







目录
原文大佬的这篇Doris人群圈选实践有一定的借鉴意义,这里摘抄下来用作学习和知识沉淀。如有侵权,请告知~
前言
随着业务在金融、保险和商城领域的不断扩展,众安保险建设 CDP 平台以提供自动化营销数据支持。早期 CDP 平台依赖于Spark + Impala + Hbase + Nebula 复杂的技术组合,这不仅导致数据分析成为数据孤岛,还带来高昂的管理及维护成本。为了解决该问题,众安保险引入Doris,替换了早期复杂的技术组合,不仅降低了系统的复杂性,打破了数据孤岛,更提升了数据处理的效率。
众安专注于应用新技术重塑保险价值链,围绕健康、数字生活、消费金融、汽车四大生态,业务和关联公司的业务包括:众安保险、众安医疗、众安小贷、众安科技、众安经纪、众安国际、众安银行等。截至 2023 年中,众安服务超过 5 亿用户,累计出具约 574 亿张保单。
然而随着业务在金融、保险和商城领域的不断扩展,众安保险面临用户数据管理的挑战。用户信息来源于公众号、小程序和 APP 等多个渠道,这些数据不仅碎片化,而且多样化。同时,运营渠道也涵盖了自营、联营和外部投放等多种途径,导致数据进一步分散。这种数据孤岛现象使得众安保险难以形成完整的用户融合体系,从而无法实现对用户的精准识别和实时营销。
一、CDP 建设目标及方案
为了解决这一问题,众安保险建设了 CDP 平台。该平台的核心职责是整合所有用户数据,构建全面的用户标签和客群体系,并利用其强大的数据分析能力为自动化营销提供数据支持。

CDP 平台的建设目标主要包括以下几点:
- 快速数据集成:CDP需支持集成常见的关系型数据库(例如Mysql、PG等)和数据仓库(如 Hive、MaxCompute 等),同时还需要整合实时数据流(例Kafka等)
- 精准用户识别:在复杂的业务体系中,CDP 平台需能够灵活整合多种 ID 类型,形成统一的用户视图,为下游的实时营销场景提供支撑。
- 灵活的用户标签和强大的分群能力:这是CDP 平台的核心建设目标,旨在提供全面、深度的用户洞察,精准满足用户需求。
- 多维度实时分析:支持对用户画像,用户旅程和营销效果的实时跟踪和回收。为优化营销策略和提升用户参与度提供有力的支持。
基于上述建设目标,众安保险目前已形成了完整的 CDP解决方案,该方案包括以下几个关键步骤:

- 1.全域数据采集:CDP平台通过实时和离线数据采集方式,实现对全域数据的整合。利用Flink进行实时数据采集,同时建设离线数仓以整合多渠道数据,以确保高质量的数据资产沉淀。
- 2.用户数据融合:通过ID Mapping技术,可将现有的用户数据进行融合,打破数据孤岛。即将用户手机、用户身份证、设备指纹、OpenID 等用户身份进行融合,形成统一的用户标识(OneID)。
- 3.标签和客群管理:CDP 平台支持多维度标签的建设,包含用户属性、用户行为、业务交易状态等,同时通过规则客群的圈选能力实力客群的精细划分。
- 4.用户数据分析:基于丰富的用户标签数据,CDP 平台提供用户画像洞察功能,支持实时效果评估和营销漏斗分析。
- 5.用户数据服务:CDP平台提供多维度的数据接口服务能力,包括用户标签,客群,分层和实时事件等,赋能用户全链路智能营销。
二、CDP 平台架构的演进历程
在初步了解了 CDP平台的建设初衷和解决方案之后,将深入挖掘其演进历程,探索它如何逐步蜕变为众安保险统一、高效且不可或缺的核心基础设施。下文将重点分享 CDP平台的建设过程及其在实际生产中的应用实践。
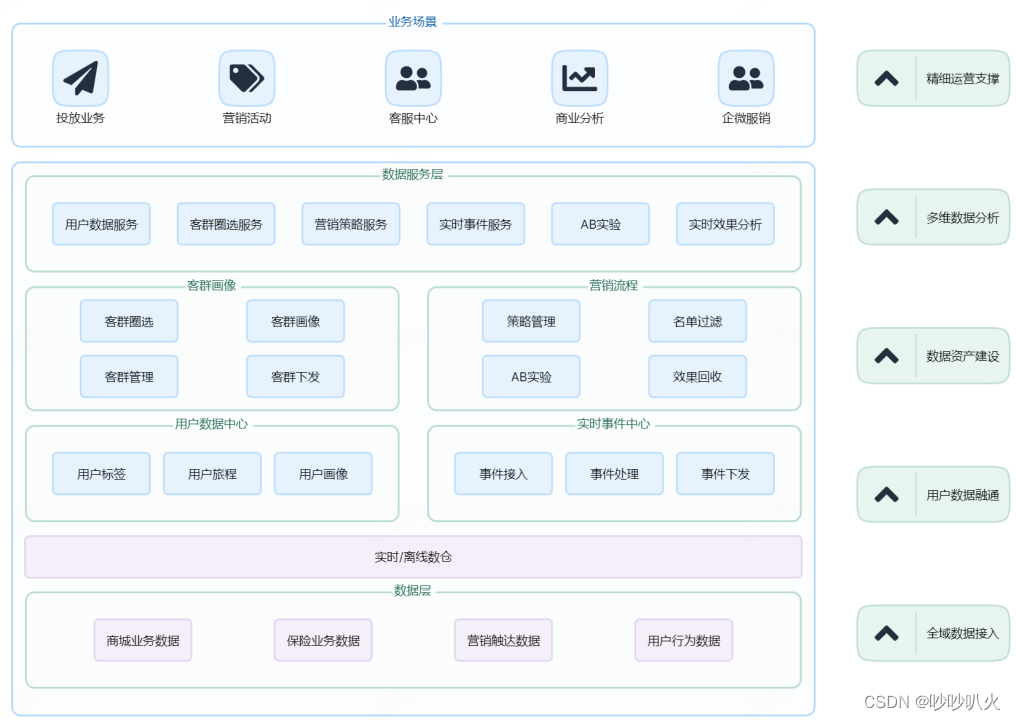
CDP产品架构如上图所示。全域数据接入后,这些数据就可以搭建用户数据中心,实时事件中心、客群画像以及营销流程。用户数据中心是客群画像的基石,并与客群画像、实时事件中心一同支撑营销流程的数据需求。数据服务层则包括用户数据服务、客群圈选、营销策略、实时事件、 AB 实验和实时效果分析回收在内的全方位数据服务,满足各业务场景的数据需求。
2.1 架构1.0:多个技术栈,形成数据孤岛

CDP 平台架构 1.0 如上图所示,离线数据和实时数据的处理流程如下:
- 离线数据:通过ETL方式集成各业务线的数据库数据,包括行为埋点数据,日志数据等,并将这些数据抽取到数仓DWS层。随后,利用 Spark作业将 DWS 层数据抽取到 Impala中,进行离线的标签计算和客群的圈选。同时还通过Spark抽取 DWS 层业务体系里的用户点边关系,并将其集成到Nebula图数据库中,提供全面的点、边关系计算、边距计算以及One ID计算功能。
- 实时数据:采用kafka实时回收所有的业务线的Binlog数据,行为埋点数据以及各业务线的事件上报数据,在 Flink中实现实时标签的配置化计算,并通过Flink Checkpoint进行复杂的实时指标计算和事件组合。最终将实时标签存储在Hbase中,以便为各业务线提供点查服务。
然而,从架构图中可以明显看出,标签计算和 ID图谱计算这一层涉及了非常多的技术栈,包含Impala、Spark、Nebula 以及 HBase。这些过多的组件导致了离线标签,实时标签以及图数据存储的不统一,各场景数据分散存储,形成了数据孤岛。
在这种场景下,当需进行整体视图计算或为上层提供服务时,就需要打通所有的数据,这无疑增加了大量数据传输及数据重复存储的成本。此外,此外,由于各类数据存储方案的差异,还需要使用较大的CDH集群和Nebula图数据库集群,进一步提高了集群资源和维护成本。
2.2 架构2.0:统一技术栈,打破数据孤岛
为了解决数据存储的不一致性和高昂成本等问题,决定进行架构升级,并选择Doris 作为核心组件。升级目标是希望通过引入 Doris 来统一技术栈,实现实时和离线数据存储和计算的整合,从而打破数据孤岛,大幅度降低数据存储和资源维护的成本。在实际的应用中,Doris 完美地满足了需求,使得整体架构变得更精简高效。
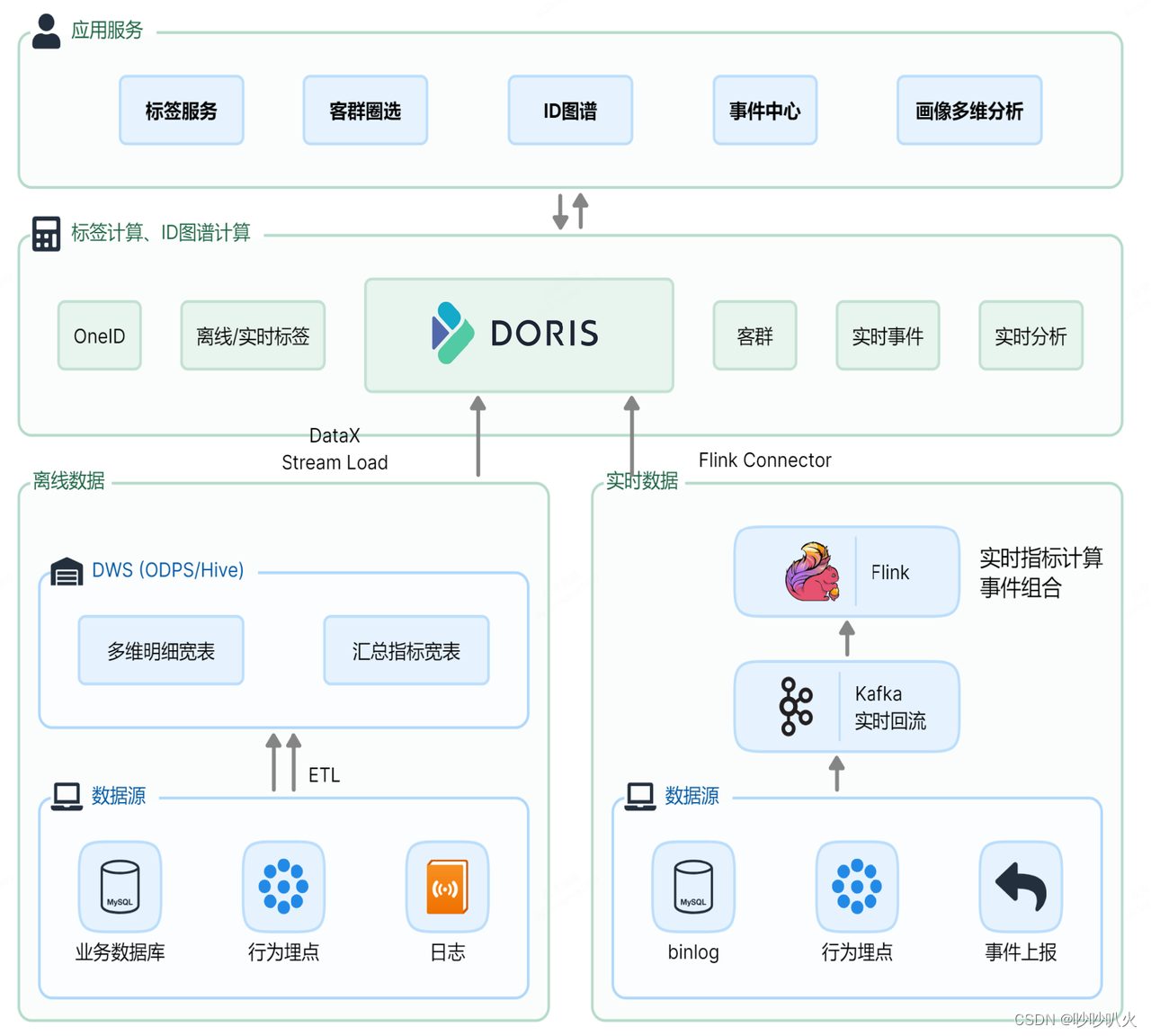
对于离线数据,采用了Doris的Stream Load 功能,可以从离线数仓中将数据抽取到 Doris 中。而对于实时数据,则通过Flink Connector 与 Stream Load 的结合,将实时事件和实时标签无缝导入到Doris 中。基于Doris强大的向量化计算引擎,不仅实现了One ID 计算、离线/实时标签的存储和计算,客群圈选,实时事件存储,还支持了实时分析等多样化需求,真正实现了技术栈的统一。引入 Doris 后,我们还收获了以下显著的收益:
- 架构简洁,运维成本降低:引入 Doris 之前,需要额外维护 CDH 集群和 Nebula 集群。而现在,仅凭一个 Doris 集群就可以完成所有的工作,显著降低运维成本。此外,Doris 还提供的完善集群监控设施也极大方便了对集群的便捷管理。
- 支持SQL,快速上手: Doris 兼容 MySQL 协议,这意味着对于已经熟悉 MySQL 的开发者来说,无需额外的学习成本就能快速上手操作。
- 丰富的数据导入形式 :Doris 提供了丰富且便捷的数据导入方式,用户可以根据实际需求选择适合的导入方式,以快速完成数据迁移和导入操作。
三、CDP Doris 在业务场景中的实践
3.1 全域数据采集
为满足不同场景的数据集成需求,CDP 平台主要分为三个板块:
- 离线数据导入:针对标签计算、实时客群预估与圈选,以及标签和客群多维画像分析等场景,采用 DataX 工具,通过 Stream Load 方式将离线数据高效写入到 Doris 里。为确保 Stream Load 的稳定性,在线上对30多个线程并发导入进行测试,结果显示,每秒 Upsert (写入或更新) 数量高达 30+ 万条。对于当前的一级用户量来说,导入效果可以很好满足需求。
- 部分列更新:在实时写入场景中,当使用Flink实时写入标签数据时,需要精确到单个用户和标签的实时更新和插入,流程相对复杂。而 Doris Stream Load 可以开启部分列更新 partial_columns=true 来满足这一需求,确保每个用户和标签都能得到及时、准确的更新。
- 外部数据源对接:在实时分析报表场景中,经常需要跨多个数据源的交叉分析。Doris 的 Multi-Catalog 功能可以更加方便的对接外部数据目录,无需进行数据迁移或导入,即可进行外部数据源的联邦查询。无论是基于Hive 或 MaxCompute 的查询,还是 JDBC 业务线的数据查询,都能迅速获得精准的分析结果,极大提升了查询效率。
3.2 OneID
3.2.1 构建 ID图谱
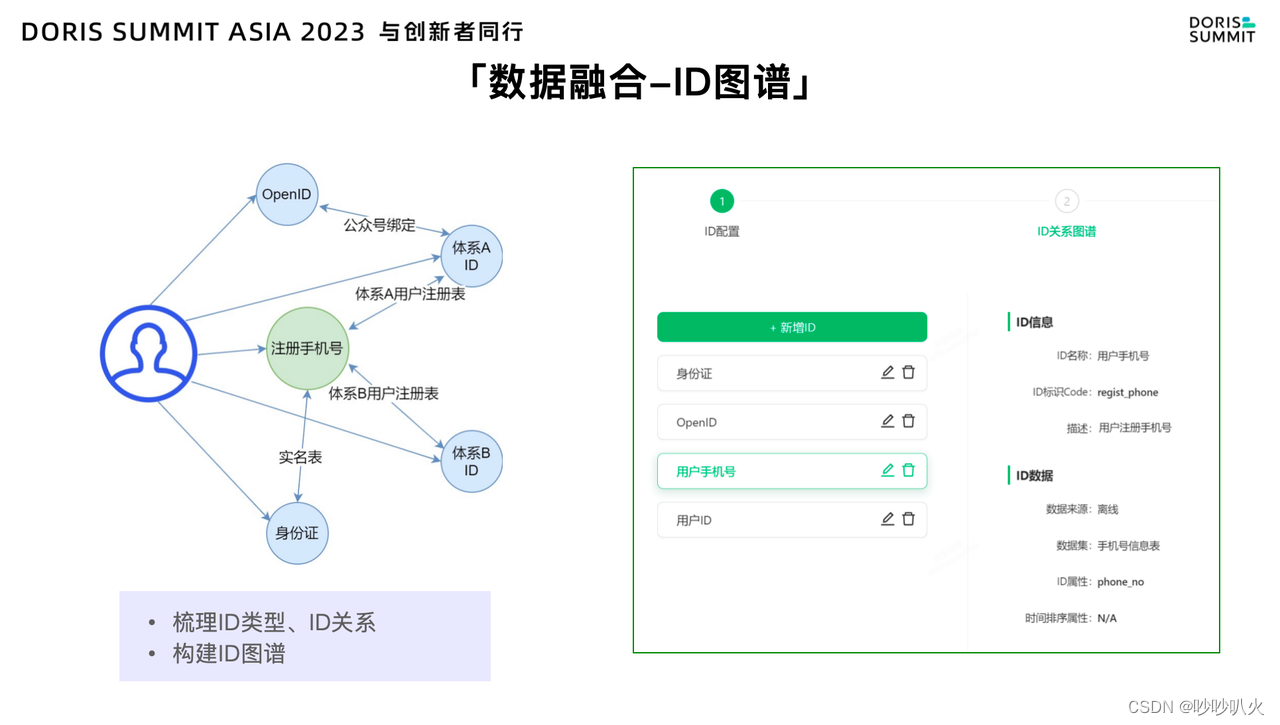
我们在现有系统中配置了ID图谱的点关系,这些关系以用户为中心,形成了复杂的网络结构,举例说明:假设某用户在体系A拥有用户ID,并且绑定的公众号,这样就形成了Open ID绑定关系。随着用户的使用,他可能注册了手机号,那么手机号跟体系A用户ID之间便建立了绑定关系。如果用户在体系A也进行了实名,那么身份证和注册手机号也会建立绑定关系。
随着时间的推移,该用户可能进入到体系B中,并注册体系B账户。这时,与该用户相关的体系 A 用户 ID、手机号、身份证和体系 B 账户之间都会形成关联。在如上图右侧系统中,可以配置用户ID,OpenID,手机号,身份证这些点的属性,物理表及关联关系,形成ID图谱。那么结合ID图谱,就可以基于Doris进行OneID的构建。
3.2.2 构建OneID

基于用户各个业务线之间点和边的关系,会将用户在不用业务线中的信息全部抽取出来,放入一张大表里面进行Union All操作。这张表包含了手机号、体系 A 用户 ID、体系 B 用户 ID、身份证号和 Open ID 关键信息。OneID的构建流程如下:
- 首先,利用Doris提供的row_number窗口函数生成完整的全局行顺序。然后对所有ID关系数据进行 Union All 操作。
- 接着,使用窗口函数
dense rank和row number的复数生成为空/不为空的首列Rank值。 - 最后,通过循环迭代计算每一列最小距离,并不断迭代 Rank 值,直到当前列与上一迭代结果全局匹配。当所有数据连续匹配满 5 次后,就以最终 Rank值为准进行用户分组,从而得用户唯一标识OneID。
结合上图以及构建流程,可以得出结论:1 - 4 行是用户1,5 - 6 行是用户2。
3.3 标签体系
标签体系由实时标签和离线标签两部分组成,目前该体系拥有超过2000个标签,涉及50余张来源表,服务用户量已达亿级。

在标签体系中,有一些简单的配置规则:
- 离线标签:在Doris中抽象出三种业务类型表,分别是用户数据表,业务明细表和行为事件表。根据上方标签配置规则,通过DSL动态语义生成SQL,然后在Doris中进行计算,并将计算结果存储在Doris中,形成了一张离线标签宽表。
- 实时标签:基于Flink接收Kafka,CDC消息,并根据实时标签配置元数据,在Flink中计算出实时标签,并将最终结果写入Doris的实时标签宽表中。

Apache Doris 在标签体系中的应用主要包含以下四个方面:
1.离线标签处理: 由于拥有2000+较大量级的标签一级用户,当遇到高峰期并发宽表写入时,全量更新所有列可能会出现内存不足的问题。为避免该问题,利用 Doris 的 Insert Into Select 功能,在 session 变量中打开部分列更新开关,只更新目标表中需要修改的列,这样可显著减少内存消耗,以提升全量导入的稳定性。
set enable_unique_key_partial_update=true;
insert into tb_label_result(one_id, labelxx)
select one_id, label_value as labelxx
from .....2.实时标签处理: 在实时标签写入时,不同的实时标签字段更新时间不一样,而部分列更新能力可以满足此更新需求。只需打开 Partial Column,并将其设置为 True,就可以实现实时标签的部分列更新。
curl --location-trusted -u root: -H "partial_columns:true" -H "column_separator:," -H "columns:id,balance,last_access_time" -T /tmp/test.csv http://127.0.0.1:48037/api/db1/user_profile/_stream_load3.标签点查:随着线上业务量的不断增长,面临着处理超过5000QPS 标签请求的挑战。为了满足这一需求,采用了多种策略来确保高效的点查性能。首先,通过利用 PrepareStatement 技术,预编译和和执行SDQL查询,从而提高查询效率。其次,精细调整了Backend(BE)参数和表参数,以优化数据存储和查询性能。同时开启了行存,进一步提升系统在高并发场景下的处理能力。
- 在 be.conf 中调整 BE 参数:
disable_storage_row_cache = false
storage_page_cache_limit=40%- 在建表时调整表属性:
enable_unique_key_merge_on_write = true
store_row_column = true
light_schema_change = true4.标签计算:为了满足用户对于标签配置的灵活需求,系统允许在DSL生成的语义中进行多表 Join 操作,而这就可能会涉及十几张表的join操作。为了确保标签计算性能最优,充分运用 Doris Colocation Group 策略,对所有分桶列的类型,数量和副本进行统一,并优先满足 Colocation Join 和本地的 Hash Join。在线上环境中,也可以打开Colocate With开关,指定一个 Group,确保全局表的分片与副本策略一致。
3.4 客群圈选

在架构 1.0 中,客群服务先生成动态 SQL,然后将其传输到 Impala 中进行客群圈选。完成圈选后,结果集需被重新读取回客群服务,并由其上传到对象存储中。这一连串的操作使得数据处理链路相对冗长,影响了整体效率。而在架构2.0中,可以在 Doris 中使用基于 Select 语句的结果集,并通过 Select Into Outfile 功能,将数据无缝导入到 S3 协议的对象存储中,这种方式极大缩短了数据处理链路。
在实际的业务中,线上约有100万个客群,单个客群生成所需时间从 50 秒缩短至10秒,极大提升了客群圈选效率。 若需要进一步提高性能,可以选择打开并发导出开关,进一步提高数据导出性能。
3.5 客群归属
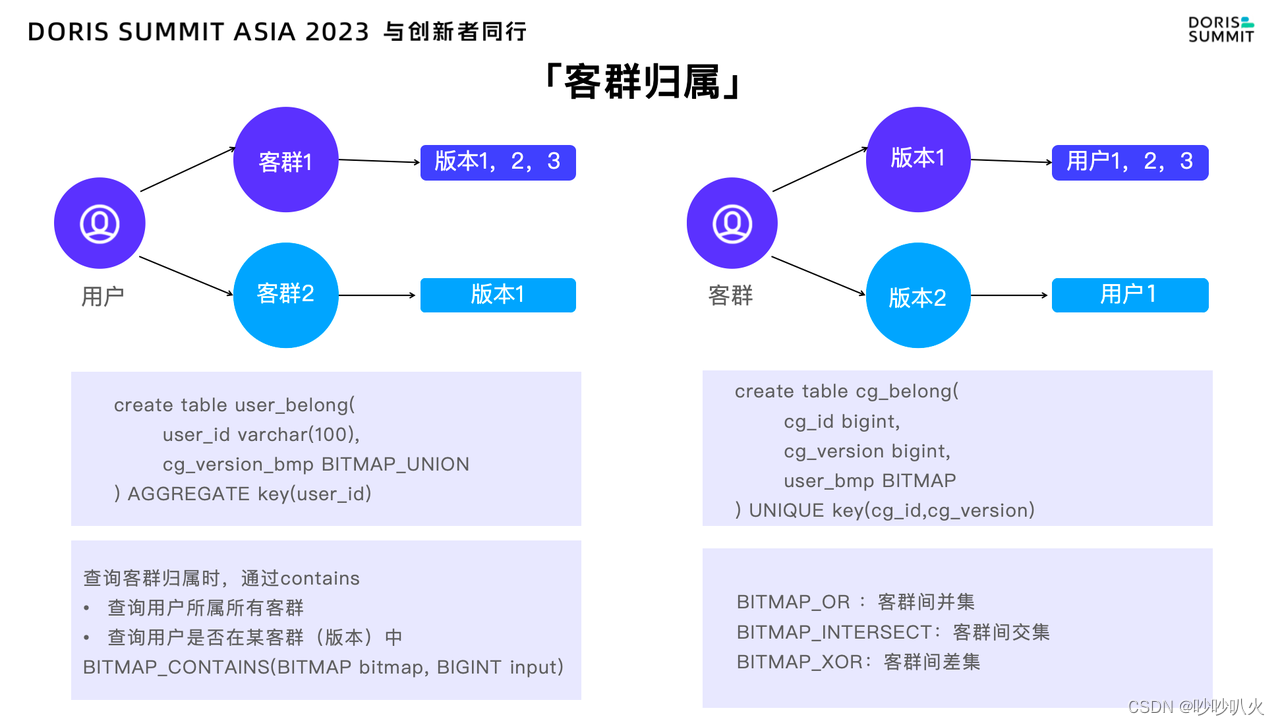
在业务系统中,客群归属扮演着至关重要的角色,特别是在实时智能营销和千人千面的识别场景中。我们经常需要判断某个用户是否隶属于特定的客群,或者确定其属于哪些客群。这种全局性的判断有助于深入理解多个客群之间的用户重叠关系。
为了满足这一需求,可以借助Bitmap 来实现。在 Bitmap 中,使用 Bitmap Contains 可以快速识别某个用户是否存在于特定客群中,也可以通过 Bitmap OR、Bitmap Intersect 或 Bitmap XOR 来实现客群全量、多版本之间的交并叉分析,从而提供更为精准和高效的营销策略。
四、总结与展望
在架构 1.0 中采用了复杂的技术组合,以实现标签、客群以及 OneID 的计算。这一架构组件众多,导致数据处理链路冗长、造成数据孤岛,且有着较高的管理和维护成本。通过引入 Doris ,替换了 Spark + Impala + Hbase + Nebula,成功实现存储与计算的统一,简化了数据处理的流程,不仅降低了系统的复杂性,更提升了数据处理的效率,满足了更丰富的数据处理需求。
随着业务的发展,实时营销场景对实时性的要求日益提升。未来计划在 3.0版本中,实现离线标签和实时标签的混合圈选功能,并依托 Doris 进行 OneID 实时计算。这将使我们能够更快速、准确地识别增量的用户,并在多用户体系中实现精准的用户识别,以满足不断变化的业务需求,推动实时智能营销和个性化识别场景的持续创新与发展。
参考文章:















 1136
1136











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









