#include <iostream>
#include <algorithm>
#include <cstring>
using namespace std;
const int N = 1e5 + 10; // 树最大的节点树是10^5
const int M = 2 * N; // 以有向图的格式存储无向图,所以每个节点至多对应2n-2条边
//也可用vector存,但vector模拟不如数组快
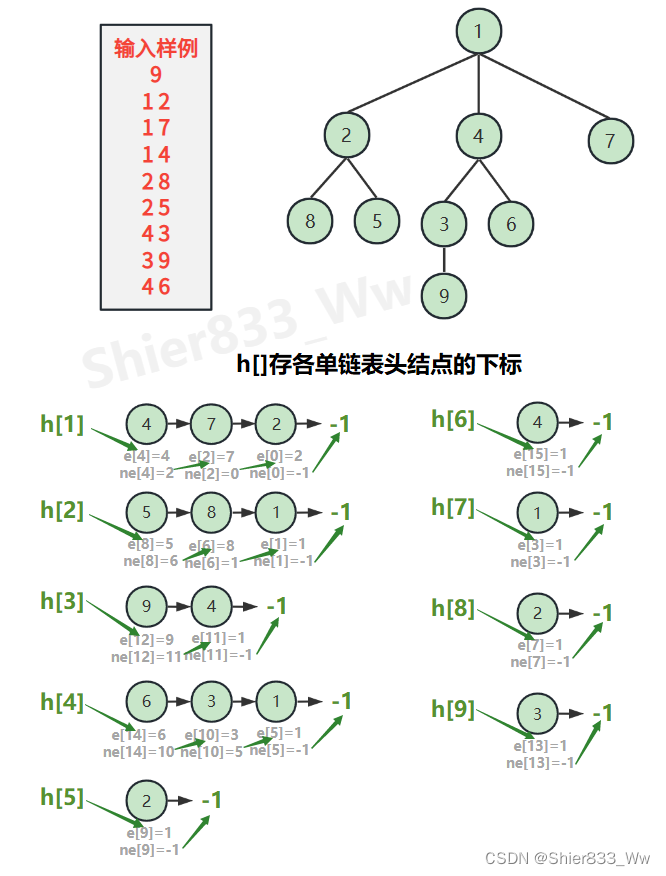
int h[N]; // 邻接表存储树:有n个节点,就需要n个链表的头节点(idx)
int e[M]; // 存储节点自身的值
int ne[M]; // 存储列表的next值(idx)
int idx; // 单链表指针
int n; // 题目所给的输入,n个节点
int ans = N; // 记录重心的最大子树中最小的那个
bool st[N]; //记录1~n个数是否被访问过,访问过则标记为true
//邻接表(几乎所有树和图)都是这么存的
void add(int a, int b) //表a→b
{
e[idx] = b, ne[idx] = h[a], h[a] = idx++;
}
//返回以u为根的子树里的节点总数(包括u节点)
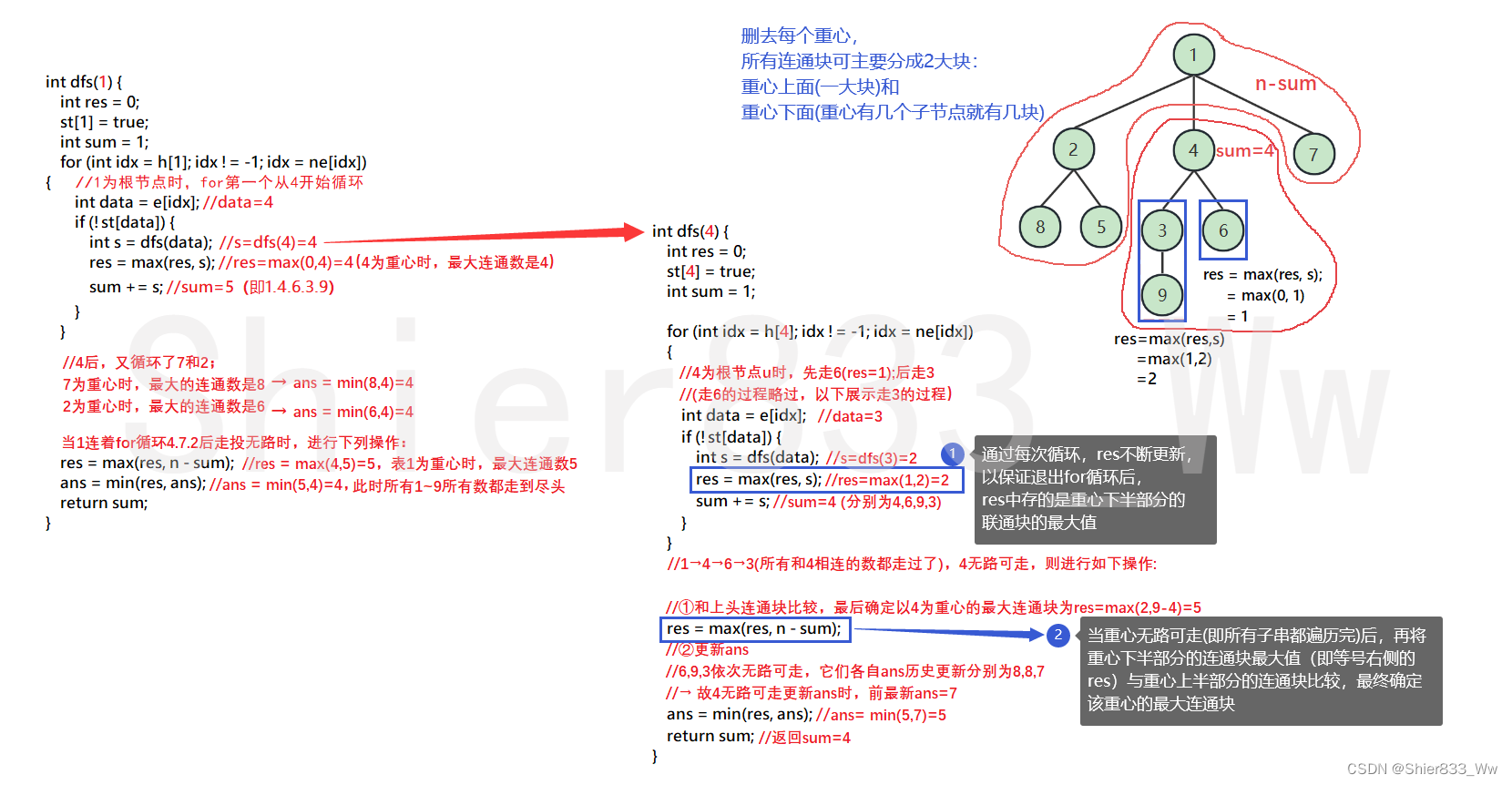
int dfs(int u) {
int res = 0; //存储:删掉重心后,最大的连通块节点数
st[u] = true; //标记是否访问过;
int sum = 1; //存储:以u为根的树节点总数(包括u)
//采用深度优先遍历:访问u的每个子节点
for (int idx = h[u]; idx != -1; idx = ne[idx]) //分析点①
{
int data = e[idx];//data只会为1~n中某个数
if (!st[data]) {
int s = dfs(data); // s记录u节点下某子连通块的节点数
res = max(res, s); // 对比u节点的另一个子连通块,res记录两者最大的
sum += s; //每走完一块子连通块,含u的主连通块sum总数加一块
}
}
//每一个子节点都走投无路时(即所有与它相连的点,st均为true,都不能走时),才会进行如下步骤
res = max(res, n - sum); // 分析点②
ans = min(res, ans); //分析点④
return sum;//分析点③
}
int main() {
memset(h, -1, sizeof h); //初始化h数组,-1表示尾节点
cin >> n; //表示树的结点数
// 本题是无环树:故对于有n个节点的树,必定是n-1条边
for (int i = 0; i < n - 1; i++) {
int a, b;//无向边需要加入两条边
cin >> a >> b;
add(a, b), add(b, a); //无向图
}
dfs(1); //分析点⑤
cout << ans << endl;
return 0;
}
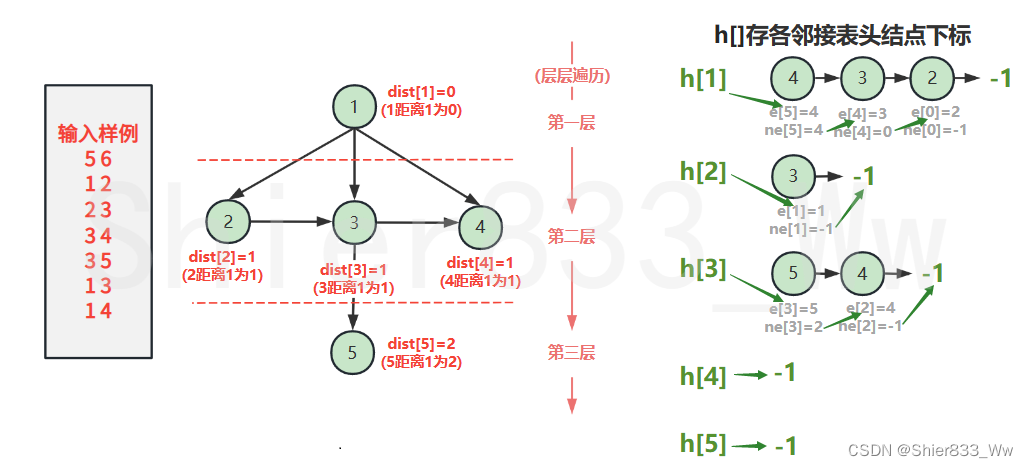
②树与图的遍历:采用BFS(宽度优先遍历)
BFS相似于树的层序遍历
模板
queue<int> q;
st[1] = true; // 表示1号点已经被遍历过
q.push(1);
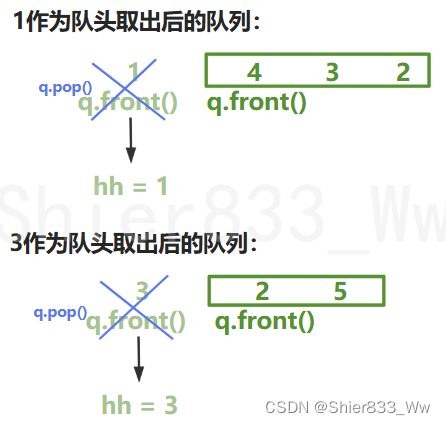
while (q.size())
{
int t = q.front();
q.pop();
for (int i = h[t]; i != -1; i = ne[i])
{
int j = e[i];
if (!st[j])
{
st[j] = true; // 表示点j已经被遍历过
q.push(j);
}
}
}























 464
464











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









