






 本文围绕领域自适应展开,指出以往基于特征的领域自适应未能有效减少数据距离。介绍了结构对应学习算法、固定子空间分析、最大平均差异嵌入等方法及其局限。提出迁移成分分析(TCA),通过最小化φ(XS)和φ(XT)距离、参数化内核映射、迁移成分提取等步骤,解决领域自适应问题。
本文围绕领域自适应展开,指出以往基于特征的领域自适应未能有效减少数据距离。介绍了结构对应学习算法、固定子空间分析、最大平均差异嵌入等方法及其局限。提出迁移成分分析(TCA),通过最小化φ(XS)和φ(XT)距离、参数化内核映射、迁移成分提取等步骤,解决领域自适应问题。
-@[TOC](Domain Adaptation via Transfer Component Analysis(笔记))
Abstract
- 领域自适应:从的目标集演变为相关但不同的目标集
- 解决的问题:以前的基于特征的领域自适应没有有效的减少数据之间的距离
Introduction
结构对应学习算法(SCL)
诱导不同领域之间的特征对应,依赖于两个域中的主特征值的启发式选择,基于SCL的A-distance可以减少两个域之间的距离但对不同的应用比较敏感。
固定子空间分析(SSA)
为了改进以前的基于特征的领域自适应方法并显示的表示两个域之间的域的减少,von Bünau等提出了SSA。其专注于固定子空间的研究,对空间中数据方差的不甚注意。
最大平均差异嵌入(MMDE)
MMDE的目标是在保留数据方差的同时减少数据分布之间的距离。但也存在两个局限,其一这是通过样本直推的(transductive),不能推广到样本外模式。其二通过求解一个半定程序(SDP)来学习潜在空间,计算费力。
PREVIOUS WORKS AND PRELIMINARIES
如果两个领域存在相关关系,则可能存在几个共同组件或者潜在变量,其中某些变量可能会造成不同的数据分布。并且其中一些成分能够从原始数据中剖析内部结构或者充当区别其他数据的信息。提出了一种新的特征提取降维方法,通过将数据投影到学习的转移子空间来减少域间的距离。TCA及其半监督扩展SSTCA比MMDE的效率要高得多,并且可以处理样本外扩展问题
目标
目标是发现那些不引起跨域分布变化很大,并且能够很好地保存原始数据的结构或任务相关信息的组件。
一个好的特征表示应该能够尽可能地减少域之间分布的差异,同时保留原始数据的重要属性,特别是对于目标域数据,如几何属性、统计属性或侧信息。
A. Domain Adaptation
认为一个域由两部分组成:输入X的特征空间和输入P(X)的边际概率,其中
X
=
{
x
1
,
x
2
,
x
3
.
.
.
x
n
}
X={\{ x_1,x_2,x_3...x_n }\}
X={x1,x2,x3...xn},此论文的研究对象对共享一个源和目标域和特征空间的的域。假定源域中标记的数据记作
D
S
D_S
DS,且
D
S
=
{
x
S
1
,
y
S
1
,
x
S
2
,
y
S
2
.
.
.
x
S
n
1
,
y
S
n
1
}
D_S=\{x_{S_1},y_{S_1},x_{S_2},y_{S_2}...x_{S_{n_1}},y_{S_{n_1}}\}
DS={xS1,yS1,xS2,yS2...xSn1,ySn1}其中
x
S
i
x_{S_i}
xSi属于输入X,
y
S
i
y_{S_i}
ySi是对应的输出;同时目标域数据
D
T
=
{
x
T
1
,
x
T
2
,
.
.
.
.
,
x
T
n
2
}
D_T=\{x_{T_1},x_{T_2},....,x_{T_{n_2}}\}
DT={xT1,xT2,....,xTn2}其中
x
T
i
x_{T_i}
xTi也来自输入X。将来自源域和目标域的
X
S
X_S
XS和
X
T
X_T
XT的边际分布记为
P
(
X
S
)
P(X_S)
P(XS)和
Q
(
X
T
)
Q(X_T)
Q(XT)简称为P、Q,最关键的假设是P≠Q,但
P
(
Y
S
∣
X
S
)
=
P
(
Y
T
∣
X
T
)
P(Y_S|X_S)=P(Y_T|X_T)
P(YS∣XS)=P(YT∣XT)。
核平均分配(KMM)是一种基于内核的方法,对再生核希尔伯特空间(RKHS)中的实例重新分配权值,解决协变量移位适应问题。SSA程序通过匹配不同时期数据分布的前两个矩来寻找平稳分量。关注如何识别一个固定子空间,不考虑在潜在空间中保留数据属性,可以将数据映射到一些有噪声的因素。
B. Hilbert Space Embedding of Distributions
最大平均差异(MMD):给定两个分部的样本
X
=
{
x
i
}
X=\{x_i\}
X={xi}和
Y
=
{
y
i
}
Y=\{y_i\}
Y={yi}通过在RKHS的嵌入分布估计样本之间的距离不需要中间密度估计。让核诱导的特征映射为φ。
x
1
,
…
,
x
n
1
{x_1,…,x_{n1}}
x1,…,xn1和
y
1
,
.
.
.
,
y
n
2
{y_1,..., y_{n2}}
y1,...,yn2之间的经验估计是
M
M
D
(
X
,
Y
)
=
∣
∣
1
/
n
1
∑
i
=
1
n
1
φ
(
x
i
)
−
1
/
n
2
∑
i
=
1
n
2
φ
(
y
i
)
∣
∣
H
2
MMD(X,Y)=||1/n1\sum_{i=1}^{n1}φ(x_i)-1/n2\sum_{i=1}^{n2}φ(y_i)||_H^2
MMD(X,Y)=∣∣1/n1∑i=1n1φ(xi)−1/n2∑i=1n2φ(yi)∣∣H2,其中·H是RKHS范数。这样两个分布之间的距离仅仅是RKHS中两个平均元素之间的距离。
希尔伯特-施密特独立标准(HSIC):HSIC是一个非参数标注你来测量集合X和Y之间的依赖性,从相应的核矩阵容易计算有偏的RKHS中交叉协方差算子的希尔伯特施密特范数。
H
S
I
C
(
X
,
Y
)
=
(
1
/
(
n
−
1
)
2
)
t
r
(
H
K
H
K
y
y
)
HSIC(X,Y)=(1/(n-1)^2)tr(H K H K_{yy})
HSIC(X,Y)=(1/(n−1)2)tr(HKHKyy)其中K,K_{yy}是对应X和Y的核矩阵。当RKHS是通用的,当且仅当X和Y是独立时HSIC逐渐趋于0,相反则依赖性越强。
C. Embedding Using HSIC
在嵌入或降维时,通常希望保持局部数据的几何形状,同时最大限度的将嵌入与可用的信息对齐。这将导致 m a x t r ( H K H K y y ) max tr(H K H K_{yy}) maxtr(HKHKyy)受限于K。
transfer component analysis (TCA)
使用一个较弱的假设,这个假设更加现实,即P≠Q,但 P ( φ ( X S ) ) ≈ P ( φ ( X T ) ) P(φ(X_S )) ≈ P(φ(X_T )) P(φ(XS))≈P(φ(XT)),标准的监督学习可以应用于用社源域数据φ(X_S)和对应标签Y_S上,以训练用于映射目标域数据φ(X_T)的模型。因为目标与没有标签所以无法直接最小化分布之间的距离获得φ。因为边缘分布源X和目标X之间的距离很小且 φ ( X S ) φ(X_S) φ(XS)和 φ ( X T ) φ(X_T) φ(XT)保留了 X S X_S XS和 X T X_T XT的重要性质可以学习φ。
A.最小化 φ ( X S ) φ(X_S) φ(XS)和 φ ( X T ) φ(X_T) φ(XT)之间的距离
关键是去学习,对学习到的核矩阵使用PCA方法得到跨域的低维隐空间。
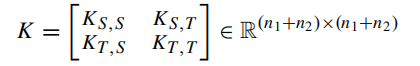 其中
其中
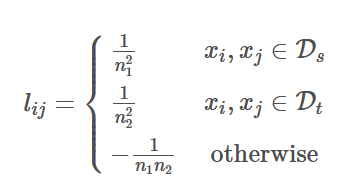
B.参数化内核映射
使用一种局域核特征提取的非线性映射φ的框架,避免使用SDP。首先核矩阵K可以分解为
K
=
(
K
K
−
1
/
2
)
(
K
−
1
/
2
K
)
K=(K K^{-1/2})(K^{-1/2} K)
K=(KK−1/2)(K−1/2K)考虑使用 (n1+n2)×m 维的矩阵 W 将特征变化到 m 维空间 (通常 m≪n1+n2), 则得到的核矩阵为
K
=
(
K
K
−
1
/
2
W
)
(
W
T
K
−
1
/
2
K
)
=
K
W
W
T
K
K=(KK^{−1/2}W)(W ^TK^{−1/2}K)=K W W^T K
K=(KK−1/2W)(WTK−1/2K)=KWWTK其中,
k
x
=
[
k
(
x
1
,
x
)
,
⋯
,
k
(
x
n
1
+
n
2
,
x
)
]
T
∈
R
n
1
+
n
2
k_x=[k(x_1,x),⋯,k(x_{n1+n2},x)]^T∈R^{n1+n2}
kx=[k(x1,x),⋯,k(xn1+n2,x)]T∈Rn1+n2此时两个域之间的经验距离均值可以重定义为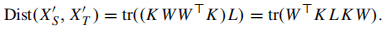
C.迁移成分提取
在最小化两个域之间的经验距离均值可以加一个正则项
t
r
(
W
T
W
)
tr(W^TW)
tr(WTW),来控制参数W的复杂度。则领域自适应的核学习问题变为:
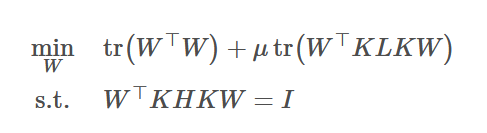
·μ是权衡参数
·
I
∈
R
m
×
m
I∈R^{m×m}
I∈Rm×m 为单位阵
·
H
=
I
n
1
+
n
2
−
1
/
(
n
1
+
n
2
)
1
1
T
H=I_{n1+n2}-1/(n1+n2)11^T
H=In1+n2−1/(n1+n2)11T为中心矩阵。

















 1381
1381

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









