







转自:http://blog.csdn.net/lc013/article/details/55656512
这次需要总结的是朴素贝叶斯算法,参考文章:
简介
朴素贝叶斯是基于贝叶斯定理与特征条件独立假设的分类方法。
贝叶斯定理是基于条件概率来计算的,条件概率是在已知事件B发生的前提下,求解事件A发生的概率,即
P(A|B)=P(AB)P(B)
,而贝叶斯定理则可以通过
P(A|B)
来求解
P(B|A)
:
其中分母 P(A) 可以根据全概率公式分解为: P(A)=∑ni=1P(Bi)P(A|Bi)
而特征条件独立假设是指假设各个维度的特征
x1,x2,...,xn
互相独立,则条件概率可以转化为:
朴素贝叶斯分类器可表示为:
而由于对上述公式中分母的值都是一样的,所以可以忽略分母部分,即可以表示为:
这里 P(yk) 是先验概率,而 P(yk|x) 则是后验概率,朴素贝叶斯的目标就是最大化后验概率,这等价于期望风险最小化。
参数估计
极大似然估计
朴素贝叶斯的学习意味着估计 P(yk) 和 P(xi|yk) ,可以通过极大似然估计来估计相应的概率。

如上图所示,分别是 P(yk) 和 P(xi|yk) 的极大似然估计。
当求解完上述两个概率,就可以对测试样本使用朴素贝叶斯分类算法来预测其所属于的类别,简单总结的算法流程如下所示:
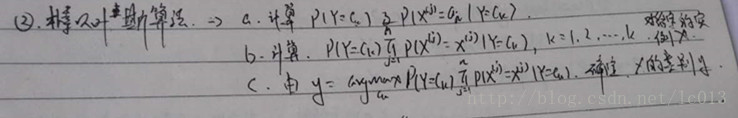
贝叶斯估计/多项式模型
用极大似然估计可能会出现所要估计的概率值为0的情况,这会影响到后验概率的计算,使分类产生偏差。解决这个问题的办法是使用贝叶斯估计,也被称为多项式模型。
当特征是离散的时候,使用多项式模型。多项式模型在计算先验概率
P(yk)
和条件概率
P(xi|yk)
时,会做一些平滑处理,具体公式为:
N 是总的样本个数, k 是总的类别个数, Nyk 是类别为 yk 的样本个数, α 是平滑值。
Nyk 是类别为 yk 的样本个数, n 是特征的维数, Nyk,xi 是类别为 yk 的样本中,第 i 维特征的值是 xi 的样本个数, α 是平滑值。
当 α=1 时,称作Laplace平滑,当 0<α<1 时,称作Lidstone平滑,α=0时不做平滑。
如果不做平滑,当某一维特征的值 xi 没在训练样本中出现过时,会导致 P(xi|yk)=0 ,从而导致后验概率为0。加上平滑就可以克服这个问题。
高斯模型
当特征是连续变量的时候,运用多项式模型会导致很多 P(xi|yk)=0 (不做平滑的情况下),即使做平滑,所得到的条件概率也难以描述真实情况,所以处理连续变量,应该采用高斯模型。
高斯模型是假设每一维特征都服从高斯分布(正态分布):
μyk,i 表示类别为 yk 的样本中,第 i 维特征的均值;
σ2yk,i 表示类别为 yk 的样本中,第 i 维特征的方差。
伯努利模型
与多项式模型一样,伯努利模型适用于离散特征的情况,所不同的是,伯努利模型中每个特征的取值只能是1和0(以文本分类为例,某个单词在文档中出现过,则其特征值为1,否则为0).
伯努利模型中,条件概率 P(xi|yk) 的计算方式是:
当特征值 xi 为1时, P(xi|yk)=P(xi=1|yk) ;
当特征值 xi 为0时, P(xi|yk)=1−P(xi=1|yk) ;
工作流程
- 准备阶段
确定特征属性,并对每个特征属性进行适当划分,然后由人工对一部分待分类项进行分类,形成训练样本。 - 训练阶段
计算每个类别在训练样本中的出现频率及每个特征属性划分对每个类别的条件概率估计 - 应用阶段
使用分类器进行分类,输入是分类器和待分类样本,输出是样本属于的分类类别
属性特征
- 特征为离散值时直接统计即可(表示统计概率)
- 特征为连续值的时候假定特征符合高斯分布,则有
优缺点
优点
- 对小规模的数据表现很好,适合多分类任务,适合增量式训练。
缺点
- 对输入数据的表达形式很敏感(离散、连续,值极大极小之类的)。
代码实现
下面是使用sklearn的代码例子,分别实现上述三种模型,例子来自朴素贝叶斯的三个常用模型:高斯、多项式、伯努利。
下面是高斯模型的实现
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
多项式模型如下:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
值得注意的是,多项式模型在训练一个数据集结束后可以继续训练其他数据集而无需将两个数据集放在一起进行训练。在sklearn中,MultinomialNB()类的partial_fit()方法可以进行这种训练。这种方式特别适合于训练集大到内存无法一次性放入的情况。
在第一次调用partial_fit()时需要给出所有的分类标号。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
伯努利模型如下:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
朴素贝叶斯的总结就到这里为止。















 344
344

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









