






1.memcpy
标准格式:
void * memcpy ( void * destination, const void * source, size_t num );
(1)注意memcpy是无脑复制粘贴的,就算越界访问
(2)复制粘贴的区域不要有重复的,否则会出现数据错误,一般情况下建议使用memmove,你大可以将memcpy想象成低级的memmove
下面是memcpy的模拟实现:
#include <stdio.h>
#include <assert.h>
void* my_memcpy(void* arr2, const void* arr1, size_t num)
{
assert(arr1 && arr2);
void* ret = arr2;
while (num--)
{
*((char*)arr2)++ = *((char*)arr1)++;
}
return ret;
}
int main()
{
char arr1[] = "Hello,world!";
char arr2[20] = { 0 };
printf("%s\n",(char*)my_memcpy(arr2, arr1, 11));
return 0;
}
2.memmove
标准格式:void * memmove ( void * destination, const void * source, size_t num );
(1)在一般情况下,可以将memmove视作更为强大的memcpy,memmove可以复制重合的内容,所以一般情况下避免使用memcpy
相关代码的实现如下:
#include <stdio.h>
#include <assert.h>
void* my_memmove(void* arr2, void* arr1, size_t num)
{
assert(arr1 && arr2);
int i = 0;
if (arr2 >= arr1)//源字符串的地址较低,从后侧开始
{
for (i = 1; i <= num; i++)
{
*((char*)arr2 + num - i) = *((char*)arr1 + num - i);
}
}
else
{
for (i = 0; i < num; i++)
{
*((char*)arr2 + i) = *((char*)arr1 + i);
}
}
return arr2;
}
int main()
{
char arr[20] = "Hello,world!";
printf((char*)my_memmove(arr + 3, arr, 5));
return 0;
}3.memset
标准格式:void* memset(void* ptr, int value, size_t num);
实现代码如下:
#include <stdio.h>
#include <assert.h>
void* my_memset(void* arr, int i, size_t num)
{
assert(arr);
int m = 0;
for (m = 0; m < num; m++)
{
*((char*)arr + m) = i;
}
return arr;
}
int main()
{
char arr[20] = "Hello,world!";
printf((char*)my_memset(arr, '-', 5));
return 0;
}注意这里的形参虽然接受的是个整形,但字符本质上也是以ASCII码的形式存储的,所以这里能够传入字符,且在赋值时会自动进行类型转换。
4.char与unsigned char
(1)char
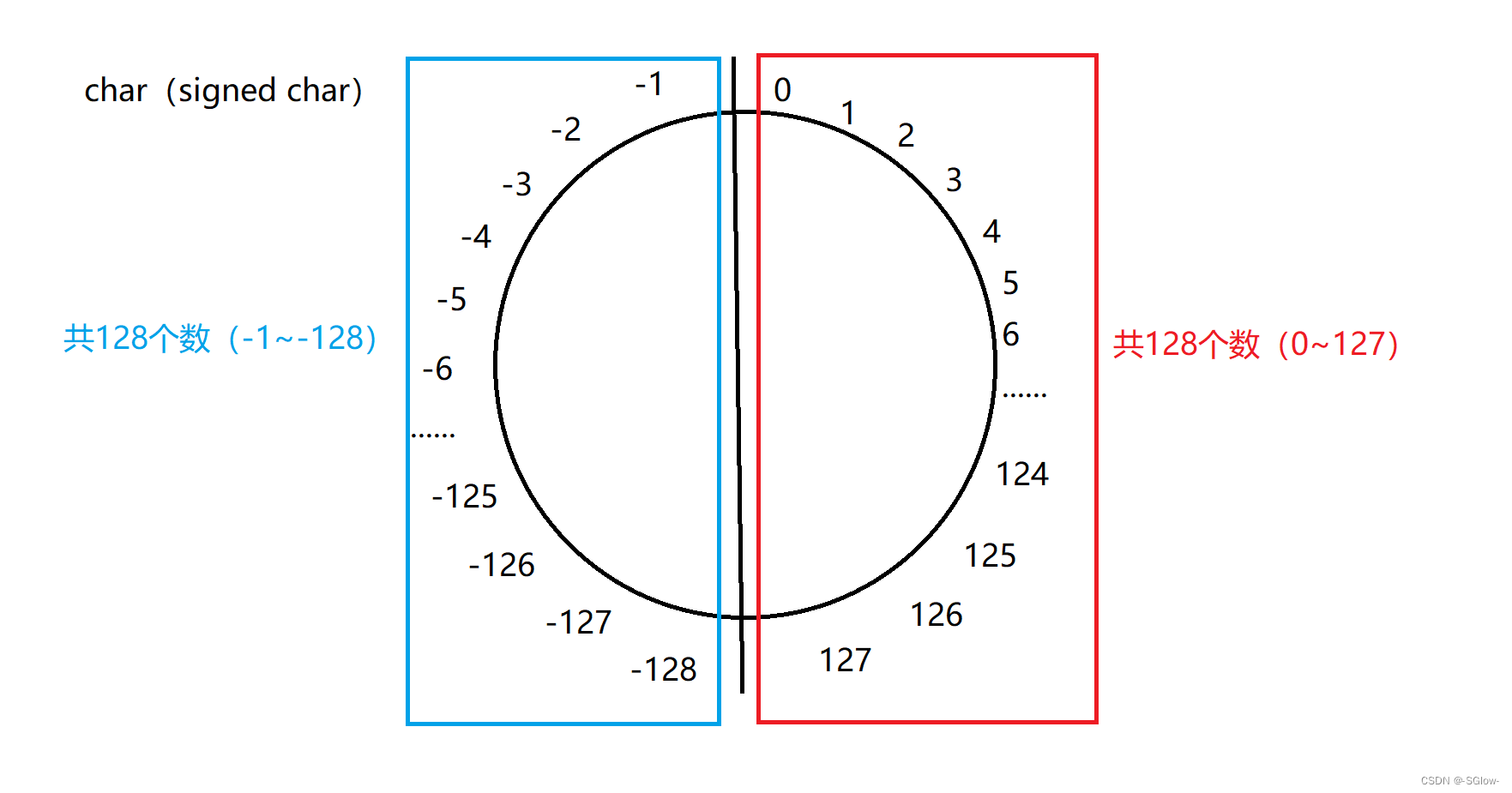
由于char 只有8个bit位的存储空间,所以它最多能表示256个数字(包含0),但在signed char中,由于存在原反补的存储规则,导致01111111是最大的正数,对应过来是127,如果再加,就会是10000000,除符号位按位取反+1得到1 00000000,截断后本应是0,但这和0000000冲突了,也就是说0会出现两次,因此规定在这种情况下,127+1 = -128。再往后+1得10000001,除符号位按位取反得11111110,+1得11111111,对应的就是-127,以此类推。
这样会出现一些案例,如:
#include <stdio.h>
#include <string.h>
int main()
{
char a = 127;
char arr[1000] = { 0 };
int i = 0;
for (i = 0; i < 1000; i++)
{
arr[i] = a + i;
}
printf("%zu\n", strlen(arr));
return 0;
}最终输出的结果是
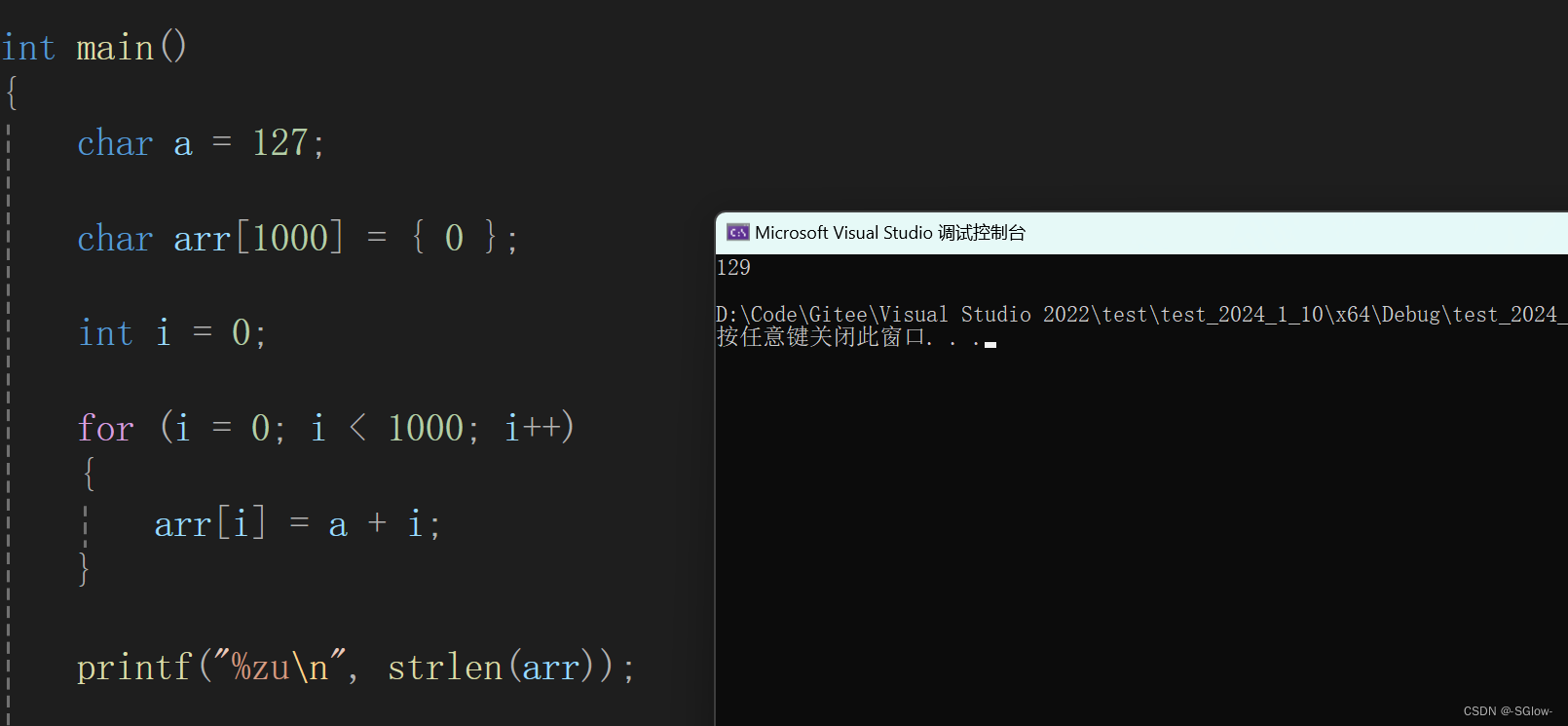
这里实际装进数组的对应字符的ASCII码值是127,-128,-127......-1,0,.....
实际识别到0(也就是\0)就停止了,因此用strlen识别出的大小是129
(2)unsigned char
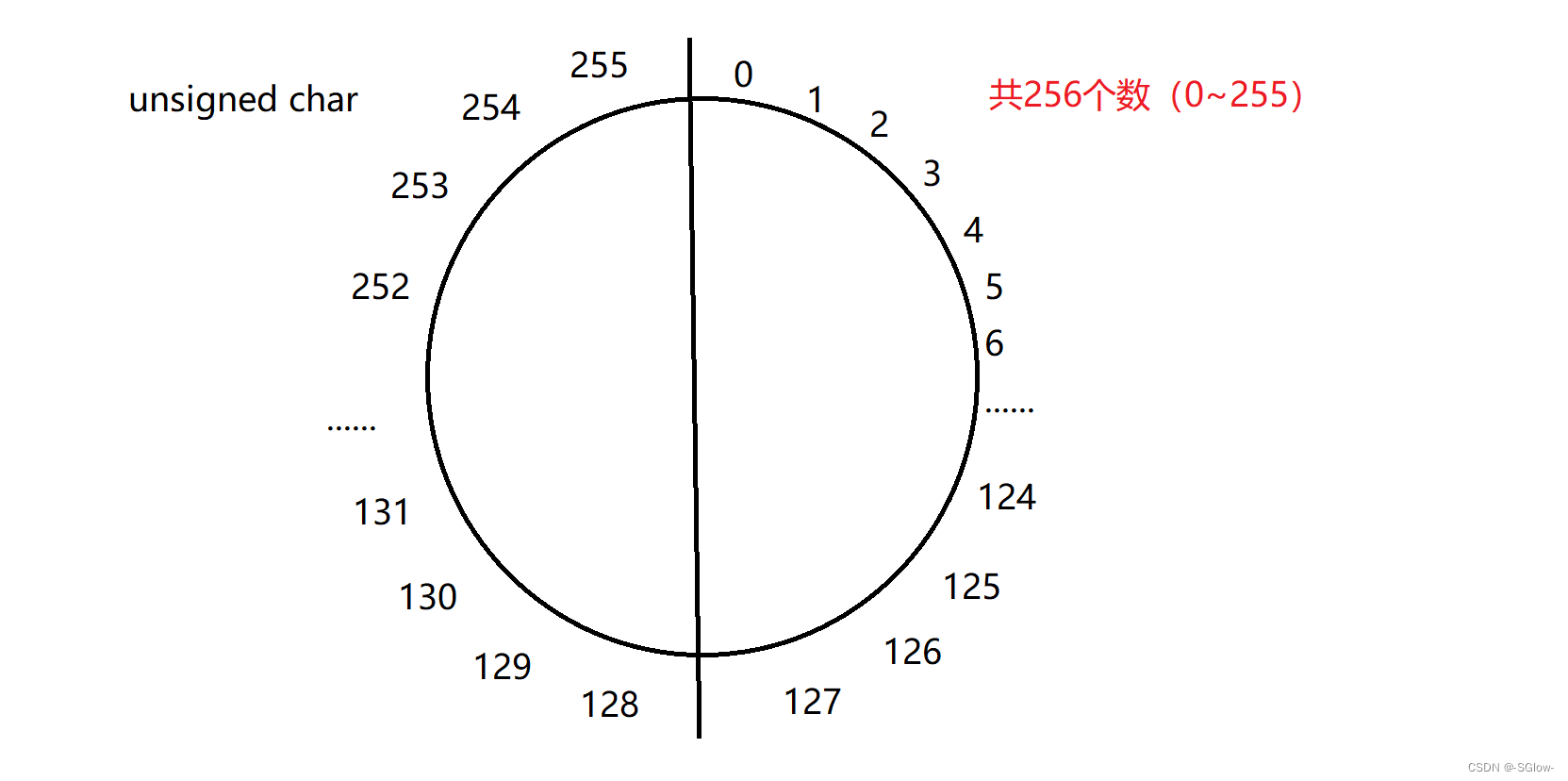
在这里,符号位的概念不复存在,8个bit位都被视作数值位,因此最高可以表255,再+1就会循环。
5.浮点数存储的注意事项:
注意存储的顺序分别是:浮点数的符号(0为正,1为负),指数位(无符号型),有效数字
(1)指数位:注意这是以二进制存储,底数为2,指数位会加上一个中间值来保证不会出现负数指数的情况,因此要主动换算一次才能得到真实的指数位
(2)有效数字,一般情况下,科学计数法的有效数字都是1.xxxx形式,所以自动忽略1,回算时再主动添加上去,但如果指数位全为0,回算时加0,这代表无穷小,也就是0。如果指数位全为1,表正负无穷大
(3)对于32位浮点数,1bit给符号位,8bit给指数位(中间值127),其余23bit给有效数字
对于64位浮点数,1bit给符号位,11bit给符号位(中间值1023),其余52bit给有效数字
(4)一般自己书写时的逻辑是符号位,有效数字,指数位。但存储顺序不一样,这点要注意!
6.结构体,联合体,枚举变量,柔性数组的用法
这四个知识点比较简单,这里用作复习
下面看一段代码:
#include <stdio.h>
#include <stdlib.h>
#include <assert.h>
enum sex
{
male,
female,
secret
};
struct S
{
union m
{
int i;
char name[20];
char id[30];
};
enum sex j;
int arr[0];
};
int main()
{
int m = 0;
printf("结构体的大小是%zu\n", sizeof(struct S));
printf("联合体的大小%zu\n", sizeof(union m));
struct S* s = (struct S*)malloc(sizeof(struct S) + sizeof(int) * 10);
assert(s);
s->i = 20;
s->j = male;
for (m = 0; m < 10; m++)
{
s->arr[m] = m;
}
for (m = 0; m < 10; m++)
{
printf("%d ", s->arr[m]);
}
free(s);
s = NULL;
return 0;
}注意事项:(1)结构体可以和union等嵌套使用
(2)enum的成员列表中的成员之间用','(逗号)隔开
(3)malloc要和free和NULL联合使用,避免内存泄漏,野指针的情况发生
(4)s->arr这种操作在语法上不被允许,只允许对arr[0]等逐一修改,因此这段代码避免了这种写法
(5)union的大小必须满足是最大对齐数的整数倍,即union也存在对齐现象
(6)柔性数组必须在结构体的最后一个元素,和内存开辟函数结合使用,结构体实质上是在堆上创建空间的
7.流
流是将程序和输入输出设备联系起来的媒介,输入设备比如键盘、数据文件(包含文本文件和二进制文件)等,输出设备比如控制台、数据文件等。
我们平时使用的scanf就是将键盘上的内容输入到流里,再通过流(FILE* stdin)读到程序中
printf就是将程序中的内容写到流(FILE* stdout)里,再通过相应操作打印到控制台的屏幕上。
我们不需要关注流与输入输出设备之间的联系方式,只需关注我们要从流中得到什么信息和输入什么信息到流中。
C语言在程序运行时会默认打开stdin,stdout,stderr,我们日常所用的printf,scanf,gets等都是我们和流进行交互,只是C语言底层帮我们实现了很多东西,所以我们之前没有感知。
流是一种文件指针,文件指针实质上是一种结构体指针的重命名,它们指向的结构体包含了对应输入或输出设备的信息,比如stdin这个结构体就包含了键盘的一些信息,也包含了键盘和程序进行沟通的信息等。
流可以以指针的形式对对应结构体进行操作,从而实现对输入输出设备的操作。这部分不需要关心,这是在C语言底层实现的。
这个概念的理解帮助我们对文件操作和程序运行逻辑的理解。
8.fprintf,sprintf和fscanf,sscanf的理解和使用
(1)fprintf 和 fscanf
这里就是必须要在理解流的概念之后才会理解这个函数。
fprintf,fscanf只有第一次参数多了一个FILE*的变量,也叫流的种类,这两个函数适用于任何流,同样的还有fgets,fputs,fgetc,fputc
fscanf会根据不同的流将对应设备中的数据读到程序中,这里stdin对应的设备是键盘
fprintf会根据不同的流将数据写到流对应的设备中,在这里stdout对应的设备是控制台的屏幕
(2)sprintf 和 sscanf
用通俗的话来说,sprintf是将格式化的数据打印成字符串,sscanf是将字符串中的数据提出来,变成格式化的数据,这样有助于理解
sprintf必须加上“打印”成字符串后保存该字符串的首元素地址
sscanf必须加上“提取”格式化数据所对应字符串的首元素地址
下面来看一组代码加强理解:
#include <stdio.h>
#include <stdlib.h>
enum sex
{
male,
female,
secret,
};
struct Stu
{
char name[20];
int age;
enum sex s;
}s1;
int main()
{
char arr[100] = { 0 };
char inf[30] = "Lihua 18 male";
sscanf(inf, "%s %d %d", s1.name, &(s1.age), &(s1.s));
fprintf(stdout, "%s %d %d\n", s1.name, s1.age, s1.s);
sprintf(arr, "%s %d %d", s1.name, s1.age, s1.s);
fprintf(stdout, arr);
return 0;
}运行的结果是
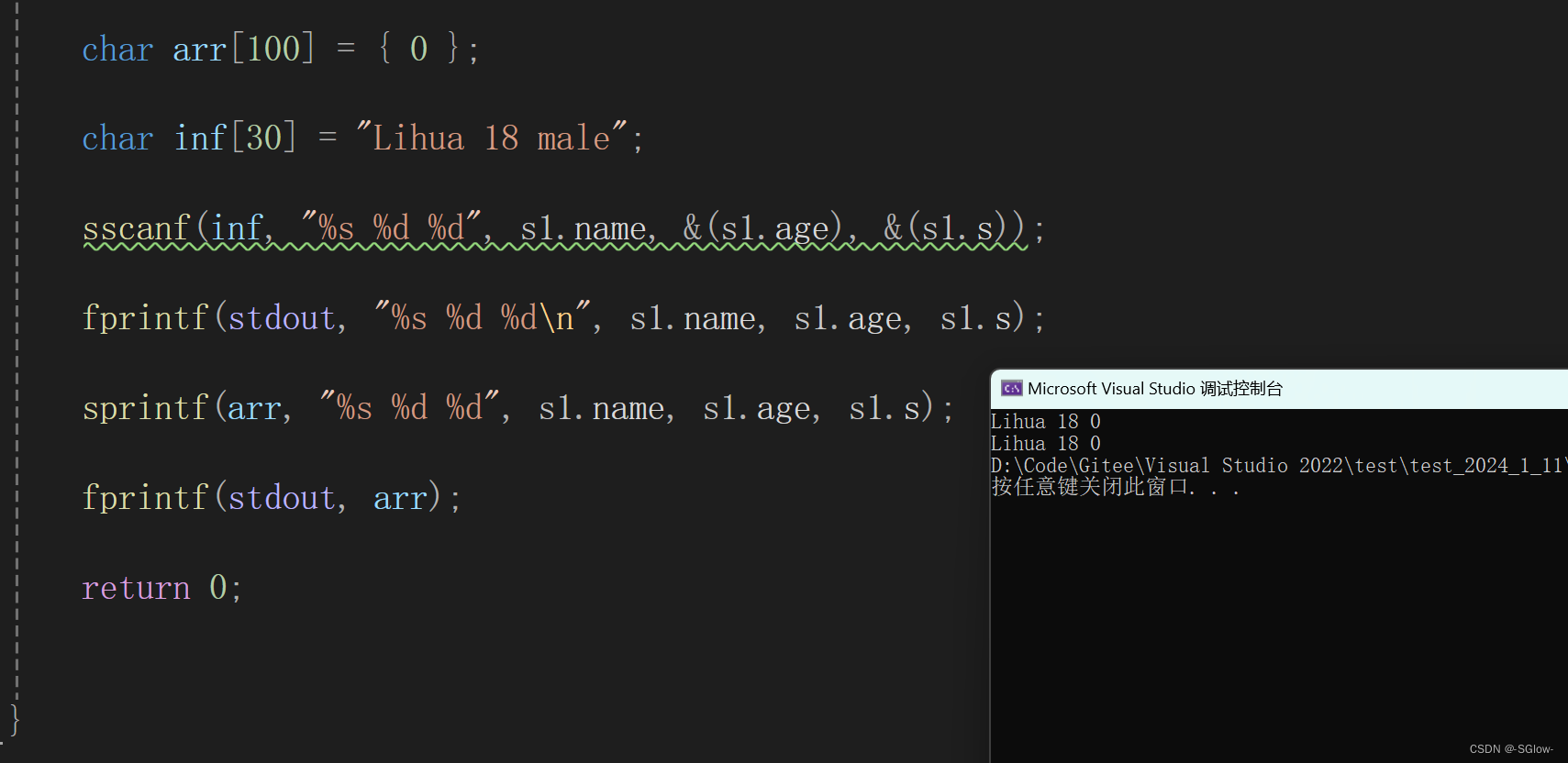
这里的逻辑就是将一串字符提取成格式化数据后,打印该格式化数据;再从格式化数据打印到另一个字符串中,最后再打印这个字符串。
值得注意的是,enum赋值时必须按照其成员的名字命名,而不能是数字,虽然在这里0代表male,但赋值的时候必须以male的输入方式赋值。
9.文件操作中常见的函数
这几个函数在文件操作里面比较常见,但其实比较简单,下面通过代码了解它们的用法:
#include <stdio.h>
#include <errno.h>
#include <stdlib.h>
int main()
{
char arr[20] = { 0 };
FILE* pf = fopen("./data.txt", "w+");
if (!pf)
{
perror("fopen");
return EXIT_FAILURE;//1,需要<stdlib.h>
}
fputc('H', pf);
fputs("ello,world!", pf);
fseek(pf, 0, SEEK_END);
int sz = (int)ftell(pf);//long int类型
printf("文件内容大小是%d\n", sz);
rewind(pf);
arr[0] = fgetc(pf);//返回的是拷贝的字符的ASCII码值,返回int
fgets(arr + 1, sz, pf);//get的个数是sz-1,最后有\0
printf(arr);
fclose(pf);
pf = NULL;
return 0;
}
(1)还有fprintf 和 fscanf也比较常见,但上面一条已经讲解,所以这里不再举例,只需要把首个参数从stdin或stdout换成文件操作流即可
(2)rewind(pf)是还原打开文件后光标的起始位置。当然, 也可以用 fseek(pf, 0, SEEK_SET)代替。而ftell是用来告诉此刻光标的偏移量的,这三个函数通常相互配合使用。
(3)fputc标准格式:int fputc ( int character, FILE * stream );
fputs标准格式:int fputs ( const char * str, FILE * stream );
fgetc标准格式:int fgetc ( FILE * stream );
fgets标准格式:char * fgets ( char * str, int num, FILE * stream );
还有两个二进制文件操作相关的函数:
fread标准格式:size_t fread ( void * ptr, size_t size, size_t count, FILE * stream );
fwrite标准格式:size_t fwrite ( const void * ptr, size_t size, size_t count, FILE * stream );
这里要从右向左读:在stream这个流里,对count个size大小的数据进行读(写)操作。
这些函数都很容易理解,主要是注意参数的位置
(4)创建文件时前缀./表示在当前目录,./../表示在上级目录(../表示上级目录),可以嵌套使用,如./../.././../(但逻辑得自己捋清楚)
注意的是在绝对路径下表示文件地址的是\而不是这里的相对路径的/,两者有细微区别,注意细节
10.文件读取结束后的判断
一般情况下,我们使用feof和ferror来判断读取文件结束后是什么原因
#include <stdio.h>
#include <stdlib.h>
#include <errno.h>
int main()
{
int i = 0;
FILE* pf = fopen("./data.txt", "r");
if (!pf)
{
perror("fopen");
return EXIT_FAILURE;
}
fprintf(pf, "Hola!");
while (fgetc(pf) != EOF);
if (feof(pf))
{
printf("成功读取完数据并退出\n");
}
else if (ferror(pf))
{
printf("读取时遇到了错误导致退出\n");
}
fclose(pf);
pf = NULL;
return 0;
}在调用了一个函数后,文件信息区的信息会被更改,所以使用这两个函数直接传一个参数即可















 1082
1082











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









