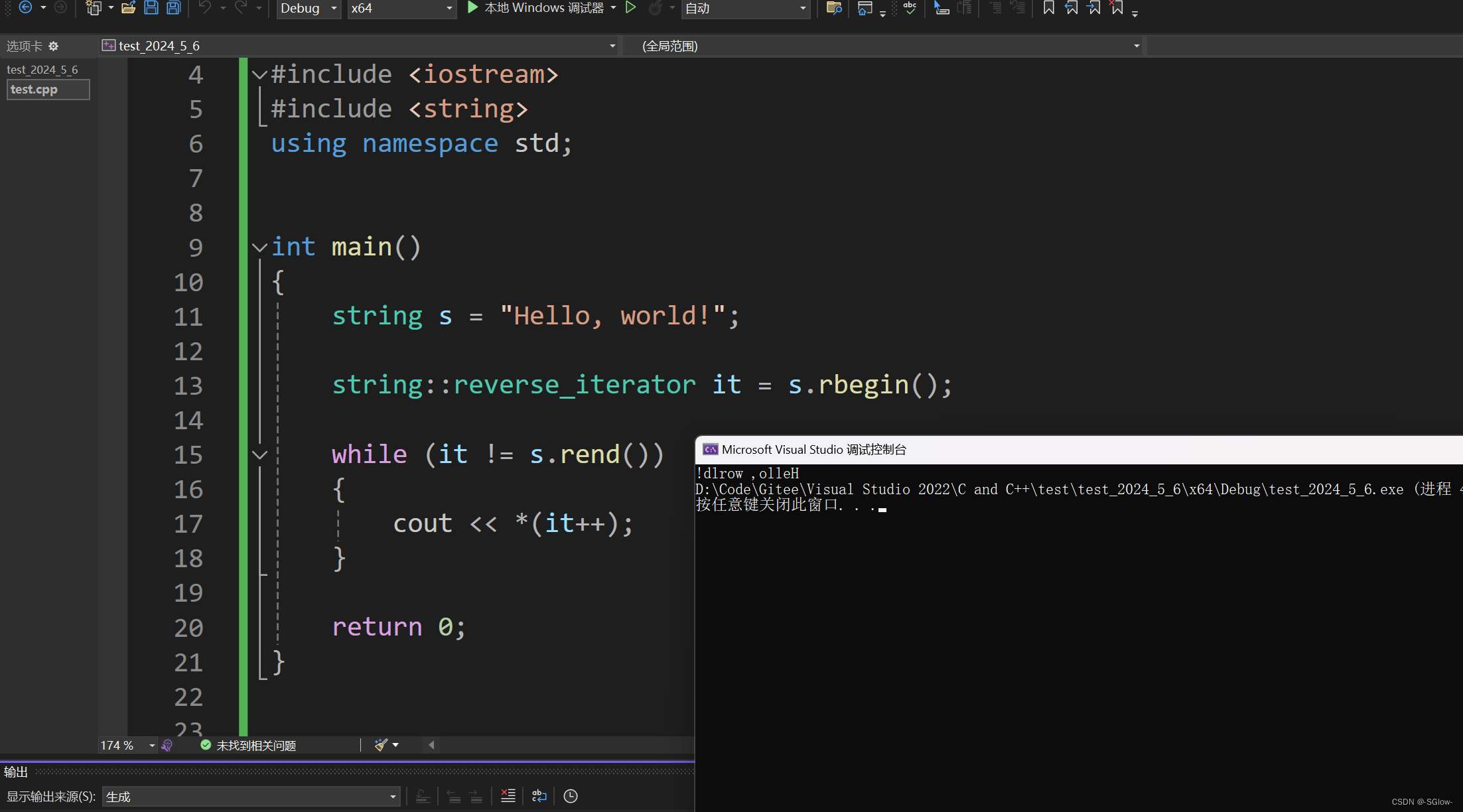
在这里我们也可以看到正反迭代器之间的区别。当我们++时,反向迭代器的变化相当于正向迭代器的--
2.扩容
当我们要读取整个文件的字符并把它存到string中时,我们发现如果什么都不处理,默认情况下string会进行多次扩容,扩容意味着多次移动数据,涉及多次数据复制,大大影响了性能。所以在有预见的情况下,我们可以手动扩容,一次性申请大一点的空间,这样挪动数据的消耗就很小。
(1)capacity、size

要理解扩容,我们需要对capacity、size有一定了解。
当我们创建string对象时,capacity和size也随之生成,这和顺序表一致,当我们存入数据时,size会增加,数据超过一定量时,会出现扩容。扩容的时候capacity也会随之变大。
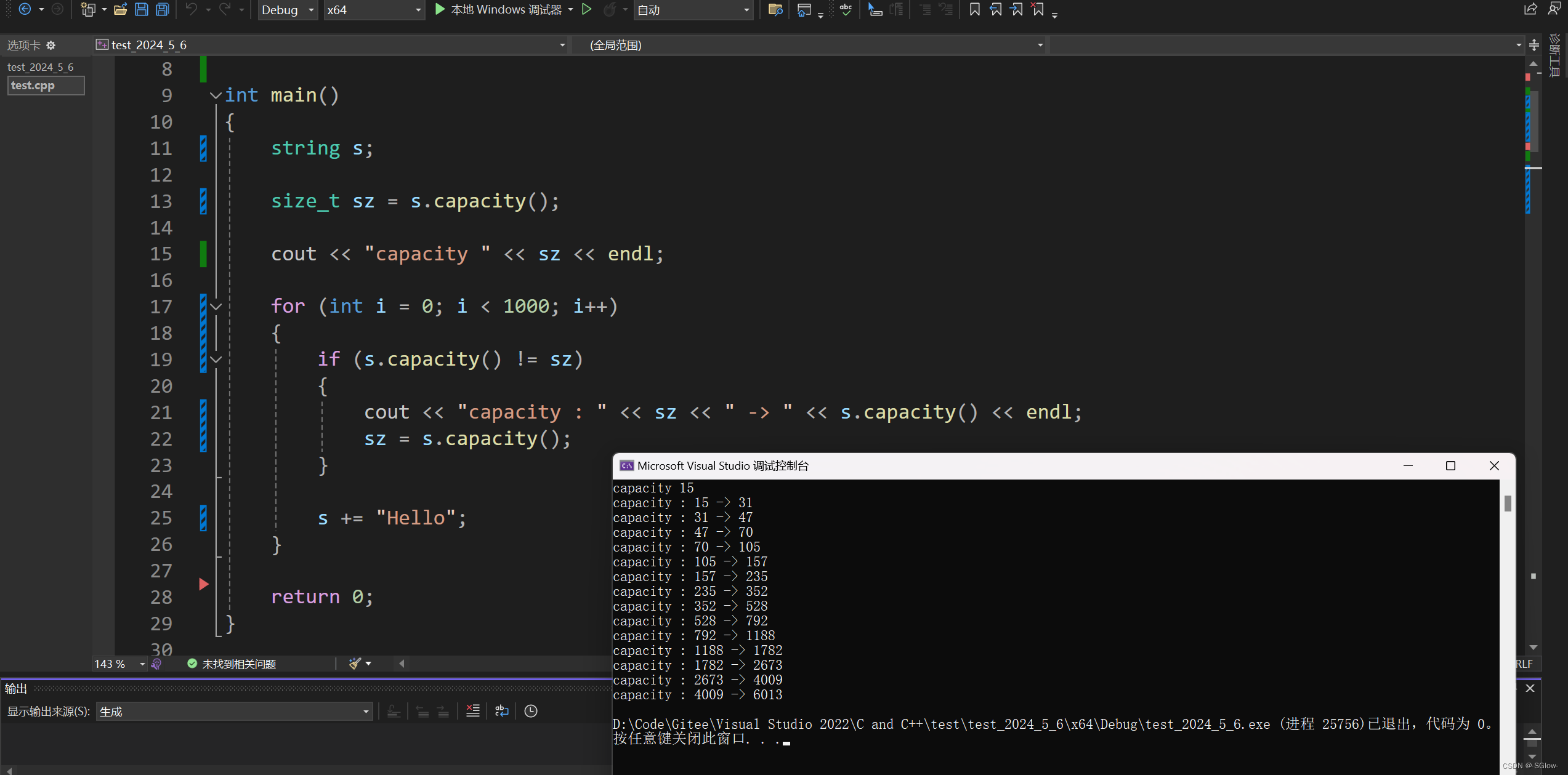
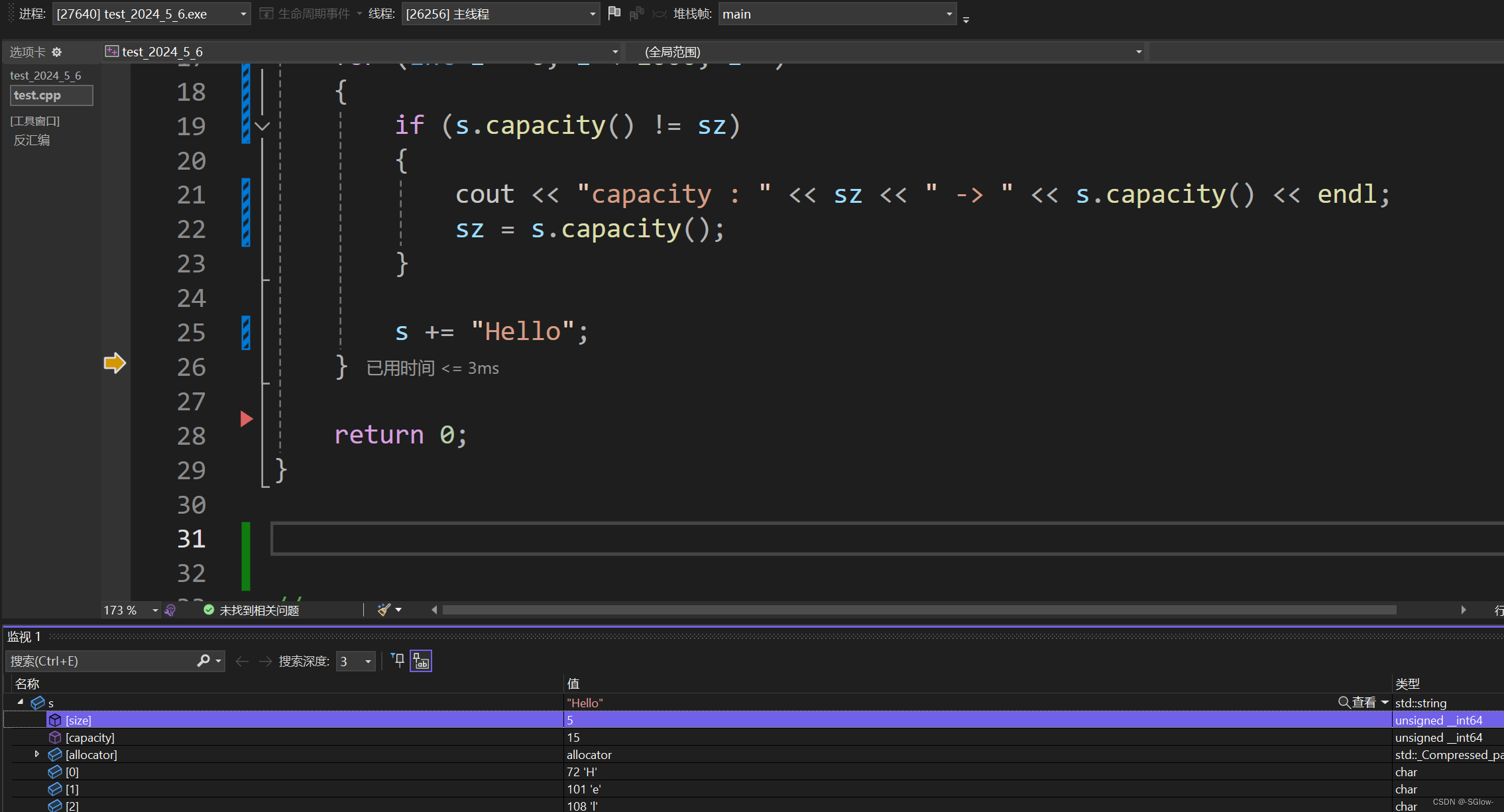
注意size指向的是\0对应的下标,也就是有效数据的下一个,capacity也是指有效空间,但它其实多开辟了一个用来存\0
当使用迭代器的时候,就会受到size的限制,当迭代器指向的数据下标大于等于size对应的值时,就会判定为越界,等于size时指向的就是\0
和顺序表一样,capacity表示的是实际开辟的空间-1(有效空间,为\0预留一个字节),但是超过size的就无法访问
(2)reserve

reserve就是提前开辟空间,修改capacity的函数,它的好处在于一次性就开辟这么多空间,capacity不会再轻易地变化了。也就是说对数据的转移会减少,能有效提高程序效率。
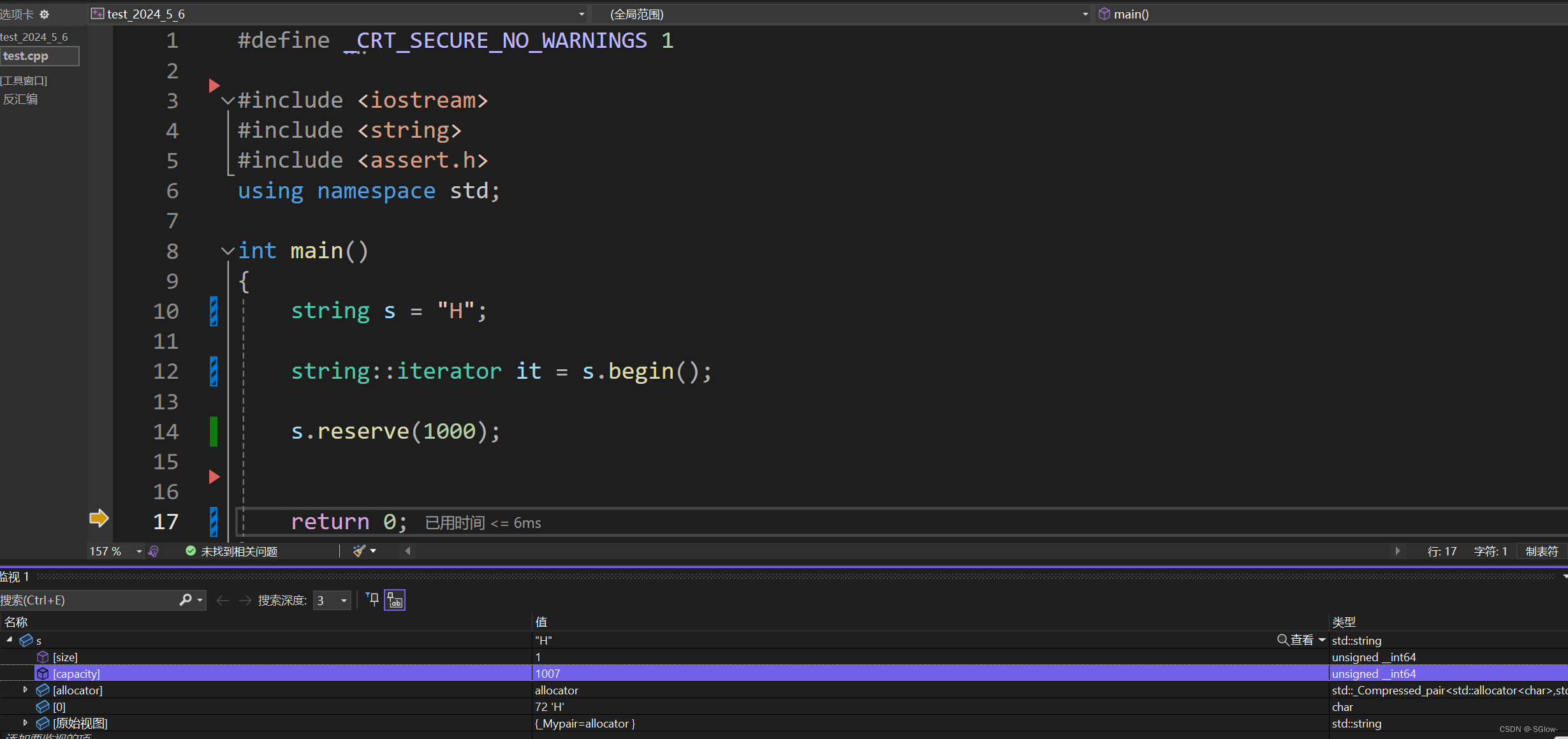
你会发现,capacity实际的大小不是1000,这是编译器自己的处理,我们用去过分关心。
但是提前开辟空间并不代表这块空间能够被访问。虽然我们看到capacity变大了,但size并不会改变,迭代器的访问范围依旧限制在扩容前的范围内。
(3)resize

resize也是提前开辟空间的一个函数,但是它和reserve有本质区别。reserve是预开辟空间,这块空间不能被访问,不会对现有的串造成影响,访问范围也不会改变。
但resize在开辟空间,修改capacity后,还会修改size,直接扩充了我们访问的范围。
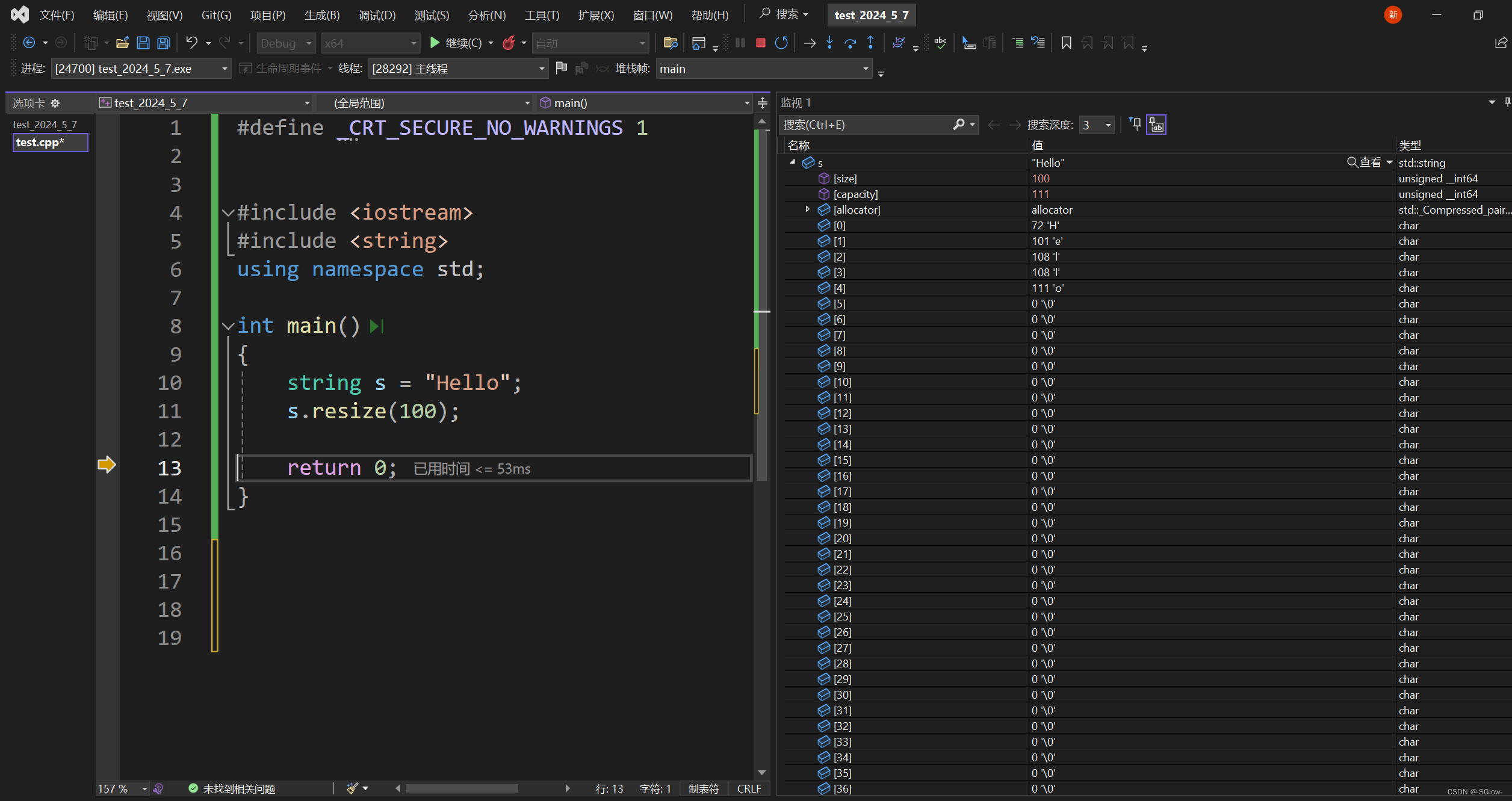
我们发现扩容后,size直接跳到100,意味着0~99的数据都能被正常访问,在默认情况下,扩容后的空位补\0,你也可以指定字符。
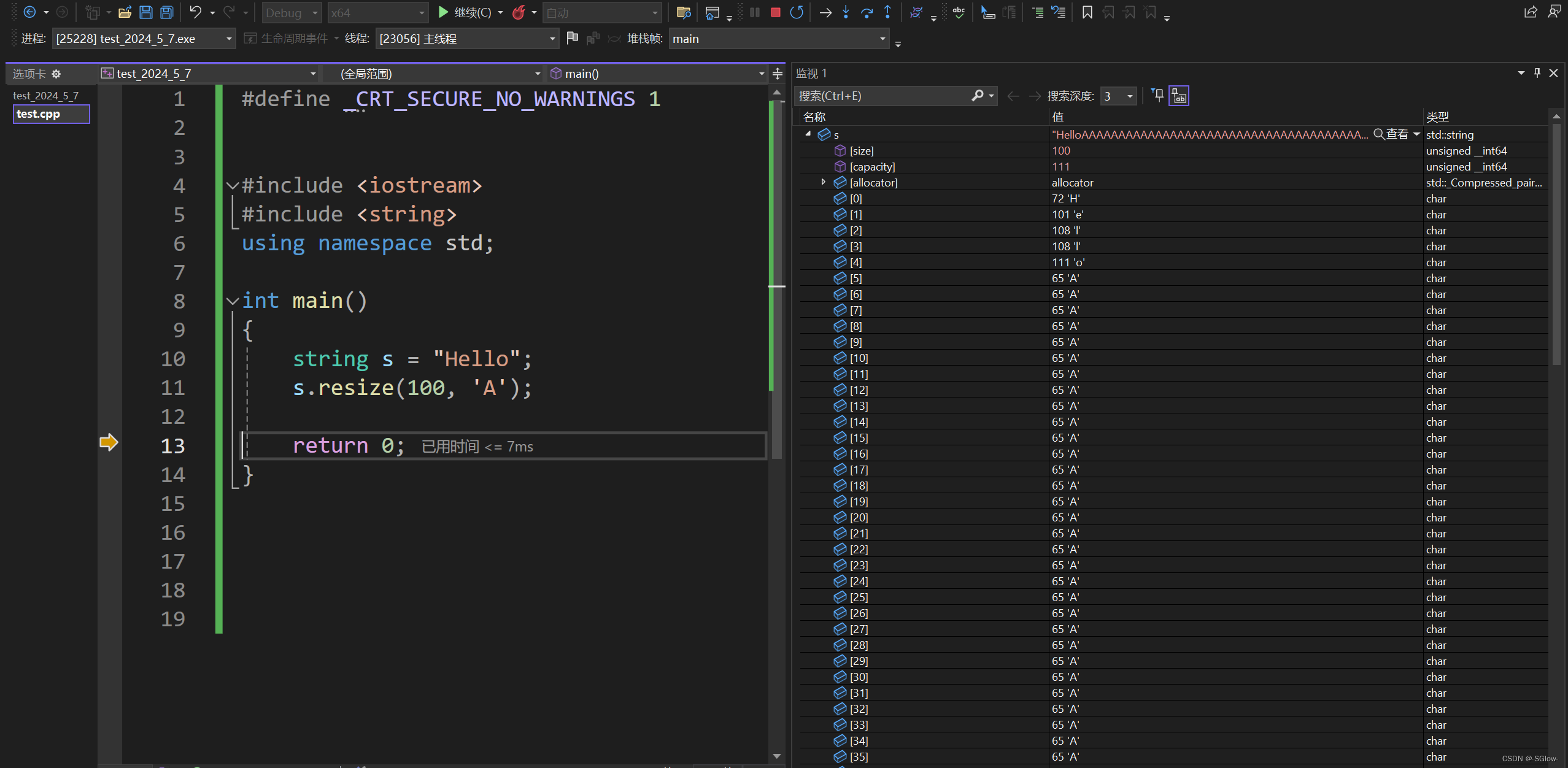
用resize还是reserve要根据具体情况具体分析,resize用于扩容的时候要慎用,因为它的参数的意思是将string扩充到n个字节而不是预开辟n个字节,之后填充数据是直接从size开始,这很容易出现浪费空间的情况。
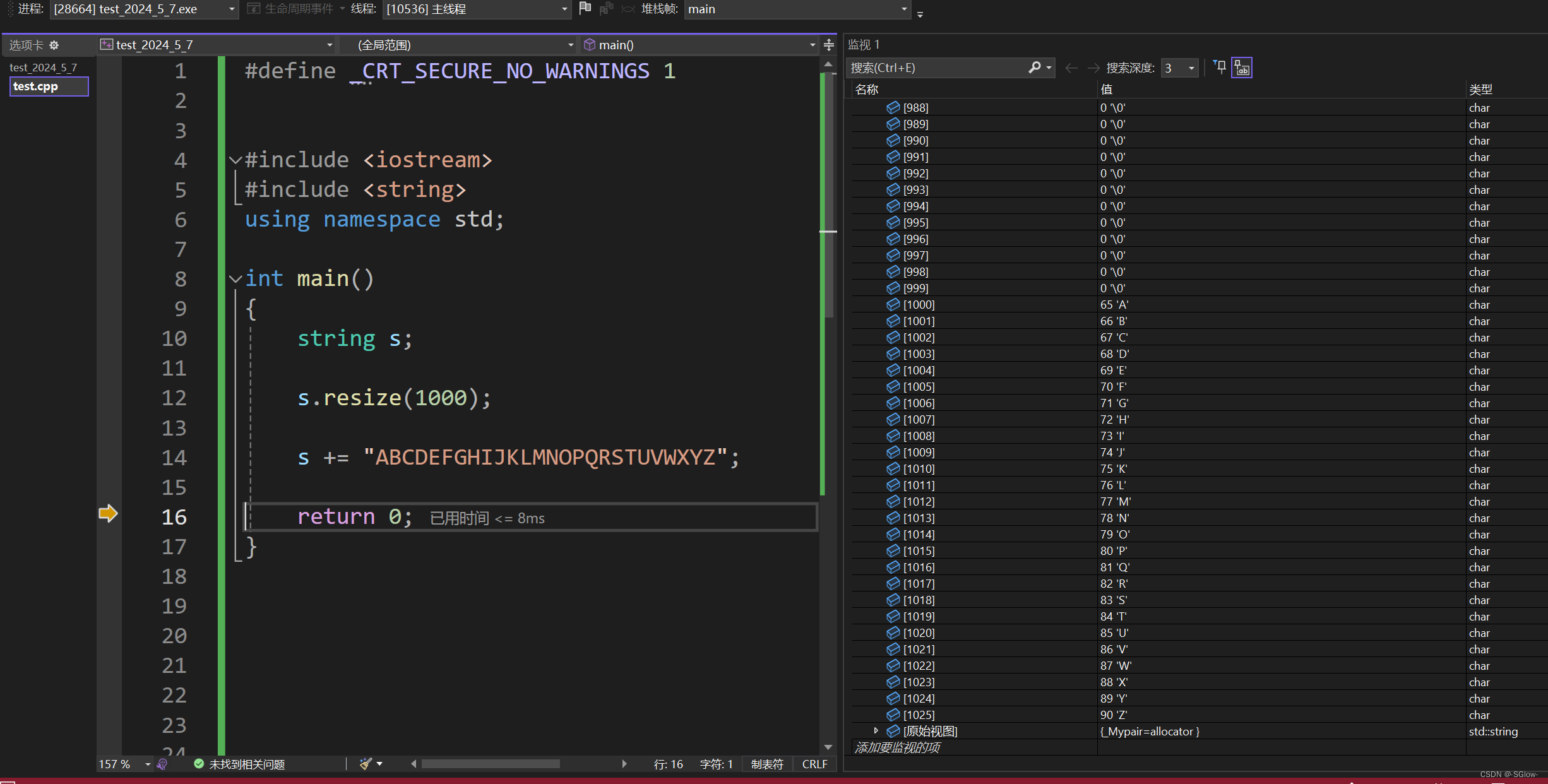
3.缩容
(1)缩容的话不推荐使用reserve,在有的编译器低下什么事都不会做
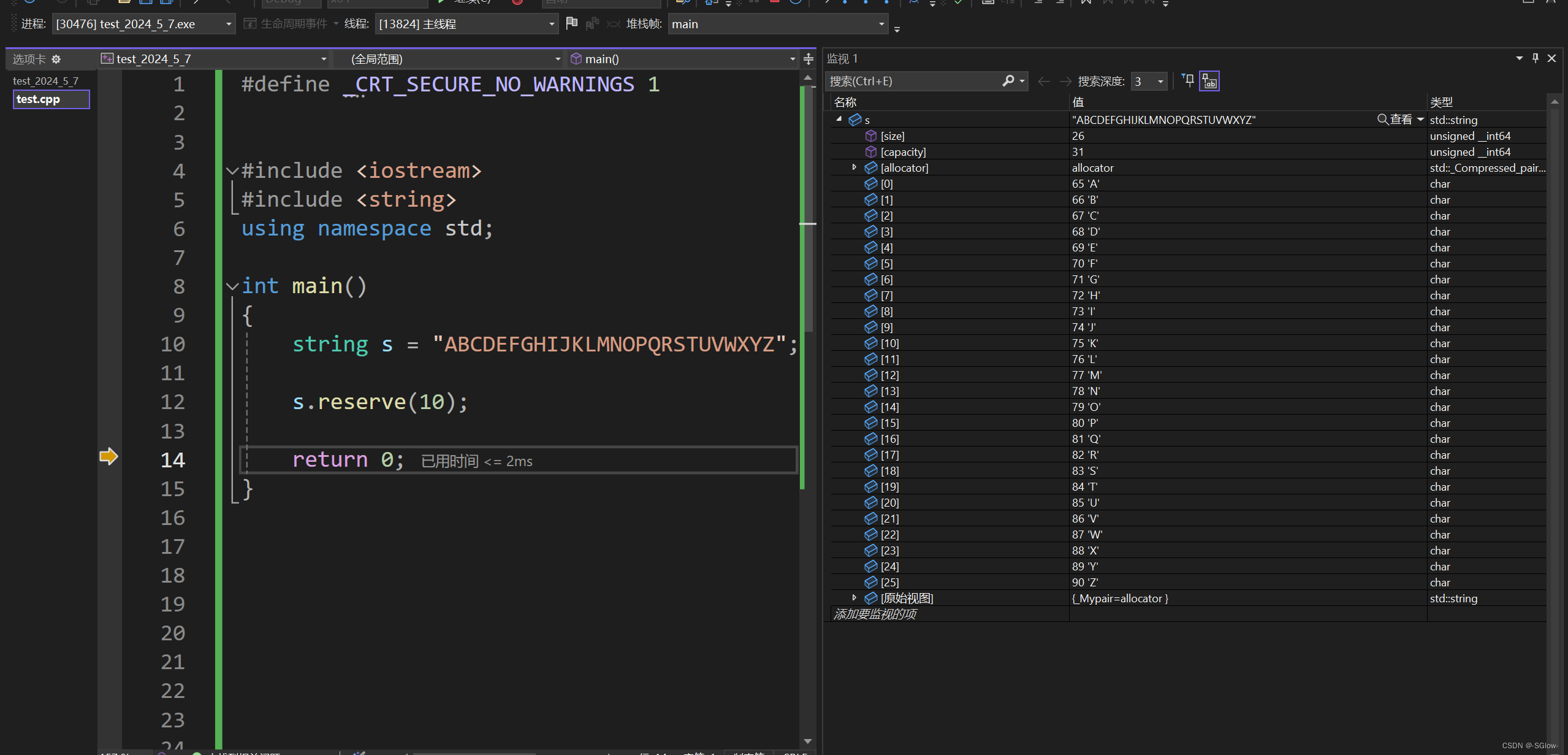
(2)resize能缩容,是将多余的数据直接抛弃,将size定位到设置的值
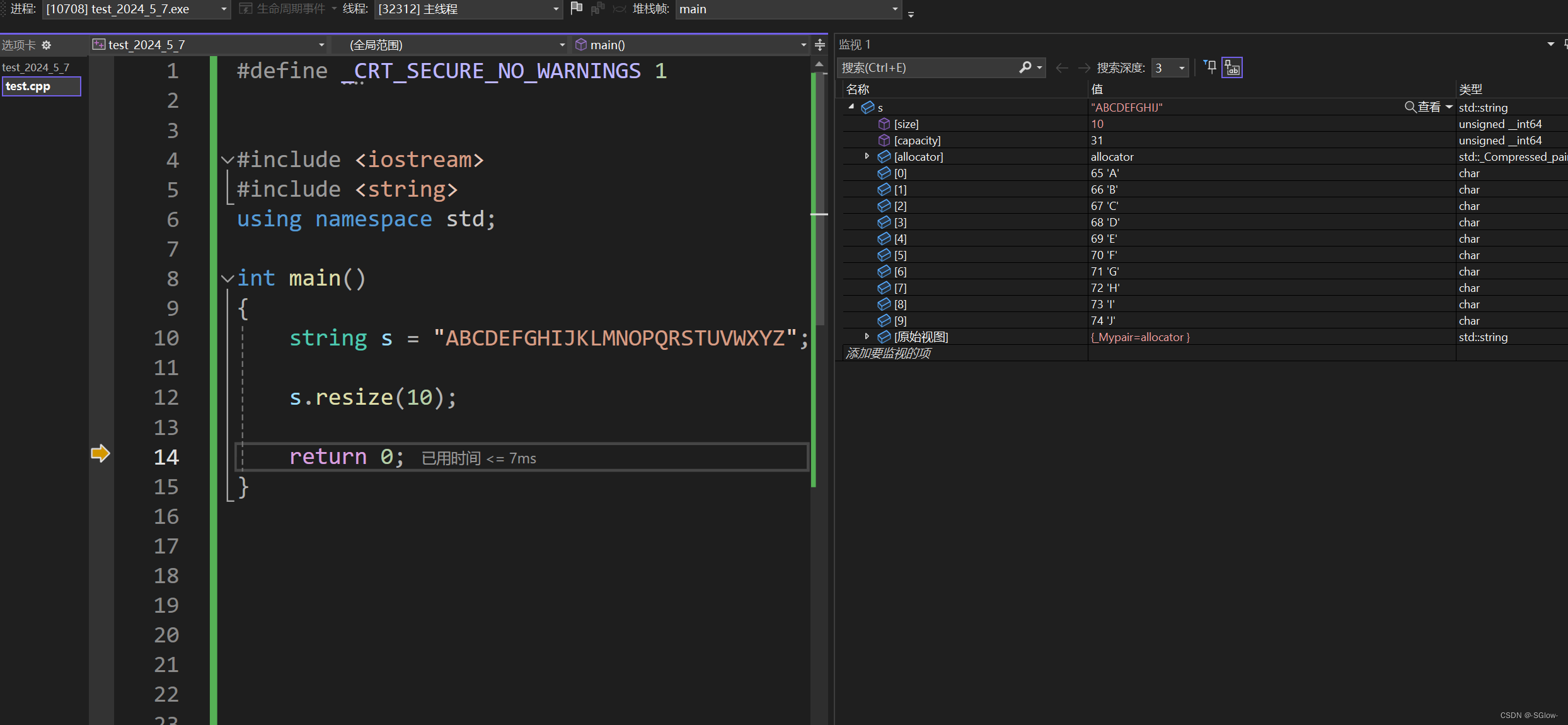
当缩容时,resize后的第二参数没有意义
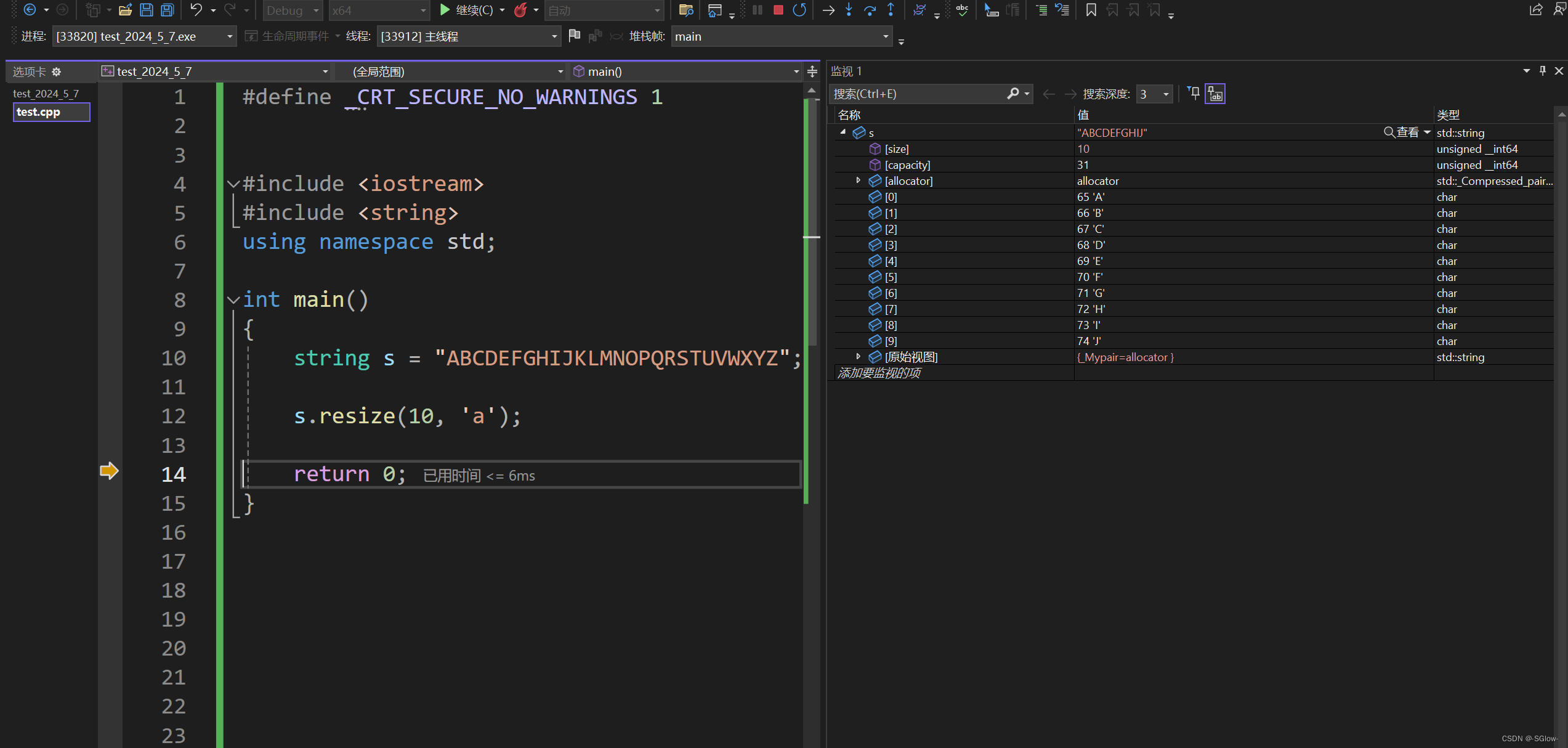
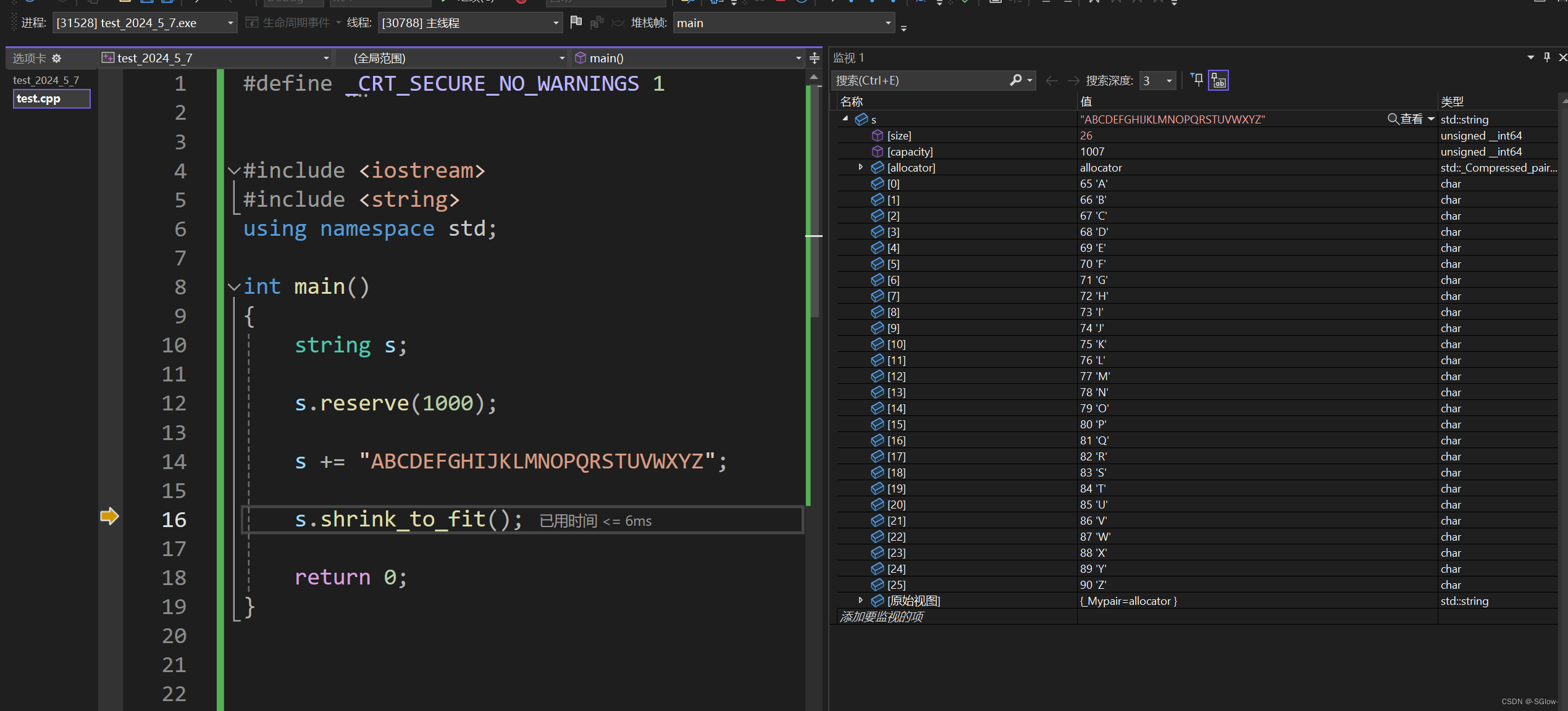
(3)shrink_to_fit
这个函数是将capacity往下减少但不改变原有数据和size,防止空间开辟了太多占着不用。
但是这个函数本质上是用时间换空间,看似只修改了capacity,实际上这还涉及空间的归还,数据挪动,很浪费资源,所以一般不要用。

我们可以在reserve开辟过多的情况下使用shrink_to_fit调整
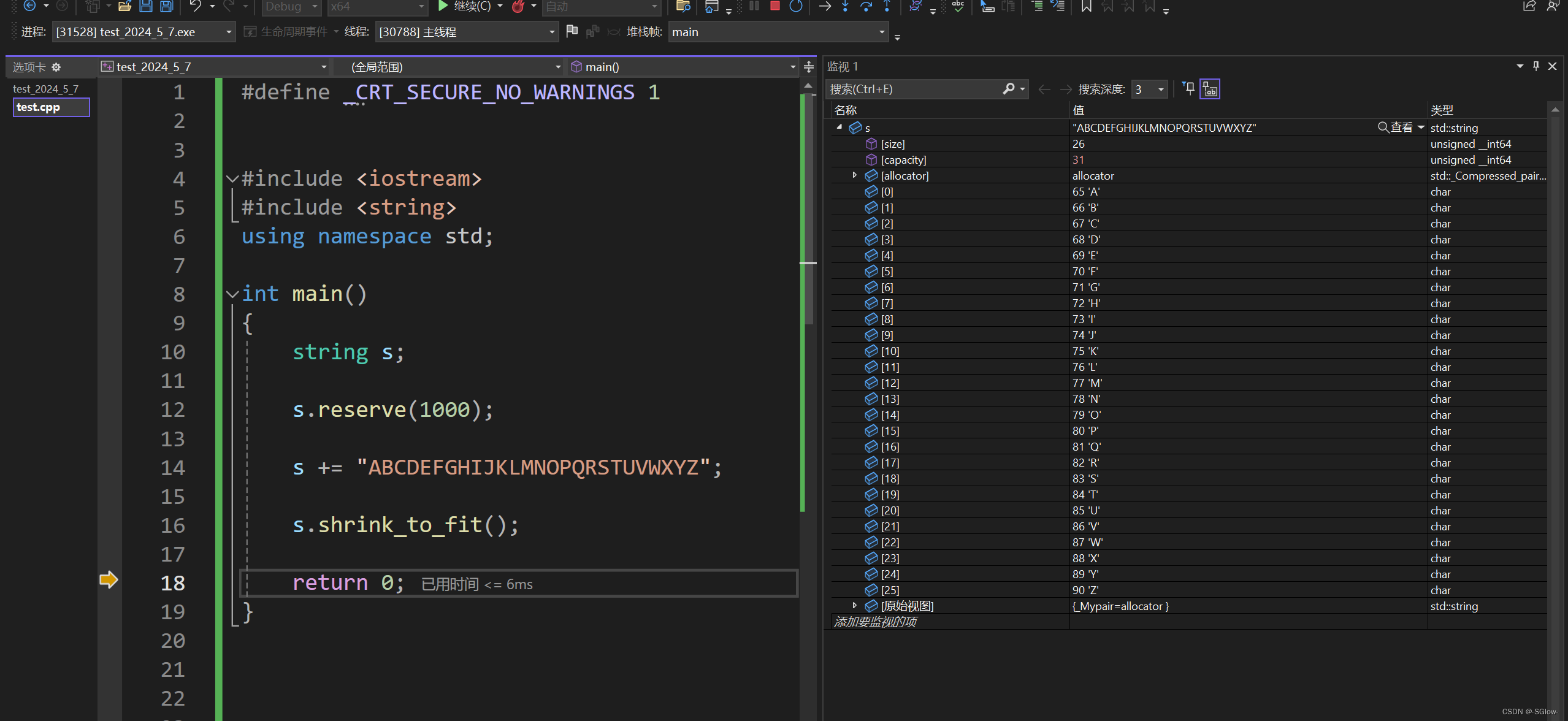
我们还能知道,resize浪费的空间无法通过shrink_to_fit来释放,所以一定要注意resize扩容的操作

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









