







kylin DOC学习
1.集群部署
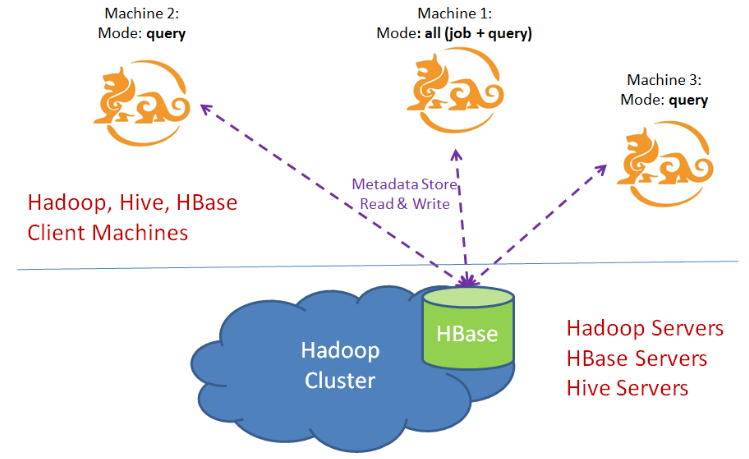
kylin实例运行状态被保存在Hbase中的Metadata store中并由kylin.properties的kylin.metadata.url配置,集群部署时运行多个kylin实例共享metadata store;
每个kylin实例在kylin.properties配置一个运行时模式,三种选项:1.运行job的job engine;2.运行query的job query;3.运行所有的job与query engine;
但是只能有一个server可以是1.3状态,其它的均为2.
2.配置应用
${KYLIN_HOME}/conf/kylin.properties
1.kylin.rest.servers属性用于配置kylin实例与其他的server实例同步sanbox;
2.kylin.server.mode用于配置kylin的运行模式(上面提到的三种);
配置负载均衡:为了保持集群模式kylin的高可用性,配置负载均衡。使客户端提交的所有的query经过此处路由后就交个集群处理;
kylin Web UI中的高级设置:可以覆盖掉${KYLIN_HOME}/conf/kylin.properties 的一些配置参数;
eg: kylin.cube.algorithm and kylin.storage.hbase.region-cut-gb(用于配置分割region的大小,default 5G 配置合适的大小有助于提高query性能)
cube级别配置Hadoop job
可以在cube中对conf/kylin_job_conf.xml and conf/kylin_job_conf_inmem.xml中的一些参数进行重新配置,但是要在相应参数的前面加前缀
kylin.engine.mr.config-override.
eg: 改变yarn的内存大小:kylin.engine.mr.config-override.mapreduce.map.java.opts=-Xmx7g and kylin.engine.mr.config-override.mapreduce.map.memory.mb=8192
改变yarn 资源的队列:kylin.engine.mr.config-override.mapreduce.job.queuename=myQueue
重写conf/kylin_hive_conf.xml中的hive job的配置,更换前缀kylin.source.hive.config-override.(重写后的配置会在运行Hive -e或者beeline时被加载)
重写默认的spark conf
前缀为kylin.engine.spark-conf.
配置文件级别的:
可用的压缩,提供了三种压缩方式:(kylin.properties中)
1.hbase table级别的压缩;kylin.hbase.default.compression.codec(none,snappy,lzo,gzip and lz4)
2.hive output级别的压缩;kylin_hive_conf.xml中,
3.MR job级别的压缩;kylin_job_conf.xml and kylin_job_conf_inmem.xml中配置;
配置好压缩算法后要重启kylin server运行实例;
(但是不推荐使用压缩算法;)
扩充kylin实例运行的内存:
在bin/setenv.sh中,

email 认证等等的配置。。。















 1243
1243











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









