







本篇文章主要讲讲分布式爬虫的实现,一个是基于主从模式的方法,另一个则是基于Scrapy_redis分布式实现的方法。
分布式进程:
分布式进程是指将Process进程分布到多台机器上,充分利用多台机器的性能完成复杂的任务。在Python的通过multiprocessing库来完成,该模块不仅支持多进程且还支持将多进程分布到多台机器上。分布式进程就是将把Queue暴露到网络中让其他机器进程可以访问的过程进行了封装,这个过程也称为本地队列的网络化。
创建分布式进程的服务进程(taskManager.py)主要为6个步骤:
1、建立队列Queue,用来进行进程间的通信;
2、把第一步中建立的队列在网络上注册,暴露给其他主机的进程,注册后获得网络队列,相当于本地队列的映像;
3、建立一个对象实例manager,绑定端口和验证口令;
4、启动第三步中建立的实例,即启动管理manager,监管信息通道;
5、通过管理实例的方法获得通过网络访问的Queue对象,即再把网络队列实体化成可以使用的本地队列;
6、创建任务到“本地”队列中,自动上传任务到网络队列中,分配给任务进程进行处理。
Linux版本:
#coding=utf-8
import Queue
from multiprocessing.managers import BaseManager
# 第一步,建立task_queue和result_queue来存放任务和结果
task_queue = Queue.Queue()
result_queue = Queue.Queue()
# 第二步,把创建的两个队列注册在网络上,利用register方法,callable参数关联了Queue对象,将Queue对象在网络中暴露
BaseManager.register('get_task_queue', callable=lambda:task_queue)
BaseManager.register('get_result_queue', callable=lambda:result_queue)
# 第三步,绑定端口8001,设置验证口令,相当于对象初始化
manager = BaseManager(address=('', 8001), authkey='ski12')
# 第四步,启动管理,监听信息通道
manager.start()
# 第五步,通过管理实例的方法获得通过网络访问的Queue对象
task = manager.get_task_queue()
result = manager.get_result_queue()
# 第六步,添加任务
for url in ["ImageUrl_" + str(i) for i in range(10)]:
print "put task %s ..." % url
task.put(url)
# 获取返回结果
print "try get result..."
for i in range(10):
print "result is %s" % result.get(timeout=10)
# 关闭管理
manager.shutdown()
Windows版本:
#coding=utf-8
import Queue
from multiprocessing.managers import BaseManager
from multiprocessing import freeze_support
# 任务个数
task_number = 10
# 第一步,建立task_queue和result_queue来存放任务和结果
task_queue = Queue.Queue(task_number)
result_queue = Queue.Queue(task_number)
def get_task():
return task_queue
def get_result():
return result_queue
def win_run():
# 第二步,把创建的两个队列注册在网络上,利用register方法,callable参数关联了Queue对象,将Queue对象在网络中暴露
# Windows下绑定调用接口不能使用lambda,所以只能先定义函数再绑定
BaseManager.register('get_task_queue', callable=get_task)
BaseManager.register('get_result_queue', callable=get_result)
# 第三步,绑定端口8001,设置验证口令,相当于对象初始化,Windows下需要填写IP地址
manager = BaseManager(address=('127.0.0.1', 8001), authkey='ski12')
# 第四步,启动管理,监听信息通道
manager.start()
try:
# 第五步,通过管理实例的方法获得通过网络访问的Queue对象
task = manager.get_task_queue()
result = manager.get_result_queue()
# 第六步,添加任务
for url in ["ImageUrl_" + str(i) for i in range(10)]:
print "put task %s ..." % url
task.put(url)
# 获取返回结果
print "try get result..."
for i in range(10):
print "result is %s" % result.get(timeout=10)
except:
print "Manager error"
finally:
# 一定要关闭管理,否则会报管道未关闭错误
manager.shutdown()
if __name__ == '__main__':
# Windows下多进程可能会有问题,添加这句可以缓解
freeze_support()
win_run()
而任务进程(taskWorker.py)则分为4个步骤:
1、使用QueueManager注册用于获取Queue的方法名称,任务进程只能通过名称来在网络上获取Queue;
2、连接服务器,端口和验证口令注意保持与服务进程中完全一致;
3、从网络上获取Queue,进行本地化;
4、从task队列获取任务,并把结果写入result队列。
#coding=utf-8
import time
from multiprocessing.managers import BaseManager
# 第一步,使用QueueManager注册用于获取Queue的方法名称
BaseManager.register('get_task_queue')
BaseManager.register('get_result_queue')
# 第二步,连接到服务器
server_addr = '127.0.0.1'
print "Connect to server %s..." % server_addr
# 端口和验证口令注意保持与服务进程完全一致
m = BaseManager(address=(server_addr, 8001), authkey='ski12')
# 从网络连接
m.connect()
# 第三步,获取Queue对象
task = m.get_task_queue()
result = m.get_result_queue()
# 第四步,从task队列获取任务,并把结果写入result队列
while(not task.empty()):
image_url = task.get(True, timeout=5)
print "run task download %s..." % image_url
time.sleep(1)
result.put("%s--->success" % image_url)
# 处理结束
print "worker exit."
先运行服务进程:
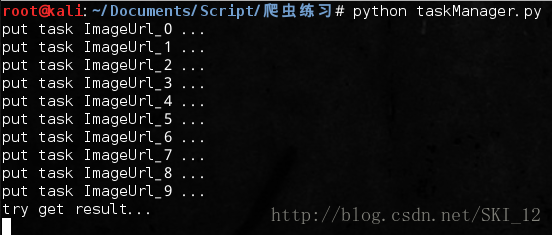
然后运行任务进程:
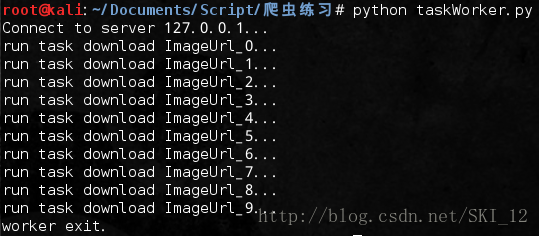
在服务进程可以查看到任务进程返回的情况:
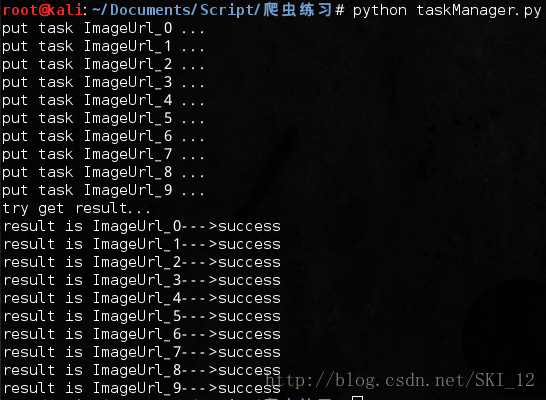
主从模式的分布式爬虫:
采用主从模式,由一台主机作为控制节点来负责管理所有运行爬虫的主机,爬虫只需从控制节点中接收任务并把新生成的任务提交给控制节点即可。缺点是容易导致整个分布式爬虫系统的性能下降。
控制节点分为URL管理器、数据存储器和控制调度器。
爬虫节点分为HTML下载器、HTML解析器和爬虫调度器。
其实和之前的基础爬虫框架类似,只不过添加了控制调度器来实现分布式的控制管理而已。
ControlNode控制节点:
NodeManager.py:
#coding=utf-8
import time
import sys
from multiprocessing import Queue, Process
from multiprocessing.managers import BaseManager
from DataOutput import DataOutput
from URLManager import UrlManager
class NodeManager(object):
# 创建一个分布式管理器
def start_Manager(self, url_q, result_q):
# 把创建的两个队列注册在网络上,利用register方法,callable参数关联了Queue对象,将Queue对象在网络中暴露
BaseManager.register('get_task_queue', callable=lambda:url_q)
BaseManager.register('get_result_queue', callable=lambda:result_q)
# 绑定端口8001,设置验证口令,相当于对象初始化
manager = BaseManager(address=('', 8001), authkey='ski12')
# 返回manager对象
return manager
def url_manager_proc(self, url_q, conn_q, root_url):
url_manager = UrlManager()
url_manager.add_new_url(root_url)
while True:
while(url_manager.has_new_url()):
# 从URL管理器获取新的url
new_url = url_manager.get_new_url()
# 将新的URL发给工作节点
url_q.put(new_url)
# print "[*]The number of crawled url is: ", url_manager.old_url_size()
# 显示进度条
percentage = u"[*]已爬取的URL数量为:%s" % url_manager.old_url_size()
sys.stdout.write('\r' + percentage)
# 加一个判断条件,当爬去2000个链接后就关闭,并保存进度
if(url_manager.old_url_size()>20):
# 通知爬行节点工作结束,添加标识符end
url_q.put('end')
print u"\n[*]控制节点通知爬行结点结束工作..."
# 关闭管理节点,同时存储set状态
url_manager.save_progress('new_urls.txt', url_manager.new_urls)
url_manager.save_progress('old_urls.txt', url_manager.old_urls)
return
# 将从result_solve_proc获取到的urls添加到URL管理器
try:
if not conn_q.empty():
urls = conn_q.get()
url_manager.add_new_urls(urls)
except BaseException, e:
# 延时休息
time.sleep(0.1)
def result_solve_proc(self, result_q, con 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 355
355











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









