







一、最基本的cube构建信息:
1.一个度量,并且计算包括:max、min and Count;
2.模型中的所有维度都被使用;
3.hive输入是一个CSV类型的外部表;
4.输出是没有经过压缩的HBase表。
二、kylin cube的优化方法:
1.减少组合;
通过构建cube时对维度在joint and Hierarchy参数上的配置减少cuboid的组合数量。
joint参数配置:把所有的id(主键)与对应的信息进行组合;
Hierarchies参数配置:把可以级联查询的维度可能放在里面;
注意:当前还不能对同一个维度同时进行joint和Hierarchy参数的配置;
2.对输出进行压缩配置
压缩算法:snappy and gzip
注:(snappy的效果大于gzip)二者在时间性能上的区别较小1%,在压缩空间上的区别为18%。
3.对输入的hive table压缩
通常构建cube的时间分配如下:
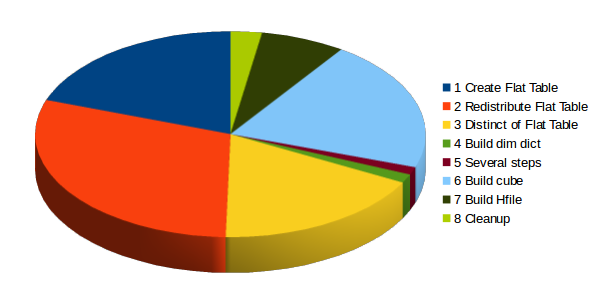
通常构建cube时花在创建flat table、Build和clean up上的时间较多。组成比例为:
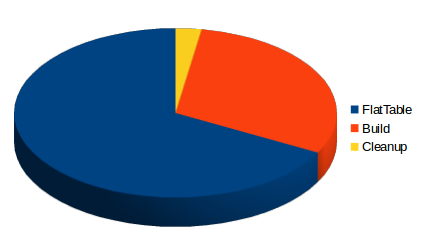
由图看出大多数的时间呗用到create flat table上因此可以对第一步创建flat table进行压缩编码,减少时间消耗。
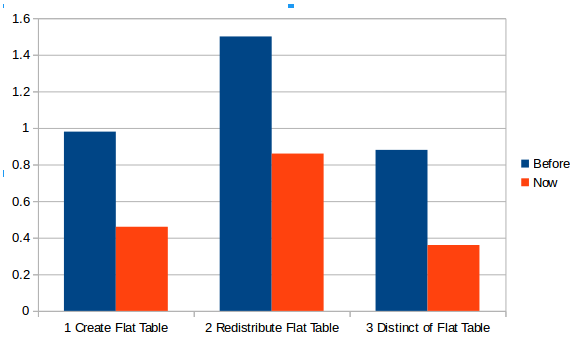
使用snappy算法压缩后的时间消耗为:
hive中的数据采用不同的文件格式进行存储时在构建cube时各阶段的时间消耗情况:
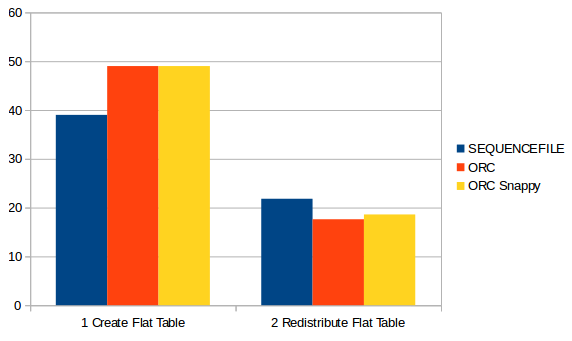
注:ORC文件格式概述:https://www.iteblog.com/archives/1014.html
4.对hive表进行分区(未实现优化,效果反而更糟)
5.HBase表存储格式优化
选择对维度的编码(dict、int、fix length)并且设置各维度在rowkey中的顺序(根据各维度的基数大小,大的在前小的在后)
6.通过设置Map和reduce的数量提高MR的性能。
eg:

7.提高cube的响应时间
通过设置聚合组(Aggregations group)来提高查询时的命中率。
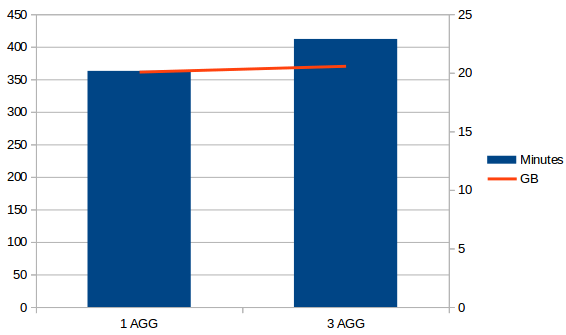
设置一个聚合组和设置3个聚合组的情况对比:3个聚合组相对1个聚合组在构建cube时花费的时间多了3%,存储容量多了0.6%;
但是查询性能更快了。















 175
175











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









