









数据集介绍:10000条数据,被分为对照组和实验组,研究variant是否为revenue带来改变。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from scipy.stats import shapiro,mannwhitneyu,ttest_ind
一、清洗数据
新增一个可复用的查看函数:
使用了f-string进行格式化
def jiben_xinxi(data,head=5): #定义一个之后都可以用的“基本信息”函数
#等价print('shape:{}'.format(data.shape))
print(f'Shape:{data.shape}')
#等价print('Head'.center(70,'-'))
#>居右,<居左,填充符号+命令+宽度
print(f'{"Head":-^70}')
print(data.head(head))
print(f'{"Dtypes":-^70}')#print("Dtypes".center(70,'-'))
print(data.dtypes)
print(f'{"NULL":-^70}')
print(data.isnull().sum())
print(f'{"Describe":-^70}')
print(data.describe().round(2))
#把info拆成了shape、dtypes和isnull,更具有针对性,结果:
Shape:(10000, 3)
---------------------------------Head---------------------------------
USER_ID VARIANT_NAME REVENUE
0 737 variant 0.0
1 2423 control 0.0
2 9411 control 0.0
3 7311 control 0.0
4 6174 variant 0.0
--------------------------------Dtypes--------------------------------
USER_ID int64
VARIANT_NAME object
REVENUE float64
dtype: object
---------------------------------NULL---------------------------------
USER_ID 0
VARIANT_NAME 0
REVENUE 0
dtype: int64
-------------------------------Describe-------------------------------
USER_ID REVENUE
count 10000.00 10000.00
mean 4981.08 0.10
std 2890.59 2.32
min 2.00 0.00
25% 2468.75 0.00
50% 4962.00 0.00
75% 7511.50 0.00
max 10000.00 196.01
1.去除无控制数据
df.groupby('USER_ID')['VARIANT_NAME'].nunique().value_counts()
filt_uniq=(df.groupby('USER_ID')['VARIANT_NAME'].nunique()==1)
filt_uniq=filt_uniq[filt_uniq] #仅保留True,只在一个组
dta = df[df['USER_ID'].isin(filt_uniq.index)] #采用备份方式
2.去除异常值
通过观察描述性统计,可知revenue可能有极端值,使用散点图更具体地展现
dta.plot(kind='scatter',x='REVENUE',y='REVENUE',title='Revenue') #查找极端值
plt.savefig('outlier.png')

由图可知,在50-200之间不存在其他异常值,那么采用布尔索引筛选:
dta=dta[dta.REVENUE<196]
二、分组分析
1.可视化
(1)描述性
dta_group=dta.groupby(by=['USER_ID', 'VARIANT_NAME']).sum().reset_index().sort_values(by='VARIANT_NAME')
#用reset_index()合并层级
#sort_values(by='VARIANT_NAME',使paid的control也在之前
#或者在boxplot中调整: order=[]
f,(ax1,ax2)=plt.subplots(1,2,figsize=(10,8))
sns.boxplot(x='VARIANT_NAME',y='REVENUE',data=dta_group,ax=ax1,
showmeans=True,palette=sns.color_palette('pastel'))
ax1.set_title('All Users')
sns.boxplot(x='VARIANT_NAME',y='REVENUE',data=dta_group[dta_group.REVENUE>0],ax=ax2,
showmeans=True,palette=sns.color_palette('pastel'))
ax2.set_title('Users who paid')
plt.savefig('box_revenue.png')

(2)分布
.loc[]对复合条件的筛选更友好:
control_revenue=dta.loc[dta.VARIANT_NAME=='control','REVENUE']
variant_revenue=dta.loc[dta.VARIANT_NAME=='variant','REVENUE']
control_paid=dta.loc[(dta.VARIANT_NAME=='control')&(dta.REVENUE>0),'REVENUE']
variant_paid=dta.loc[(dta.VARIANT_NAME=='variant')&(dta.REVENUE>0),'REVENUE']
#分布
f,(ax1,ax2)=plt.subplots(2,figsize=(8,11))
sns.kdeplot(control_revenue,ax=ax1,label='Control')
sns.kdeplot(variant_revenue,ax=ax1,label='Variant')
ax1.legend()
ax1.set_title('All Users')
sns.kdeplot(control_paid,ax=ax2,label='Control')
sns.kdeplot(variant_paid,ax=ax2,label='Variant')
ax2.legend()
ax2.set_title('Users who paid')
plt.savefig('kde.png',bbox_inches='tight')

2.量化
引入agg汇总统计
#量化
sheet=dta.groupby('VARIANT_NAME').agg({'USER_ID':'nunique',
'REVENUE':['sum','mean','max','min']
}
)
sheet.reset_index()

-付费用户同理:

三、检验
1. 正态性
shapiro
shapiro(variant_revenue)
shapiro(variant_paid)
两者结果都近似<0.05,在5%显著性水平拒绝“正态分布”的假设,故而样本差异性应当用manwhitneyu检验,而非t
2.差异性
u_sta,p_val=mannwhitneyu(control_revenue,variant_revenue)
u_pai,p_paid=mannwhitneyu(control_paid,variant_paid)
man_result=pd.DataFrame([[u_sta,p_val],[u_pai,p_paid]],index=['all','paid'],columns=['U_Statistic','P_Value']
).round(2)
man_result.to_csv('man_result.csv',index=True)
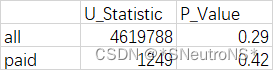
P值>0.05,无法拒绝两者无差异的假设。
四、结论
从总体收益来看,此一变动并未带来增长,且有些微下降,这一下降在付费用户来看中体现更为强烈。
运用Shapiro和MannWhitneyu检验,可知这一变动并未带来实质性的变化。
下一步的推广策略应当有所改变,以提高推广效益















 1697
1697











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









