







MySQL架构图
连接、服务、引擎、存储
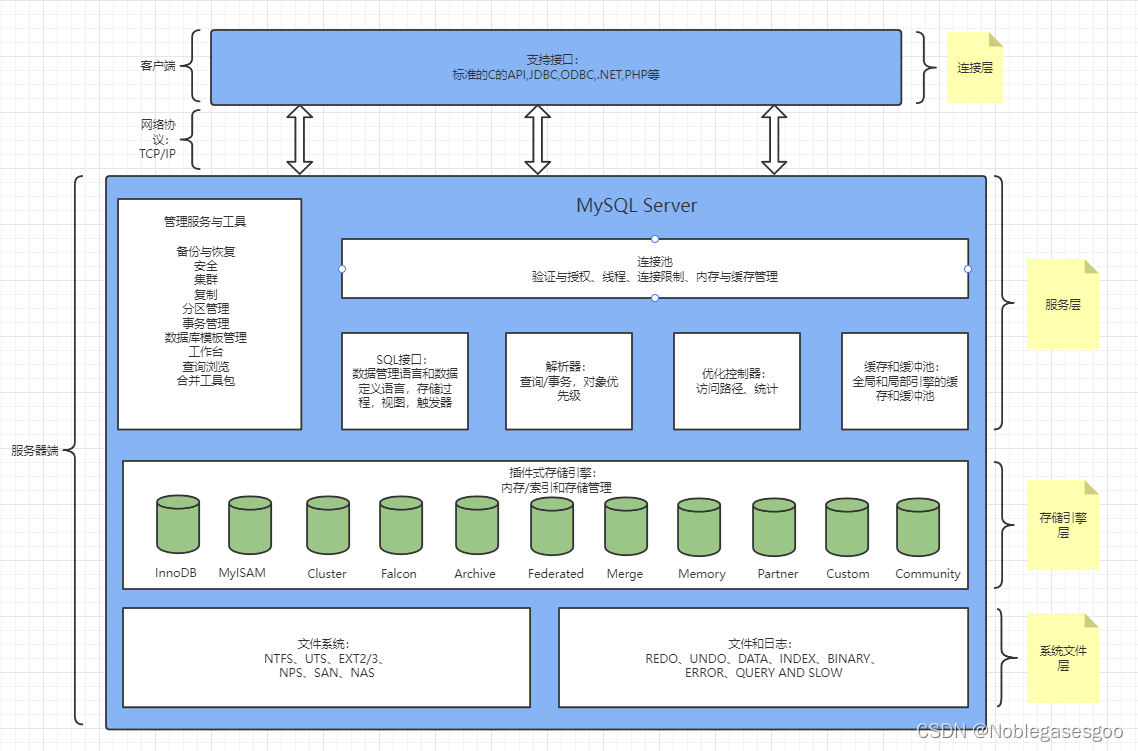
层次结构的介绍
- 连接层 :是MySQL提供了对外界客户端访问的组件,服务端应用程序用自己的API与数据库进行连接。
- 服务层:客户端的请求接到之后,它肯定是有要做的事情的,服务层就是为客户端提供服务支持的。
- 存储引擎层:负责与MySQL中数据存储和提取的,与底层系统文件进行交互。
- 系统文件层:主要负责数据库的数据和日志的存储在系统文件上,并完成与存储引擎的交互,是文件的物理存储层。
服务层模块划分
它包含了对SQL语句处理的全过程。
管理服务与工具
- 主管数据的备份与恢复、复制。
连接池
- 管理连接和权限认证的。
- 管理缓冲用户连接,线程处理等需要缓存需求的。
- 负责监听关于 MySQL Server 的各种请求。
- 最大连接数可用
show variables like max_connections来查看,一般最大默认连接量是 151。
sql接口
- 负责用来接收用户的 SQL 命令,以及数据管理语言和数据定义语言,存储过程,视图,触发器等产生的SQL,并且返回用户需要的查询结果。
- 比如 select from 就是调用 SQL interface。
解析器
- 生成一条完整合法的SQL。
- 解析SQL命令,SQL命令传到解析器的时候会被解析器验证。
- 验证是将一个SQL语句进行语义语法的分析分解成所谓的数据结构,按照不同的操作类型进行分类,做出针对性的转发。
- 如果分析出错,那就说明当前SQL语句不合法。
优化控制器
- SQL语句在查询之前,会使用查询优化器对查询进行优化。
缓存和缓冲池
- 将客户端提交给MySQL的 select 请求的结果集 cache 到内存中。
- 查询时若缓存有命中,就直接从缓存中拿取查询结果。
- 命中率太低了,要求SQL必须完全一样,MySQL5.7已经被关闭,8.0之后完全被下架了。
MySQL在Linux下的基本命令及文件路径
包含服务的启动,停止,状态查看,数据库内容的查看等基本命令。
文件路径
由于是用宝塔面板安装,所以可能会有不一样的地方。
| 路径 | 描述 |
|---|---|
| /www/server/data | mysql数据库的存放路径 |
| /etc/my.cnf | 配置文件目录位置 |
| /www/server/mysql/bin | 相关命令目录 |
| /etc/init.d | 服务启动相关 |
Linux相关的一些指令
# 查看Linux的关于mysql的组
[root@localhost lib]# cat /etc/group|grep mysql
mysql:x:1002:
# 查看Linux的关于mysql的组的用户
[root@localhost lib]# cat /etc/passwd|grep mysql
mysql:x:1002:1002::/home/mysql:/sbin/nologin
查看有没有安装MySQL服务
# 查看有没有安装MySQL服务
[root@localhost lib]# rpm -qa|grep -i mysql
# 查看mysql安装目录
[root@localhost lib]# ps -ef|grep mysql
服务的停止与启动
# 服务启动
service mysqld start
# 服务停止
service mysqld stop
# 查看服务状态
service mysqld status
# 设置开机自动启动服务
chkconfig mysqlid on
# 查看设置状态,2、3、4都为on则开启开机自动启动
chkconfig --list | grep mysqlid
# centos7下运用它
systemctl enable mysqld.service
查找MySQL配置文件
# 运用宝塔面板装的mysql配置文件在 /etc/my.cnf
[root@localhost /]# find / -name my.cnf
/etc/my.cnf
/www/server/mysql/mysql-test/suite/federated/my.cnf
/www/server/mysql/mysql-test/suite/group_replication/my.cnf
/www/server/mysql/mysql-test/suite/ndb/my.cnf
/www/server/mysql/mysql-test/suite/ndb_big/my.cnf
/www/server/mysql/mysql-test/suite/ndb_binlog/my.cnf
/www/server/mysql/mysql-test/suite/ndb_ddl/my.cnf
/www/server/mysql/mysql-test/suite/ndb_memcache/my.cnf
/www/server/mysql/mysql-test/suite/ndb_rpl/my.cnf
/www/server/mysql/mysql-test/suite/ndb_team/my.cnf
/www/server/mysql/mysql-test/suite/ndbcluster/my.cnf
/www/server/mysql/mysql-test/suite/rpl/extension/bhs/my.cnf
/www/server/mysql/mysql-test/suite/rpl/my.cnf
/www/server/mysql/mysql-test/suite/rpl_ndb/my.cnf
修改字符集
建议安装完成 mysql 之后就设置
# 查看字符集
show variables like 'character%';
show variables like '%char%';
# 找到指定配置文件并打开
[root@localhost ~]# cd /etc
[root@localhost etc]# ls -i my.cnf
19620831 my.cnf
[root@localhost etc]# vim my.cnf
1 [client]
2 #password = your_password
3 port = 3306
4 socket = /tmp/mysql.sock
5 default-character-set=utf8 # 新添加的字符集设置
7 [mysqld]
8 port = 3306
9 character_set_server=utf8 # 新添加的字符集设置
10 character_set_client=utf8 # 新添加的字符集设置
11 collation-server=utf8_general_ci # 新添加的字符集设置
12 socket = /tmp/mysql.sock
13 datadir = /www/server/data
14 default_storage_engine = InnoDB
15 performance_schema_max_table_instances = 400
16 table_definition_cache = 400
17 skip-external-locking
18 key_buffer_size = 32M
19 max_allowed_packet = 100G
20 table_open_cache = 128
21 sort_buffer_size = 768K # 排序缓冲池大小,长难句统计排序,这里适当调大
22 net_buffer_length = 4K
23 read_buffer_size = 768K
24 read_rnd_buffer_size = 256K
25 myisam_sort_buffer_size = 8M
26 thread_cache_size = 16 # 线程缓冲池大小
27 query_cache_size = 16M # 查询缓冲池大小
28 tmp_table_size = 32M
29 sql-mode=NO_ENGINE_SUBSTITUTION,STRICT_TRANS_TABLES
...
64 [mysql]
65 no-auto-rehash # 是否开启自动补全
66 default-character-set=utf8 # 新添加的字符集设置
...
查看当前数据库的本地文件
[root@localhost data]# cd db01/
[root@localhost db01]# ll
total 112
-rw-r-----. 1 mysql mysql 67 Nov 25 16:27 db.opt
-rw-r-----. 1 mysql mysql 8586 Nov 25 16:28 user01.frm # 表结构文件,用于数据库迁移
-rw-r-----. 1 mysql mysql 98304 Nov 25 16:29 user01.ibd # 5.7之后默认InnoDB
一条语句的查询过程
用来做参考的sql语句:
SELECT customer_id,first_name,last_name FROM customer WHERE customer_id = 14;
流程图示
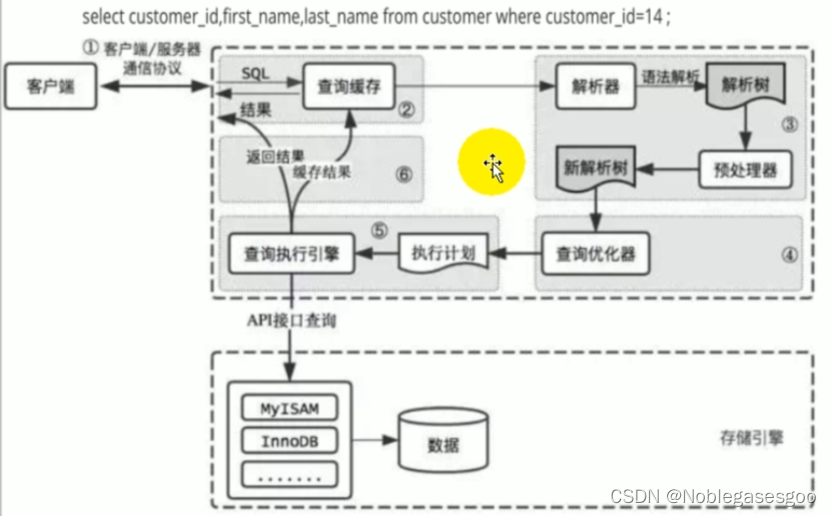
- 客户端像 MySQL 服务器发送一条查询请求。
- 服务器首先检查查询缓存,如果命中缓存就立即返回缓存中的结果,否则进入下一阶段。
- 服务器进行SQL解析,预处理,再由优化器生成对应的执行计划。
- MySQL 根据执行计划,调用存储引擎的 API 来进行查询。
- 将结果返回给客户端,同时缓存查询结果。
建立连接
通过客户端携带正确的参数(主机,用户名,密码等信息)对数据库服务器建立连接,数据库的连接层一直会处于监听状态,如果建立连接之后,首先判断查询语句是否满足缓存中的数据,是的话直接返回缓存中的数据给客户端,否则就走下一步。
查询缓存阶段
对于我们的MySQL会将缓存存在一个引用表中,可以理解为一个HashMap的结构,通过计算关于版本号,sql语句内容之类的东西来进行比对,也就是说多一个空格都不行,所以缓存的命中概率极低。
解析器阶段
没有命中缓存的话进入解析器阶段,主要这个阶段就是解析SQL命令。SQL是以字符串的形式传过来的,我们得解析成数据库认识的、合法的SQL语句。
解析过程主要包含以下五个阶段:
-
词法分析:
-
按照,进行分词拆分,将一条SQL拆分成各个零件,拿上面的SQL语句就是:
-
SELECT,customer_id,first_name,last_name,FROM,customer,WHERE,customer_id,=,14
-
-
语法分析:
- 进行SQL鉴定,完成完整的SQL解析树:
- 按照词法分析得到的SQL各个局部所属分类进行划分,把具有相同特征的词划分到同一类。
-
解析树:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-VGQSSnBe-1644828319273)(C:\Users\noblegasesgoo\AppData\Roaming\Typora\typora-user-images\image-20211120171032507.png)]](https://img-blog.csdnimg.cn/576ee9d8af984461a21f51d5c0bec5c0.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBATm9ibGVnYXNlc2dvbw==,size_20,color_FFFFFF,t_70,g_se,x_16)
-
预处理器:
- 去进一步的检查解析树是否合法,比如就是去查看表是否存在,列是否存在。
-
新解析树:
- 通过预处理器核对之后生成的新的解析树,新解析树可能和旧解析树结构一致。
-
查询优化器:
- 负责获得最优执行计划的生成策略是什么。
- SQL语句在执行之前,也就是生成新的解析树之后,按照树状层次结构进行解析的。
- 一般会重新定义表的关联,类似指令重排。
- SQL查询一般会选择一个索引去执行。
- 提前终止查询。
**在执行以上所有步骤之后我们会获得一个相对完整高效的执行计划。**然后交给我们的存储引擎与底层文件交互。
存储引擎
主要负责与底层文件层进行交互从而==完成数据在物理层面的真正存储和读取==。
一张表使用的存储引擎决定了表中数据的存储结构不同,它是针对表而不是针对库的,一个库中不同表可以用不同的存储引擎。
插件式的存储引擎架构将查询处理和其它的系统任务以及数据的存储提取分离。
# 查询当前数据库的存储引擎
show variables like '%storage_engine%';
分类
存储引擎大致可以分为以下几种:
InnoDB(重点)
- 5.5版本之后MySQL数据库默认的存储引擎。
- 支持事务,行级锁定,但是处理速度比较低。
特点
- 支持事务 。
- 表空间:大。
- MVCC机制:读不加锁,读写可以并发,写操作不会阻塞读操作。
- 通过这个机制我们可以解决不可重复读的问题,加锁解决幻读问题。
- 并发性:行级锁,表级锁,粒度更小,适合高并发
- 独特的索引结构。
- 缓存:索引和真实数据都要缓存,对内存要求较高,而且==内存大小对性能有决定性的影响==。
适用场景
- 需要事务支持并且高并发、数据更新比较频繁的应用场景。
MyISAM
- 5.5版本之前MySQL数据库默认的存储引擎。
- 有较高的插入删除速度,但是不支持行锁,事务,外键。
- 表数据由MYD和MYI两个文件组成。
- 并发性来说是表锁。
- 不支持事务。
- 主要用于临时表的引擎。
适用场景
- 非事务型,读多写少或者只读类应用,因为不支持事务。
CSV
- 跨平台交换的数据文件一般用它来存储。
特点
- 使用普通的csv文件存储数据。
- 不支持索引。
- 列不能为null!
适用场景
适合作为中间表,进行数据交换。
- Excel文件可以直接转换为csv文件,可以直接在MySQL服务端中使用。
- 其它存储引擎的数据,可以转存到csv存储引擎的表中,然后用户可以直接使用该文件。
Memory
- 内存的存储引擎,具有极高的增删改查速度。
- 但是它存储的数据具有易失性。
特点
- 数据存储在内存中,没有持久性,但是查询速度极快。
- 支持索引类型:HASH和BTREE索引。
适用场景
- 不建议使用,数据具有易失性,在MySQL重启后表会被清空。
- 数据存储在内存中,受内存大小限制。
码云仓库同步笔记,可自取欢迎各位star指正:https://gitee.com/noblegasesgoo/notes
如果出错希望评论区大佬互相讨论指正,维护社区健康大家一起出一份力,不能有容忍错误知识。
—————————————————————— 爱你们的 noblegasesgoo















 2229
2229











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









