









本篇是迁移学习专栏介绍的第二篇论文,由CUHK的杨强教授于2011年发表在AAAI的提出的应用在Domain Adaption上的TCA。机器学习中有一类非常有效的方法叫做降维(dimensionality reduction),用简单的话来说就是,把原来很高维度的数据(比如数据有1000多列)用很少的一些代表性维度来表示(比如1000多维用100维来表示)而不丢失关键的数据信息。这些降维方法多种多样,比如:主成分分析(PCA,principal component analysis)、局部线性嵌入(LLE, locally linear embedding)、拉普拉斯特征映射(Laplacian eigen-map)等。这些方法的过程大体都是一个大的矩阵作为输入,然后输出一个小矩阵。那么在迁移学习中,有没有这样的方法,通过降维来达到数据维度减少,而且能达到迁移学习目的呢?答案是显然的,就是我们要说的迁移成分分析(TCA,transfer component analysis)。(部分摘自王晋东不在家的迁移学习知乎专栏)
Abstract
领域自适应Domain Adaptation通过利用不同但相关的源领域中的训练数据来解决目标领域中的学习问题。直观地说,发现一个好的特征表示是至关重要的。在本文中,我们提出了一种新的学习方法,迁移成分分析Transfer Component Analysis(TCA)来寻找这种表示形式,用于Domain Adaptation。
TCA尝试使用最大平均偏差Maximum Mean Discrepancy(MMD)学习在一个可复制核希尔伯特空间Reproducing Kernel Hilbert Space(RKHS)中跨域的Transfer Component。在这些传输分量所张成的子空间中,不同区域的数据分布比较接近。因此,利用该子空间中的新表示,我们可以应用标准的机器学习方法来训练源域中的分类器或回归模型,以便在目标域中使用。研究的主要贡献是提出了一种新的特征表示方法,该方法利用特征提取方法,通过新的参数核进行域自适应,将数据投影到所学习的Transfer Component上,极大地减小了域分布之间的距离。此外,我们的方法可以处理大型数据集,并自然地导致样本外泛化。通过跨域室内WiFi定位和跨域文本分类两个实际应用的实验,验证了该方法的有效性和有效性。
1 Introduction
Domain Adaptation的目的是使在源领域中训练的分类器或回归模型适应目标领域中使用的分类器或回归模型,其中源领域和目标领域可能不同,但是相关。当目标域中标记数据供应不足时,这一点尤为重要。
- 例如,在室内WiFi定位中,在大规模的环境下校准一个定位模型是非常昂贵的。然而,WiFi信号强度可能是时间、设备或空间的函数,取决于动态因素。减少重校准的工作,我们可能要适应一个定位模型训练在一个时间段(源域)的新时期(目标领域),或适应本地化模型训练在一个移动设备(源域)为新的移动设备(目标领域)。然而,随着时间的推移或跨设备收集到的WiFi数据分布可能会非常不同,因此需要进行域适应[Yang et al., 2008]。
- 另一个例子是情绪分类。为了减少为各种产品注释评审的工作量,我们可能需要将一个针对某些类型的产品(源领域)进行培训的学习系统调整为一种新类型的产品(目标领域)。然而,在不同类型产品的评审中使用的术语可能非常不同。因此,不同类型产品上的数据分布可能不同,因此需要再次进行领域适应[Blitzer et al., 2007]。
如何减小源域数据和目标域数据分布的差异,是Domain Adaptation中一个重要的计算问题。直观地说,跨域发现一个好的特性表示是至关重要的。一个好的特征表示应该能够尽可能减少域之间分布的差异,同时保留原始数据的重要(几何或统计)属性。
最近,提出了几种方法来学习Domain Adaptation的公共特征表示[Daume III, 2007; Blitzer et al., 2006]。Daume III[2007]提出了一种简单的启发式非线性映射函数,将源域和目标域的数据映射到高维特征空间,在高维特征空间中使用标准的机器学习方法来训练分类器。Blitzer等[2006]提出了所谓的结构对应学习算法(SCL)来诱导不同领域特征之间的对应。该方法依赖于两个领域中经常出现的主特征的启发式选择。虽然实验表明,基于a -距离测度的SCL可以减小域间的差异[Ben-David et al., 2007],但主特征选择的启发式准则可能对不同的应用较为敏感。Pan等[2008]提出了一种新的降维方法——最大平均差嵌入(MMDE),用于Domain Adaptation。MMDE的动机与我们提出的工作类似。它还旨在学习域下的共享潜在空间,从而减少分布之间的距离。然而,MMDE的两个主要局限性在于
- MMDE具有transductive,不能推广到样本外模式;
- MMDE通过求解semi-definite program(SDP)来学习潜在空间,这是一个非常昂贵的优化问题。
在本文中,我们提出了一种新的区域自适应特征提取方法——迁移成分分析(TCA)。它试图学习这两个域下的一组公共Transfer Component,以便在将不同域中的数据分布差异投影到这个子空间时,可以显著地减小数据分布的差异。然后,在这个子空间中可以使用标准的机器学习方法来训练跨领域的分类器或回归模型。更具体地说,如果两个域相互关联,那么它们的底层可能存在几个公共component(或潜在变量)。其中一些component可能会导致域之间的数据分布不同,而另一些component可能不会。其中一些component可能捕获原始数据下的内在结构,而其他component可能不捕获。我们的目标是发现那些不会导致跨域分布变化的component,并很好地捕获原始数据的结构。与MMDE相比,TCA处理样本外扩展问题的效率更高。
本文的其余部分组织如下。第2节首先描述了域适应的问题陈述和准备工作。我们提出的方法在第3节中给出。然后,我们将在第4节中回顾一些相关的工作。在第5节中,我们对室内WiFi定位和文本分类进行了一系列实验。最后一节给出了一些结论性的讨论
后来,![]() 表示矩阵A是对称的及正定的。更多的是,向量/矩阵的转置(在输入空间和特征空间)用上标表示,
表示矩阵A是对称的及正定的。更多的是,向量/矩阵的转置(在输入空间和特征空间)用上标表示,![]() 是矩阵A的伪逆矩阵,
是矩阵A的伪逆矩阵,是矩阵的迹trace。
2 Preliminaries of Domain Adaptation
在本文中,我们关注的是目标域没有标记训练数据,但是有大量未标记数据的情况。我们还假设源域中有一些标记数据可用,而目标域中只有未标记数据
可用。我们将源域数据表示为
,其中
为输入,
为相应的输出。类似地,我们将目标域数据表示为
,其中输入
也是
,设
(简称
)分别为
和
的边缘分布。一般来说,
是不同的。然后,我们的任务是预测与目标域中输入
对应的标签
。在典型的域适应设置中,关键的假设是
,而P (YS|XS) = P (YT |XT)。
2.1 Maximum Mean Discrepancy
许多标准,如Kullback-Leibler (KL)散度,可以用来估计分布之间的距离。
然而,这些标准中有许多是参数化的,因为通常需要进行中等密度估计。为了避免这种非平凡的任务,更需要分布之间的非参数距离估计。最近,Borgwardt等[2006]提出了基于重生成核希尔伯特空间(RKHS)的最大均值差异(MMD)作为比较分布的相关准则。设为分布为
的随机变量集。由MMD定义的
之间距离的经验估计为
是一个通用的RKHS [Steinwart, 2001],
因此,通过将两个样本的均值映射到RKHS中,可以很好地估计出两个样本分布之间的距离。
3 Transfer Component Analysis
基于源域的输入和输出
以及目标域的输入
,我们的任务是预测目标域中未知的输出
。区域自适应的一般假设是,边缘密度
是非常不同的。在本节中,我们尝试为
找到一个共同的潜在表示,它保留了转换后两个域的数据配置。令期望的非线性变换为
。让
作为分别从源、目标和组合域转换输入集。然后,我们希望
。
假设特征地图是一个普遍的内核。如2.1节所示,两个分布
之间的距离可以用(2)两个域的经验均值之间的距离:
因此,一个理想的非线性映射可以通过最小化这个量。然而,
通常是高度非线性和(2)的直接优化可以陷入局部最小值。因此,我们需要基于以下假设找到一种新的方法。
The key assumption 在建议的域适应设置中为,但是
在转换输入映射
的输入中。
在3.1节中,我们首先回顾最大意味着差异嵌入(MMDE)提出学习内核矩阵K非线性映射对应SDP求解一个优化问题。在第3.2节中,我们提出了MMDE的核矩阵分解。第3.3和3.4节讨论了一种用于内核学习和计算问题的高效特征分解算法。
3.1 Kernel Learning for Domain Adaptation
除了寻找非线性显式转换,Pan等[2008]提出将该问题转化为一个核心学习问题。借助核函数的技巧,
,式(2)中两个域的经验均值之间的距离为:
其中是
大小的核矩阵,
分别表示由k定义的核矩阵在源域、目标域和跨域上的数据:
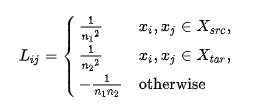
在转换设置中,学习核k(·,·)可以通过学习核矩阵k来解决。在[Pan et al., 2008]中,得到的核矩阵学习问题被表述为一个半定程序(SDP)。然后将主成分分析(PCA)应用到学习的核矩阵上,寻找跨域的低维潜在空间。这被称为最大平均差异嵌入(MMDE)。
3.2 Parametric Kernel Map for Unseen Patterns
MMDE有几个限制。首先,它具有转导性,不能对不可见的模式进行概括。其次,准则(3)要求K是正半定的,由此产生的核学习问题需要昂贵的SDP求解器来解决。最后,为了构造的低维表示,得到的K值需要PCA进行进一步的后处理。这可能会丢弃K中的有用信息。
在本文中,我们提出一个有效的方法来找到一个非线性映射基于内核特征提取。它避免了SDP的使用,从而降低了计算量。此外,所学习的核k可以直接推广到样本外模式。此外,我们提出了一种统一的核学习方法,利用显式低秩表示代替了MMDE中的两步学习方法。
首先,回忆一下(4)中的核矩阵K可以分解为,这通常被称为经验核映射[sch¨olkopf et al., 1998]。考虑使用一个大小为
的矩阵
将相应的特征向量转换为m维空间。一般来说,
。得到的核矩阵是
其中。特别地,给出了任意两种模式
之间评估值k对应的kernel:
其中。因此,kernel
在(6)为样本外的内核计算提供方便的参数化形式。
此外,利用的定义(5)中,两个域的经验均值之间的距离可以改写为:
3.3 Transfer Components Extraction
在最小化准则(7)中,通常需要正则化项来控制W的复杂度。正如本节后面所示,这个正则化项可以避免广义特征分解中分母的秩缺失。domain adaptation的核学习问题可归结为:
是trade-off参数,
是单位矩阵,
是散布矩阵,其中
是列均为1的向量,
是单位矩阵。此外,请注意约束
在(8)中添加,以避免平凡解(W = 0),从而使转换后的模式不会崩溃为一点,从而使学到的内核k膨胀,从而嵌入数据
在内核PCA中保存。
虽然优化问题(8)涉及非凸范数约束,仍可通过以下轨迹优化问题有效求解:

双方在左边乘以,然后替换成(11),我们获得(9)。由于矩阵
是非奇异矩阵,受益于正则化项
,我们获得一个等价的跟踪最大化问题(10)。
与kernel Fisher discriminant(KFD)相似,(10)中W的解是对应于的m个主导特征值的特征向量,其中最多可以提取
特征向量。在后续工作中,提出的方法被称为Transfer Component Analysis(TCA)。
3.4 Computational Issues
[Pan et al., 2008]中的核学习算法依赖于sdp。在有
变量,总的训练复杂度是
[Nesterov and Nemirovskii, 1994]。即使对于较小的问题,这在计算上也是不可行的。注意,这个核学习问题中的准则(3)类似于最近提出的监督降维方法colored MVU [Song et al., 2008],其中使用低秩近似来减少SDP中约束和变量的数量。然而,需要梯度下降来细化嵌入空间,从而使解陷入局部极小值。另一方面,我们提出的核学习方法只需要一个简单有效的特征分解。这只需要
提取m个非零特征向量的时间[Sorensen, 1996]。
4 Related Works
Domain Adaptation作为一种特殊的迁移学习环境[Pan and Yang, 2008],在自然语言处理(NLP)中得到了广泛的研究[Ando and Zhang, 2005;布利策等,2006;Daum e III, 2007]。Ando和Zhang[2005]以及Blitzer[2006]提出了基于主特征的启发式选择的结构对应学习(SCL)算法,用于学习跨域的公共特征表示。Daum e III[2007]设计了一个启发式内核,用于增强解决NLP中某些特定Domain Adaptation问题的特性。此外,Domain Adaptation也被研究在其他应用领域,如情绪分类[Blitzer et al., 2007]。Domain Adaptation的理论分析也在[Ben-David et al., 2007]中进行了研究。
样本选择偏差问题(也称为协变量漂移)也与域适应有关。在样本选择偏差中,基本假设是训练数据Xtrn与测试数据Xtst之间的采样过程可能不同。结果,,但是
。实例重加权是纠正样本选择偏差的主要技术[Huang et al., 2007;杉山等人,2008]。最近,提出了一种最先进的方法,称为核均值匹配(kernel mean matching, KMM) [Huang et al., 2007]。基于MMD理论对RKHS中的实例进行了加权,这与我们提出的方法不同。Sugiyama等[2008]提出了另一种权重重估算法Kullback-Leibler Importance Estimation Procedure (KLIEP),该算法与交叉验证相结合,自动进行模型选择。Xing等[2007]提出,基于训练和测试数据的混合分布,将shiftunaware分类器预测的标签对目标分布进行校正。通过重新加权实例匹配分布也成功地用于多任务学习[Bickel et al., 2008]。然而,与实例重加权不同的是,本文提出的TCA方法能够有效地去噪,同时为不同区域的分布寻找匹配的潜在空间,从而处理噪声特征(如图像数据和WiFi数据)。因此,TCA可以看作是无监督特征提取与潜在空间分布匹配的集成。
5 Experiments
在本节中,我们将提出的域自适应算法TCA应用于两个实际问题:室内WiFi定位和文本分类。
5.1 Cross-domain WiFi Localization
对于跨域WiFi定位,我们使用的数据集发表在2007年IEEE ICDM竞赛[Yang et al., 2008]。该数据集包含了时间段A(源域)收集到的部分带标签WiFi数据,以及时间段B(目标域)收集到的大量未带标签WiFi数据。这里,标签表示接收WiFi数据的对应位置。不同时间段的WiFi数据被认为是不同的域。任务是预测标签无线数据收集的时间。更具体地说,所有的无线数据收集在一个室内建筑大约,621带标签的数据收集在时间和3128无标签数据收集在时间B。
我们进行了一系列的实验,将TCA与一些基线进行比较,包括其他特征提取方法,如KPCA、样本选择偏置(或协变量移位)方法、KMM和KLIEP以及域自适应方法SCL。每次实验都使用源域中的所有标记数据和目标域中的一些未标记数据进行训练。然后对目标域中剩余的未标记数据(样本外)执行评估。该方法重复10次,平均性能用来衡量方法的泛化能力。此外,为了比较TCA和MMDE的性能,我们在转导设置上进行了一些实验[Nigam等,2000]。评价标准为试验数据的平均误差距离(AED),越低越好。为了确定每个方法的参数,我们随机选择目标域数据的一个非常小的子集来调优参数。所有实验的参数值都是固定的。
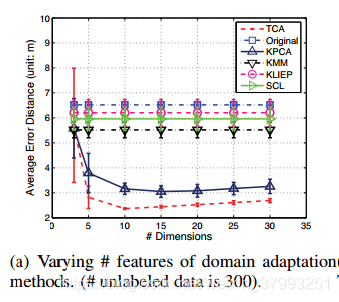
图1(a)比较了正则化最小二乘回归(RLSR)模型在TCA、KPCA和SCL学习的不同特征表示以及KMM和KLIEP学习的不同重加权实例上的性能。在这里,我们使用μ= 0.1 TCA和拉普拉斯算子的内核。可以看出,TCA和KPCA的新特性表示可以提高性能。TCA可以实现更高的性能,因为它的目标是找到将域之间的差异最小化的主要component。然后,从这些分量所占的空间中,利用在一个域中训练的模型在另一个域中进行准确的预测。
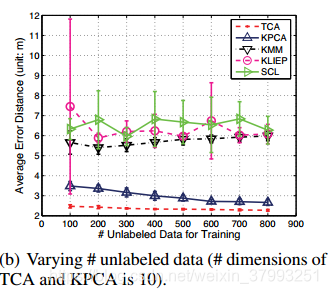
图1(b)显示了目标main中不同数量的未标记数据下的结果。可以看出,在目标域中只有少量未标记的数据时,TCA仍然可以找到一个很好的特征表示来在域之间架起桥梁。
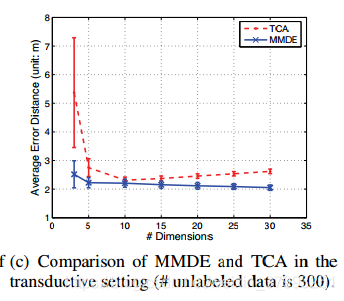
由于MMDE不能推广到样本外模式,为了将TCA与MMDE进行比较,我们在换能器设置下进行了另一系列实验,这意味着训练后的模型只对用于学习潜在空间的未标记数据进行评估。在图1(c)中,我们对来自源域和目标域中的300个未标记数据分别学习新的表示形式,然后对它们进行RLSR培训。不同训练数据的ACE比较结果如表1所示。

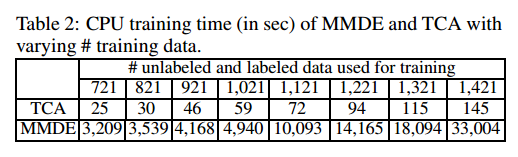
实验结果表明,在AED方面,TCA略高于MMDE。这是由于MMDE学习的非参数核矩阵能更好地拟合观测到的未标记数据。但是,正如第3.4节所提到的,由于计算密集型SDP, MMDE的成本非常昂贵。TCA与MMDE在WiFi数据集上计算时间的比较结果如表2所示。
5.2 Cross-domain Text Classification
在本节中,我们对Reuters-21578的预处理数据集进行跨域二分类实验。这些数据按层次结构分类。来自同一父类别下不同子类别的数据被认为来自不同但相关的域。任务是预测父类别的标签。按照此策略,构造了三个数据集org vs people、org vs places和people vs places。我们随机地从源域中选择50%的标记数据,从目标域中选择35%的未标记数据。评估基于对目标域中剩余65%的未标记数据的(样本外)测试。重复10次,并报告平均结果。
与WiFi定位的实验设置类似,我们进行了一系列的实验,将TCA与KPCA、KMM、KLIEP和SCL进行比较。这里使用支持向量机(SVM)作为分类器。评价标准为分类精度(越高越好)。利用RBF核和线性核分别对KPCA、TCA和KMM进行特征提取或重加权实验。最终预测的支持向量机中使用的内核是一个线性内核,和TCA的参数μ设置为0.1。
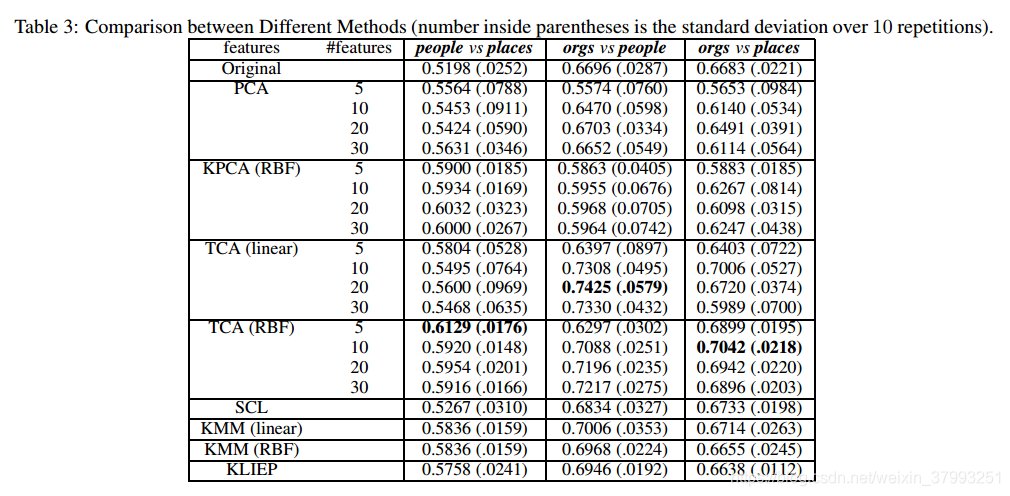
从表3可以看出,与WiFi数据的实验不同,KMM和KLIEP等样本选择偏倚方法在文本数据上的表现优于KPCA和PCA。然而,使用TCA学习的特征表示,SVM在跨领域分类中表现最好。这是因为TCA不仅发现了文本数据背后的潜在主题,而且还匹配了潜在主题所跨域的分布。此外,使用RBF核的TCA性能更加稳定。
6 Conclusion and Future Work
学习特征表示是Domain适应的一项重要任务。本文提出了一种新的特征提取方法——Transfer Component Analysis(TCA),该方法通过学习一组Transfer Component来减少RKHS中跨域的距离。与以前针对同一任务提出的MMDE相比,TCA具有更高的效率,可以推广到样本外模式。在两个实际数据集上的实验验证了该方法的有效性。在未来,我们计划在学习跨领域的Transfer Component时考虑边信息,这对于最终的分类或回归任务可能更好。

















 1380
1380

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









