







跳跃表简介
跳跃表(skiplist)是一种随机化的数据, 由 William Pugh 在论文《Skip lists: a probabilistic alternative to balanced trees》中提出, 跳跃表以有序的方式在层次化的链表中保存元素, 效率和平衡树媲美 —— 查找、删除、添加等操作都可以在对数期望时间下完成, 并且比起平衡树来说, 跳跃表的实现要简单直观得多。
以下是个典型的跳跃表例子(图片来自维基百科):
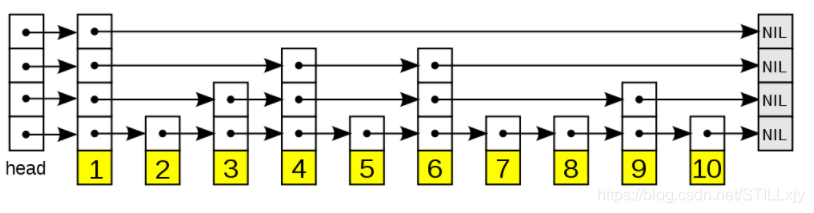
有序链表
如下图所有,有一个有序(按score从小到大排序)双向链表。当我们要在该链表中查找score = 13 的节点时,我们只能从链表的头节点开始,依次向下比较查找(图中红色箭头所示),需要访问7个节点,算法时间复杂度为 O(n)。

在上述链表中,虽然我们知道节点的排列是有序的,但是由于我们每次只能从一个节点访问到相邻的下一个节点,因此我们只能依次遍历每个节点进行查找。
优化
那么,要是有些节点存在不止一个可访问的后继节点呢?这样的话找查找时,我们就不必遍历每一个节点,而是可以跳跃的访问链表中的节点。
如下图所示,我们添加 L2 层访问指针,让其中一些节点不仅可以访问相邻的后继节点,还可以访问第二个后继节点。那么现在我们要查找 score = 13 的节点时,可以先在 L2层上向后查找到可以到达的最右节点 11(score <= 13),然后在 forward 层(也可以称为 L1层)上向后查找,最后找到 score = 13的节点需要访问4个节点。速度快了一倍!!!

所以,要是我们能够在节点上继续往上添加更高层的访问指针(层数越高,节点的跨度越大),那么查找的速度会越来越快,到达 log级别。
跳跃表
跳跃表就是遵循了上述的优化思想,让每个节点拥有一个指针数组,使它们能够进行多级的跳跃,从而将查找的时间复杂度降低为O(log n)。
跳跃表节点的定义:
typedef struct zskiplistNode {
robj *obj;
double score;
struct zskiplistNode *backward; //后向指针
struct zskiplistLevel {
struct zskiplistNode *forward;//每一层中的前向指针
unsigned int span;//x.level[i].span 表示节点x在第i层到其下一个节点需跳过的节点数。注:两个相邻节点span为1
} level[];
} zskiplistNode;
用图像表示就是这样:
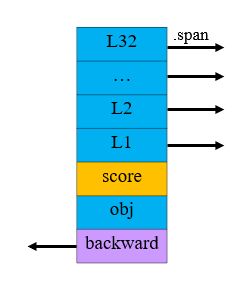
其中,我们将指针数组的最大长度设置为32。多个zskiplistNode就组成了一个跳跃表。
我们使用zskiplist数据结构来表示跳跃表:
#define ZSKIPLIST_MAXLEVEL 32 //最大层数
#define ZSKIPLIST_P 0.25 // 1/P
typedef struct zskiplist {
struct zskiplistNode *header, *tail; //头节点, 尾节点
unsigned long length;//节点总数
int level;//总层数
} zskiplis
随机算法
跳跃表中,每个节点的指针数组长度是不一样的,是一个在[1,32]之间的随机整数,随机算法如下:
int zslRandomLevel(void) {
int level = 1;
// TODO 了解这个公式背后的数学原理
while ((random()&0xFFFF) < (ZSKIPLIST_P * 0xFFFF))
level += 1;
return (level<ZSKIPLIST_MAXLEVEL) ? level : ZSKIPLIST_MAXLEVEL;
}
使用随机算法,在概率上可以保证上一层的节点数为下一层的1/P。那么SkipList可以看成是一棵平衡的P叉树,从最顶层开始查找某个节点需要的时间是O(logpN)。
每个跳跃表节点中的指针数组中的每一层,都指向随后一个指针数组大小大于等于该节点指针数据大小的节点。
一次典型的跳跃表查询过程
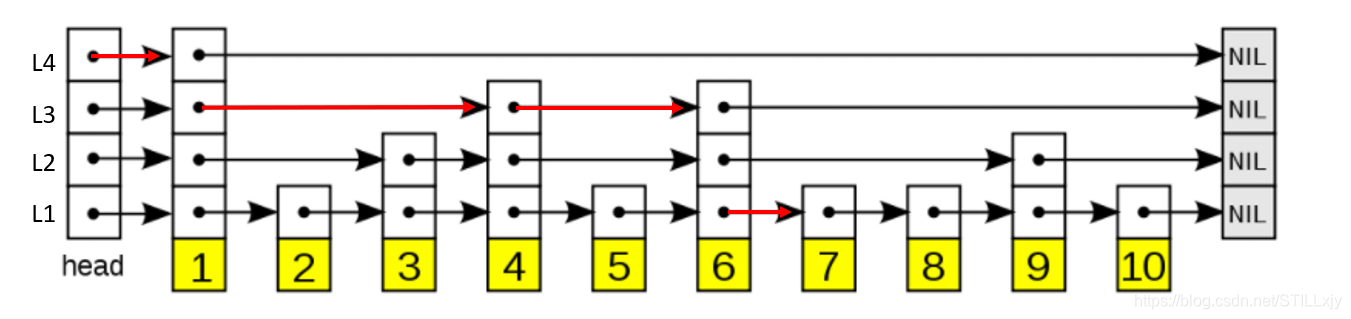
如上图所示,在上述跳跃表中查找 score = 7的节点过程为:
- 在L4层上找到满足条件(score <= 7)的最右节点 1,1 < 7 所以继续向下层查找。
- 在L3层上找到满足条件(score <= 7)的最右节点 6,6 < 7 所以继续向下层查找。
- 在L2层上找到满足条件(score <= 7)的最右节点 6,6 < 7 所以继续向下层查找。
- 在L1层上找到满足条件(score <= 7)的最右节点 7,7 = 7 查找完毕。














 604
604











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









