







使用spark.read.jdbc读取表后注册成临时表,再将表UNION ALL起来可不形成宽依赖,将多张分表合并成总表的job放在一个stage中
从而可以根据任务启用资源的调整(主要是core数)将从MySQL抽数的任务并行处理
下图为任务执行的的DAG图,可以看到128个分表虽然在代码中是循环读,但是实际上分成了1个stage中的128个task并行执行
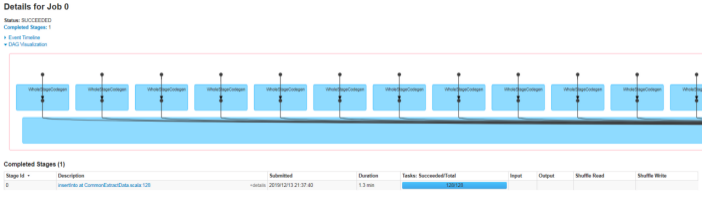
下面为验证:
由于测试环境资源有限,分别进行了如下三种资源调整测试效率(也只是观察趋势,具体生产环境配置还需要测试调整)
num-executors:1 executor-cores: 1 executor-memory 1g (单线程串行执行)

num-executors:4 executor-cores: 4 executor-memory 1g (16并发执行)

num-executors:4 executor-cores: 8 executor-memory 1g (32并发执行)
















 1166
1166











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









