







一、MAGI-1简介
MAGI-1 是一种逐块生成视频的自回归去噪模型,而非一次性生成完整视频。每个视频块(含 24 帧)通过整体去噪处理,当前块达到特定去噪阈值后,立即启动下一块的生成。这种流水线设计支持 最多 4 个块的并发处理 ,显著提升视频生成效率。
- 基于 Transformer 架构的变分自编码器(VAE)
- 采用 Transformer 架构的变分自编码器,支持 8 倍空间压缩和 4 倍时间压缩 ,在实现最快平均解码速度的同时,具备高度竞争性的重构质量。

SandAI提供了 MAGI-1 的预训练权重,包括 240 亿参数和 45 亿参数的模型,以及对应的蒸馏模型(Distill)和蒸馏 + 量化模型(Distill+Quant)。所有模型权重的下载链接详见表中内容。
| Model | Link | Recommend Machine |
|---|---|---|
| T5 | T5 | - |
| MAGI-1-VAE | MAGI-1-VAE | - |
| MAGI-1-24B | MAGI-1-24B | H100/H800 * 8 |
| MAGI-1-24B-distill | MAGI-1-24B-distill | H100/H800 * 8 |
| MAGI-1-24B-distill+fp8_quant | MAGI-1-24B-distill+quant | H100/H800 * 4 or RTX 4090 * 8 |
| MAGI-1-4.5B | MAGI-1-4.5B | RTX 4090 * 1 |
二、本地部署
| 环境 | 版本 |
|---|---|
| Python | >=3.10 |
| PyTorch | =2.4.0 |
| Ubtuntu | =22.4.0 |
注意由于官方目前并没有开放4.5B的模型,因此本次部署的是MAGI-1-24B-distill+fp8_quant这个模型,需要显卡H100/H800 * 4 or RTX 4090 * 8
1.创建虚拟环境
1.1安装Miniconda
步骤1:更新系统
首先,更新您的系统软件包:
sudo apt update
sudo apt upgrade -y
步骤2:下载Miniconda安装脚本
访问Miniconda的官方网站或使用以下命令直接下载最新版本的安装脚本(以Python 3为例):
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh
步骤3:验证安装脚本的完整性(可选)
下载SHA256校验和文件并验证安装包的完整性:
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh.sha256
sha256sum Miniconda3-latest-Linux-x86_64.sh
比较输出的校验和与.sha256文件中的值是否一致,确保文件未被篡改。
步骤4:运行安装脚本
为安装脚本添加执行权限:
chmod +x Miniconda3-latest-Linux-x86_64.sh
运行安装脚本:
./Miniconda3-latest-Linux-x86_64.sh
步骤5:按照提示完成安装
安装过程中,您需要:
阅读许可协议:按Enter键逐页阅读,或者按Q退出阅读。
接受许可协议:输入yes并按Enter。
选择安装路径:默认路径为/home/您的用户名/miniconda3,直接按Enter即可,或输入自定义路径。
是否初始化Miniconda:输入yes将Miniconda添加到您的PATH环境变量中。
步骤6:激活Miniconda环境
安装完成后,使环境变量生效:
source ~/.bashrc
步骤7:验证安装是否成功
检查conda版本:
conda --version
步骤8:更新conda(推荐)
为了获得最新功能和修复,更新conda:
conda update conda
1.2.创建虚拟环境
conda create -n magi python==3.10.12
2.下载PyTorch
#进入虚拟环境
conda activate magi
#下载pytorch
conda install pytorch==2.4.0 torchvision==0.19.0 torchaudio==2.4.0 pytorch-cuda=12.4 -c pytorch -c nvidia
3.克隆MAGI-1仓库
自动下载
git clone https://github.com/SandAI-org/MAGI-1.git
或者可以进入下面的网页收到过下载到本地
网址:SandAI-org/MAGI-1:MAGI-1:大规模自回归视频生成
4.安装依赖
#进入项目目录
cd /MAGI-1
#安装依赖
pip install -r requirements.txt
# Install ffmpeg
conda install -c conda-forge ffmpeg=4.4
5.安装MagiAttention
#下载MagiAttention
git clone https://github.com/SandAI-org/MagiAttention.git
#进入文件夹
cd /MAGI-1/MagiAttention
#安装依赖
git submodule update --init --recursive
pip install --no-build-isolation .
6.启动
6.1.参数说明
--config_file:指定配置文件的路径,其中包含模型配置参数,例如 .example/24B/24B_config.json--mode:指定作模式。可用选项包括:t2v: 文本到视频i2v: 图像到视频v2v: 视频到视频
--prompt:用于生成视频的文本提示,例如 ."Good Boy"--image_path:图像文件的路径,仅在 mode 中使用。i2v--prefix_video_path:前缀视频文件的路径,仅在 mode 中使用。v2v--output_path:保存生成的视频文件的路径。
6.2.Bash 脚本
#!/bin/bash
# Run 24B MAGI-1 model
bash example/24B/run.sh
# Run 4.5B MAGI-1 model
bash example/4.5B/run.sh
视频保存路径:/MAGI-1/example/assets/
6.3.自定义参数
您可以根据需要修改 中的参数。例如:run.sh
- 要使用 Image to Video 模式 (),请设置为 并提供 :
i2v``--mode``i2v``--image_path--mode i2v \ --image_path example/assets/image.jpeg \ - 要使用 Video to Video 模式 (),请设置为 并提供 :
v2v``--mode``v2v``--prefix_video_path--mode v2v \ --prefix_video_path example/assets/prefix_video.mp4 \
通过调整这些参数,您可以灵活地控制输入和输出以满足不同的要求。
7.使用本地下载模型(推荐)
在启动MAGI-1中它会在Hugging Face中下载模型,但是由于网络等原因会出现下载失败的问题,因此推荐本地下载模型
在魔搭社区中下载
#下载模型
modelscope download --model sand-ai/MAGI-1
#下载到指定文件夹
modelscope download --model 'sand-ai/MAGI-1' --local_dir 'path/to/dir'
7.1.配置模型路径
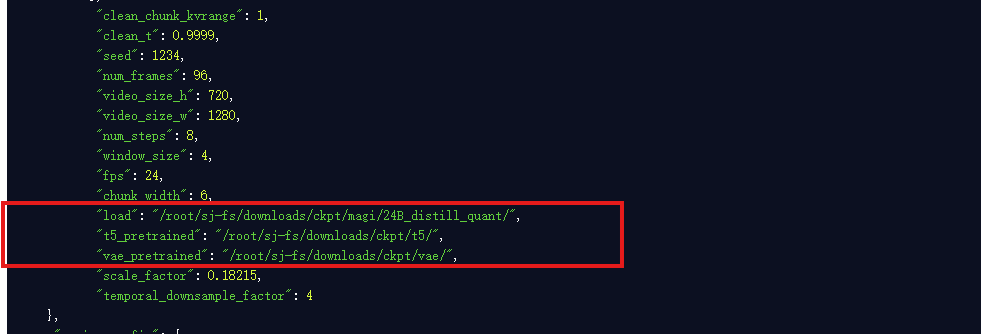
路径:/MAGI-1/example/24B/24B_config.json
按照自己的模型路径修改框中的三个参数
8.启动Web页面(可选)
官方发布的模型是没有web页面,本页面为自制,需要的可以设置
安装依赖
pip install gradio==5.26.0 python-dotenv psutil
8.1.目录结构
按照结构创建web及其web中的文件
/MAGI-1/
├── web/
│ ├── app.py # 主程序
│ ├── config_manager.py # 配置文件操作
│ ├── run_script.py # 脚本执行器
│ └── presets/ # 预设配置存储
└── example/
└── 24B/
└── 24B_config.json # 模型配置文件
还要创建log
mkdir -p /MAGI-1/log
设置执行权限
chmod +x /MAGI-1/example/24B/run.sh
8.2.Gradio 前端实现 (app.py)
import gradio as gr
import json
import os
import time
from config_manager import update_config, load_config
from run_script import run_generation
BASE_DIR = "/MAGI-1"
CONFIG_PATH = os.path.join(BASE_DIR, "example/24B/24B_config.json")
PRESETS_DIR = os.path.join(BASE_DIR, "web/presets")
OUTPUT_DIR = os.path.join(BASE_DIR, "example/assets") # 明确输出目录
# 初始化配置
def init_ui():
config = load_config(CONFIG_PATH)
return [
config["num_frames"],
config["video_size_h"],
config["video_size_w"],
config["num_steps"],
config["window_size"],
config["fps"]
]
# 动态显示输入组件
def toggle_inputs(mode):
return [
gr.File(visible=mode == "i2v", file_types=["image/*"]), # 允许所有图片类型
gr.File(visible=mode == "v2v", file_types=["video/*"]), # 允许所有视频类型
gr.Text(visible=True)
]
# 保存预设
def save_preset(name, params):
preset_path = os.path.join(PRESETS_DIR, f"{name}.json")
with open(preset_path, "w") as f:
json.dump(params, f)
return f"预设 {name} 保存成功!"
# 加载预设
def load_preset(name):
preset_path = os.path.join(PRESETS_DIR, f"{name}.json")
with open(preset_path, "r") as f: # 正确加载 JSON 文件
params = json.load(f)
return list(params.values()) # 返回参数列表
with gr.Blocks(title="MAGI-I 视频生成系统", theme=gr.themes.Soft()) as app:
gr.Markdown("# 🎥 MAGI-I 智能视频生成系统")
with gr.Row():
with gr.Column(scale=1):
mode = gr.Radio(
label="生成模式",
choices=["t2v", "i2v", "v2v"],
value="t2v"
)
prompt = gr.Textbox(label="输入提示", placeholder="请输入提示词...")
image_input = gr.File(label="上传图片", visible=False, type="binary")
video_input = gr.File(label="参考视频", visible=False, type="binary")
num_frames = gr.Slider(4, 128, step=8, label="视频帧数")
video_size_h = gr.Slider(256, 1080, step=16, label="视频高度")
video_size_w = gr.Slider(256, 1920, step=16, label="视频宽度")
num_steps = gr.Slider(1, 20, step=1, label="生成步数")
window_size = gr.Slider(1, 8, step=1, label="窗口大小")
fps = gr.Slider(12, 60, step=1, label="帧率")
with gr.Accordion("预设管理", open=False):
preset_name = gr.Textbox(label="预设名称")
save_btn = gr.Button("保存当前配置")
preset_status = gr.Textbox(label="操作状态")
load_dropdown = gr.Dropdown(
label="加载预设",
choices=[f.split(".")[0] for f in os.listdir(PRESETS_DIR)]
)
start_btn = gr.Button("🚀 开始生成", variant="primary")
with gr.Column(scale=2):
output_video = gr.Video(label="生成结果", format="mp4")
progress = gr.Slider(0, 100, label="生成进度", interactive=False)
duration_display = gr.Textbox(label="生成耗时(秒)") # 新增时间显示
logs = gr.Textbox(label="生成日志", lines=10)
with gr.Accordion("生成历史", open=True):
history = gr.DataFrame(
headers=["时间", "模式", "提示词", "输出文件", "耗时"],
datatype=["str", "str", "str", "str", "str"],
interactive=False
)
# 事件绑定
mode.change(toggle_inputs, inputs=mode, outputs=[image_input, video_input, prompt])
save_btn.click(
save_preset,
inputs=[preset_name, num_frames, video_size_h, video_size_w, num_steps, window_size, fps],
outputs=preset_status
)
load_dropdown.change(
load_preset,
inputs=load_dropdown,
outputs=[num_frames, video_size_h, video_size_w, num_steps, window_size, fps]
)
start_btn.click(
run_generation, # 确保该函数返回 duration
inputs=[
mode, prompt, image_input, video_input,
num_frames, video_size_h, video_size_w,
num_steps, window_size, fps
],
outputs=[output_video, progress, logs, history, duration_display]
)
if __name__ == "__main__":
app.launch(
server_port=8080,
server_name="0.0.0.0",
allowed_paths=[
OUTPUT_DIR, # 使用变量定义允许路径
PRESETS_DIR
],
app_kwargs={
"static_dirs": {
"/assets": OUTPUT_DIR # 确保静态路径映射正确
}
}
)
8.3.配置文件管理 (config_manager.py)
import json
import os
def load_config(path):
with open(path, "r") as f:
return json.load(f)
def update_config(path, params):
config = load_config(path)
config.update({
"num_frames": int(params[0]),
"video_size_h": int(params[1]),
"video_size_w": int(params[2]),
"num_steps": int(params[3]),
"window_size": int(params[4]),
"fps": int(params[5])
})
with open(path, "w") as f:
json.dump(config, f, indent=2)
8.4.脚本执行器 (run_script.py)
import subprocess
import time
import os
from threading import Thread
from queue import Queue, Empty
BASE_DIR = "/MAGI-1"
LOG_DIR = os.path.join(BASE_DIR, "log")
OUTPUT_DIR = os.path.join(BASE_DIR, "example/assets") # 明确定义输出目录
def convert_video(input_path):
"""使用ffmpeg转码为H.264格式(增加错误处理)"""
if not os.path.exists(input_path):
return input_path
output_path = input_path.replace(".mp4", "_converted.mp4")
try:
subprocess.run([
"ffmpeg", "-v", "error", # 隐藏非必要日志
"-i", input_path,
"-c:v", "libx264",
"-preset", "fast",
"-movflags", "+faststart", # 优化网络播放
"-y",
output_path
], check=True, stderr=subprocess.PIPE)
print(f"转码成功: {input_path} -> {output_path}")
return output_path
except subprocess.CalledProcessError as e:
print(f"转码失败: {e.stderr.decode()}")
return input_path
except Exception as e:
print(f"未知错误: {str(e)}")
return input_path
def run_generation(mode, prompt, image, video, *params):
start_time = time.time()
# 初始化临时文件变量
temp_image = None
temp_video = None
# 确保输出目录存在
os.makedirs(OUTPUT_DIR, exist_ok=True)
# 生成唯一文件名(包含原始模式标记)
timestamp = int(time.time())
base_name = f"output_{mode}_{timestamp}"
raw_path = os.path.join(OUTPUT_DIR, f"{base_name}.mp4")
if not prompt or prompt.strip() == "":
raise ValueError("提示词不能为空!")
# 构建命令参数(使用列表格式避免注入风险)
cmd_args = [
"bash", os.path.join(BASE_DIR, "example/24B/run.sh"),
"--mode", mode,
"--prompt", prompt.strip(), # 添加清理空格处理
"--output_path", raw_path
]
# 处理输入文件(使用临时文件拷贝)
if mode == "i2v" and image:
temp_image = os.path.join(OUTPUT_DIR, f"temp_{timestamp}.jpg")
with open(temp_image, "wb") as f:
f.write(image) # 直接写入二进制数据
cmd_args.extend(["--image_path", temp_image])
if mode == "v2v" and video:
temp_video = os.path.join(OUTPUT_DIR, f"temp_{timestamp}.mp4")
with open(temp_video, "wb") as f:
f.write(video) # 直接写入二进制数据
cmd_args.extend(["--prefix_video_path", temp_video])
# 执行生成(禁用shell=True提高安全性)
logs = []
try:
process = subprocess.Popen(
cmd_args,
stdout=subprocess.PIPE,
stderr=subprocess.STDOUT,
text=True,
encoding="utf-8",
errors="replace"
)
# 实时日志捕获
def logger():
while True:
output = process.stdout.readline()
if output == '' and process.poll() is not None:
break
if output:
logs.append(output.strip())
log_thread = Thread(target=logger)
log_thread.start()
process.wait()
log_thread.join()
except Exception as e:
logs.append(f"执行错误: {str(e)}")
finally: # 清理临时文件
for f in [temp_image, temp_video]:
if f is not None and os.path.exists(f):
os.remove(f)
# 转码处理
final_path = convert_video(raw_path)
# 设置文件权限(兼容Windows)
if os.name != 'nt':
os.chmod(final_path, 0o644)
# 生成web路径(与static_dirs配置对应)
web_path = f"/assets/{os.path.basename(final_path)}"
# 计算耗时(包含转码时间)
time_cost = time.time() - start_time
# 构建历史记录
history_entry = [
time.strftime("%Y-%m-%d %H:%M:%S"),
mode.upper(),
prompt[:20] + "..." if len(prompt) > 20 else prompt,
os.path.basename(final_path),
f"{time_cost:.1f}秒"
]
return (
final_path, # 输出视频路径,返回绝对路径
100, # 进度
"\n".join(logs), # 日志
[history_entry], # 历史记录
f"{time_cost:.1f}秒" # 耗时显示
)
8.5.需要修改的 run.sh 脚本
路径:/MAGI-1/example/24B/run.sh
#!/bin/bash
# ...保持原有环境变量设置不变...
# 解析命令行参数
while [[ $# -gt 0 ]]; do
case "$1" in
--mode)
MODE=$2
shift 2
;;
--prompt)
PROMPT=$2
shift 2
;;
--image_path)
IMAGE_PATH=$2
shift 2
;;
--prefix_video_path)
PREFIX_VIDEO_PATH=$2
shift 2
;;
--output_path)
OUTPUT_PATH=$2
shift 2
;;
*)
shift
;;
esac
done
# 更新运行命令
torchrun $DISTRIBUTED_ARGS inference/pipeline/entry.py \
--config_file example/24B/24B_config.json \
--mode ${MODE:-t2v} \
--prompt "${PROMPT:-Good Boy}" \
${IMAGE_PATH:+--image_path $IMAGE_PATH} \
${PREFIX_VIDEO_PATH:+--prefix_video_path $PREFIX_VIDEO_PATH} \
--output_path ${OUTPUT_PATH:-example/assets/output.mp4}
8.6.修改路径
路径:/MAGI-1/inference/pipeline/prompt_process.py
将prompt_process.py文件中框出来的部分修改为如图所示

8.7.启动 Web 服务
cd /MAGI-1/web
python app.py
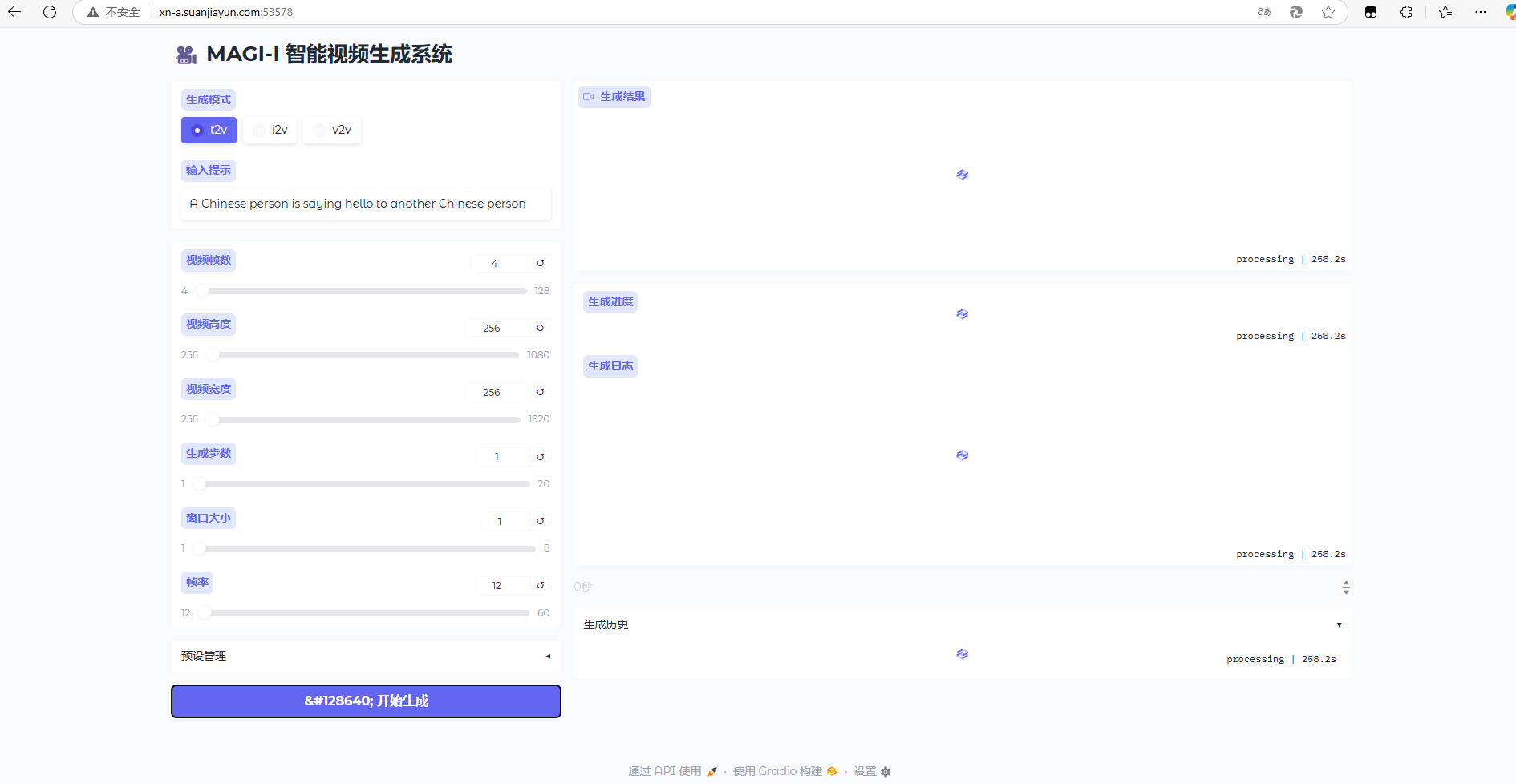
结果:

#在浏览器中输入网址
http://127.0.0.1:8080
web页面:


















 405
405

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









