







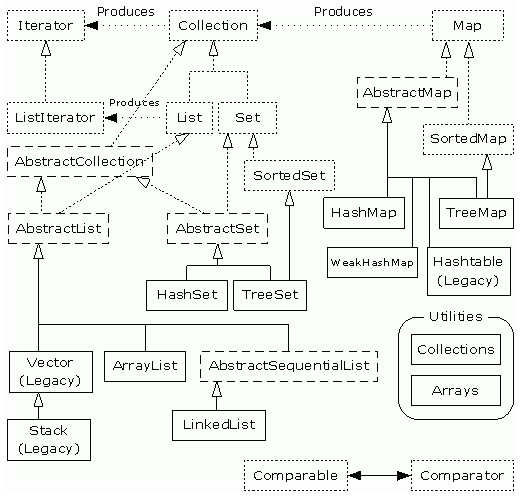
集合解析:
Collection接口:
—List子接口:
—特点:
1.元素可重复。
2.元素有序(指存入元素的顺序与取出元素的顺序一致)
3.操作基于索引
—常见子类:
—ArrayList类:
—-底层实现:数组
—-特点:
1.数组容量自动增长。
(通过ensureCapacity()方法来扩展容量。
每次新容量为原容量的1.5倍加1.
)
2.线程不同步。因此效率较高,但安全性较低。
3.查找效率高,插入删除元素的效率低。
(数组的特性:每次插入删除都需移动大量数据)
4.ArrayList中允许元素为null。
5.实现了Serializable接口,支持序列化
6.初始容量为10.
—LinkedList类:
—-底层实现:双向循环链表
—-特点:
1.线程不同步。因此效率较高,但安全性较低。
2.插入删除元素效率高,查找的效率低。
(基于链表的特性:查找时需遍历,而删除时只需更改前后引
用)
3.LinkedList中允许元素为null。
4.实现了Serializable接口,支持序列化
—Set子接口:
—-特点:
1.元素不可重复。
2.无序(指存入元素的顺序与取出元素的顺序不一致)
3.Set内部也是采用的是Map来实现的,但是键值相同。
—-常见子类:
—HashSet:
—-底层实现:哈希表。(Map集合中的HashMap)
—-特点:
1.线程不同步。
2.无序(指存入元素的顺序与取出元素的顺序不一致)。
3.元素不重复。
—如何保证元素不重复?
当向HashSet中插入元素时,首先通过调用hashcode()方法来计算元素的Hashcode的值,再根据这个值计算出存储元素的位置。如果这个位置为空,就直接把元素添加进去。否则,遍历当前链表,用equal()方法进行比较,如果key重复,则替换并返回旧值。
—–LinkHashSet:
—特点:
类似与HashSet,但它是有序的。
(指存入元素的顺序与取出元素的顺序一致)。
—–TreeSet:
—底层实现:红黑树。(Map集合中的TreeMap)
—特点:
1.无序。(指存入元素的顺序与取出元素的顺序不一致)。
2.线程不同步。
3.可对集合中的元素进行排序。
—Map子接口:
—-特点:1.存储的是键值队。
2.无迭代器。
3.一个映射中不能包含重复的键,每个键最多映射到一个值。
4.无序。(指存入元素的顺序与取出元素的顺序不一致)。
—重点方法:
1.keySet()方法:
返回map集合中所有的键所在的Set集合。
可通过Set集合的迭代器获取map中所有的元素。
2.entrySet()方法:
返回map集合中的映射关系的Set集合。
该映射关系类型为Map Entry。
—常见子类:
—-HashMap类
底层实现:哈希表。
存储结构:
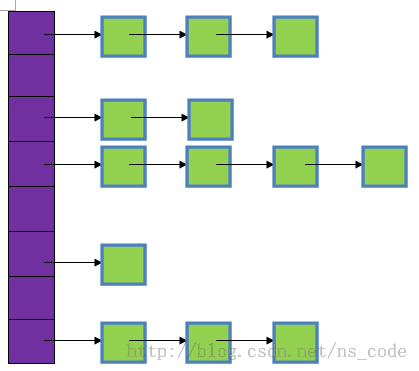
紫色部分是哈希数组,数组的每个元素都是一个单链表的头节点,链表是用来解决冲突的,如果不同的key映射到了数组的同一位置处,就将其放入单链表中
特点:1.key与value可为null值。
2.需通过hashcode方法与equal方法来保证键值队的唯一。
3.新元素的插入位置都是单链表的头结点。
4.不同步,非线程安全。
构造时所需的参数:
1.初始容量
哈希数组的长度。(默认为16)
2.加载因子(默认为0.75)
加载因子是一种用来度量哈希表多满的尺度。
如果加载因子越大,对空间的利用更充分,但是查找效
率会降低(链表长度会越来越长);如果加载因子太小,
那么表中的数据将过于稀疏(很多空间还没用,就开始
扩容了),对空间造成严重浪费。
扩容(resize方法):
每次加入键值对时,都要判断当前已用的槽的数目是否大于等
于阀值(容量*加载因子),如果大于等于,则进行扩容,将容
量扩为原来容量的2倍。
每次扩容,都需在底层新建了一个HashMap的数组,在把原集
合中的元素转移,需重新计算元素在新的数组中的索引位置。
该操作相当耗时,故应当预估所需的空间。
—-Hashtable类(该类极其类似于HashMap)
底层实现:哈希表。
存储结构:和HashMap类似。
特点:1.线程安全。
2.key和value都不允许为null。
3.HashTable在不指定容量的情况下的默认容量为1
4.Hashtable扩容时,将容量变为原来的2倍加1
—-TreeMap类
底层实现:红黑树
特点:1.线程不安全。
2.可对集合中的元素进行排序。
3.集合是根据key值进行排序的。
4..key和value都不允许为null。
—如何实现排序?
—第一种方法:
集合中的元素需实现comparable接口,并实现compareTo()
方法。
—第二种方法:
定义一个比较器类实现Comparator接口,并实现compare()
方法。再把该类传给TreeSet集合。
—如何实现元素不重复?
通过上述的比较方法来实现该功能。如果两元素相等,则舍弃其
中一个。
Iterator接口(迭代器):
迭代器是一种模式,它可以使得对于序列类型的数据结构的遍历行为与被遍历的对象分离,即我们无需关心该序列的底层结构是什么样子的。只要拿到这个对象,使用迭代器就可以遍历这个对象的内部.它必须依赖于具体容器,因为每个容器的数据结构不同,所以该迭代器对象是在容器内部实现的。
常见方法:
(1) 使用方法iterator()要求容器返回一个Iterator。
(2) 使用next()获得序列中的下一个元素。
(3) 使用hasNext()检查序列中是否还有元素。
(4) 使用remove()将迭代器新返回的元素删除。
注意:
1.集合与迭代器同时操作内容时,会出现异常。
2.Map集合无迭代器。
3.为了克服1的缺点,特意为List集合实现了ListIterator接口,使List集合可同时
遍历与修改内容。
集合工具类
Collections类:
Collections则是集合类的一个工具类/帮助类,其中提供了一系列静态方法,用于对集合中元素进行排序、搜索以及线程安全等各种操作。
常见方法:
1. 排序(Sort):元素都必须实现 Comparable 接口
2. 混排(shuffle):打乱List集合中元素的顺序。
3. 最大值(max),最小值(min)。
4. Fill:使用指定元素替换指定列表中的所有元素。
5. 一系列返回线程安全集合的方法。
Arrays类:
常用方法:
public static List asList(T… a):将数组变成List集合。
注意:
1.将数组变成集合,不可以使用集合的增删方法,因为数组的长度是固定的。
2.如果数组中的元素都是对象,变成集合时,数组中的元素就直接转换成集合
中的元素。
3.如果数组中的元素都是基本数据类型,变成集合时,会将该数组作为集合中
的元素存在。















 7408
7408

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









