







 本文详细介绍了如何使用Python爬虫处理动态页面数据,包括直接从JavaScript中采集和利用Selenium+PhantomJS/Firefox。通过实例演示了爬取MTime影评、肯德基门店、去哪儿网酒店信息和酷狗音乐下载链接的方法,讲解了识别动态页面、分析Ajax请求和利用浏览器驱动解析JavaScript的技巧。
本文详细介绍了如何使用Python爬虫处理动态页面数据,包括直接从JavaScript中采集和利用Selenium+PhantomJS/Firefox。通过实例演示了爬取MTime影评、肯德基门店、去哪儿网酒店信息和酷狗音乐下载链接的方法,讲解了识别动态页面、分析Ajax请求和利用浏览器驱动解析JavaScript的技巧。
很多网站通常会用到Ajax和动态HTML技术,因而只是使用基于静态页面爬取的方法是行不通的。对于动态网站信息的爬取需要使用另外的一些方法。
先看看如何分辨网站时静态的还是动态的,正常而言含有“查看更多”字样或者打开网站时下拉才会加载内容出来的进本都是动态的,简便的方法就是在浏览器中查看页面相应的内容、当在查看页面源代码时找不到该内容时就可以确定该页面使用了动态技术。
对于动态页面信息的爬取,一般分为两种方法,一种是直接从JavaScript中采集加载的数据、需要自己去手动分析Ajax请求来进行信息的采集,另一种是直接从浏览器中采集已经加载好的数据、即可以使用无界面的浏览器如PhantomJS来解析JavaScript。
1、直接从JavaScript中采集加载的数据
示例1——爬取MTime影评信息:
随便打开一个电影的URL:http://movie.mtime.com/99547/
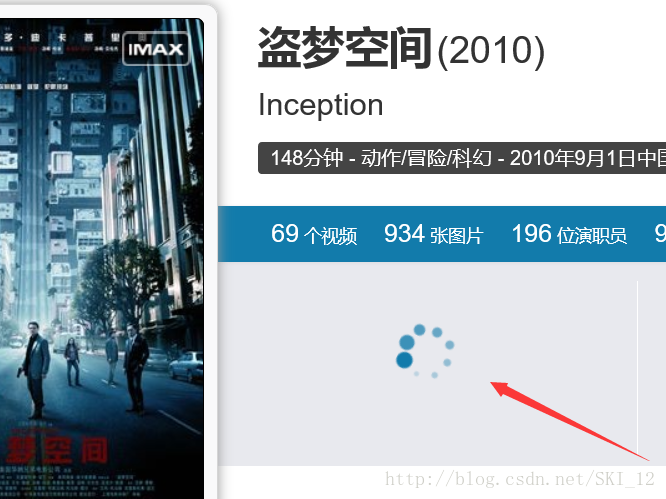
一开始出现转圈的加载,即可判断是动态加载的。
关注到“票房”这里:

查看源代码并找不到票房的字样:
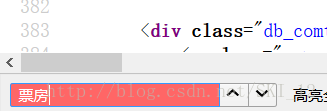
因此可断定该内容是使用Ajax异步加载生成的。
打开FireBug,在“网络”>“JavaScript”中查看含有敏感字符的接口链接,因为是和电影相关的,就先查看含有“Movie.api?Ajax_Callback=......”字样的链接,可以查看到其中一个含有影评和票房等信息:

为了进行确认哪些参数是会变化的,再打开一个新的电影的URL并进行相同的操作进行查看:

为了方便,直接上BurpSuite的Compare模块进行比较:

可以直接看到,只有以上三个参数的值是不一样的,其余的都是相同的。其中Ajax_RequestUrl参数值为当前movie的URL,t的值为当前时间,Ajax_CallBackArgument0的值为当前电影的序号、即其URL中后面的数字。
因此就可以构造Ajax请求的URL来爬取数据,回到top 100的主页http://www.mtime.com/top/movie/top100/,分析其中的标签等然后编写代码遍历top 100所有的电影相关票房和影评信息,注意的是并不是所有的电影都有票房信息,这里需要判断即可。
代码如下:
#coding=utf-8
import requests
import re
import time
import json
from bs4 import BeautifulSoup as BS
import sys
reload(sys)
sys.setdefaultencoding('utf8')
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.113 Safari/537.36',
}
def Get_Movie_URL():
urls = []
for i in range(1,11):
# 第一页的URL是不一样的,需要另外进行处理
if i != 1:
url = "http://www.mtime.com/top/movie/top100/index-%d.html" % i
else:
url = "http://www.mtime.com/top/movie/top100/"
r = requests.get(url=url,headers=headers)
soup = BS(r.text,'lxml')
movies = soup.find_all(name='a',attrs={'target':'_blank','href':re.compile('http://movie.mtime.com/(\d+)/'),'class':not None})
for m in movies:
urls.append(m.get('href'))
return urls
def Create_Ajax_URL(url):
movie_id = url.split('/')[-2]
t = time.strftime("%Y%m%d%H%M%S0368", time.localtime())
ajax_url = "http://service.library.mtime.com/Movie.api?Ajax_CallBack=true&Ajax_CallBackType=Mtime.Library.Services&Ajax_CallBackMethod=GetMovieOverviewRating&Ajax_CrossDomain=1&Ajax_RequestUrl=%s&t=%s&Ajax_CallBackArgument0=%s" % (url,t,movie_id)
return ajax_url
def Crawl(ajax_url):
r = requests.get(url=ajax_url,headers=headers)
if r.status_code == 200:
r.encoding = 'utf-8'
result = re.findall(r'=(.*?);',r.text)[0]
if result is not None:
value = json.loads(result)
movieTitle = value.get('value').get('movieTitle')
TopListName = value.get('value').get('topList').get('TopListName')
Ranking = value.get('value').get('topList').get('Ranking')
movieRating = value.get('value').get('movieRating')
RatingFinal = movieRating.get('RatingFinal')
RDirectorFinal = movieRating.get('RDirectorFinal')
ROtherFinal = movieRating.get('ROtherFinal')
RPictureFinal = movieRating.get('RPictureFinal')
RStoryFinal = movieRating.get('RStoryFinal')
print movieTitle
if value.get('value').get('boxOffice'):
TotalBoxOffice = value.get('value').get('boxOffice').get('TotalBoxOffice')
TotalBoxOfficeUnit = value.get('value').get('boxOffice').get('TotalBoxOfficeUnit')
print '票房:%s%s' % (TotalBoxOffice,TotalBoxOfficeUnit)
print '% 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 4222
4222

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









