







分享一下最近遇到的 Yarn 集群故障的问题,主要还是自己没有深入研究 Yarn 的相关参数导致的,分享给大家,避免出现一样的问题。
1 背景
51 假期回来发现集群上好多任务,Yarn 集群资源占用率到了 90%,并且很多任务都是 ACCEPT 状态根本分配不到资源来跑。到这就去检查集群上的任务,看看是不是有人乱申请资源提交任务,看了一圈也没发现有什么异常,去 CDH 上看了一下,发现 Hdfs 服务很多红色告警,都是提示磁盘空间不足(其实也在做数据冷备出库,但是一直没降下来),也没在意想着 Hdfs 有问题也不关 Yarn 的事啊。
后来去 Yarn 的管理界面一看,怎么集群的内存和 CPU 资源都那么低,只有 5T 的内存了???再一细看 Yarn 竟然很多节点都掉线了,怪不得很多任务分配不到资源。

点进去看一下,掉线的这些节点,提示 local-dirs useable space is below configured utilization pertencentage /no more useable space 如下图
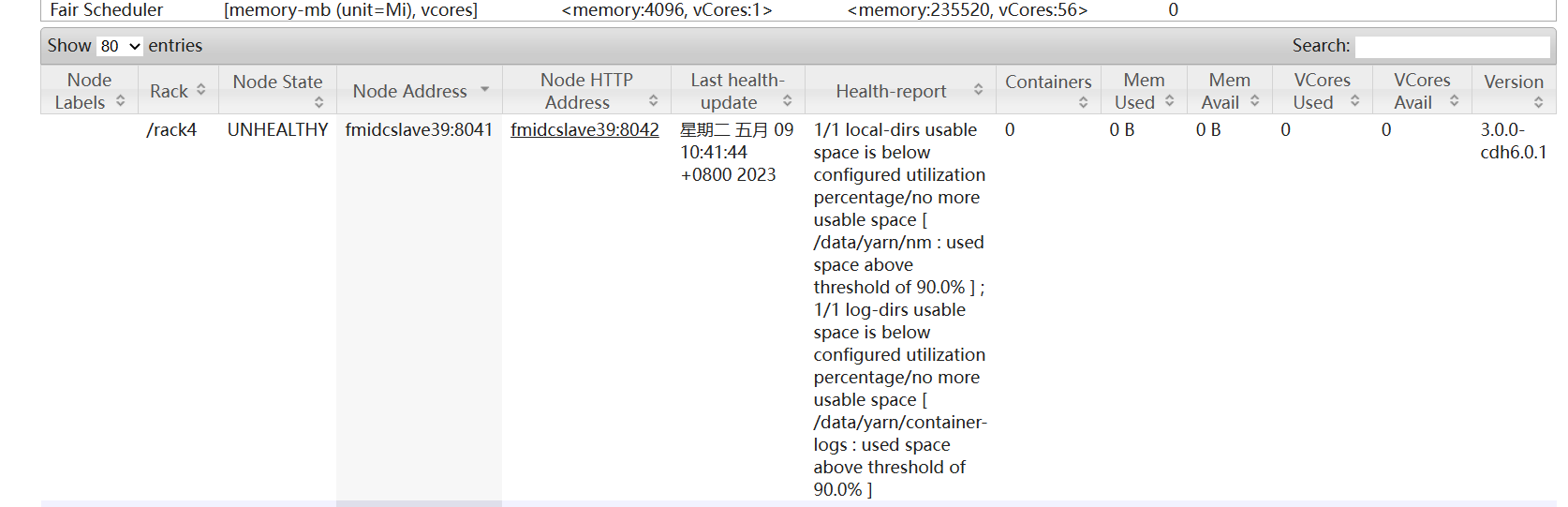
去官网看了下 Yarn 的参数,有一个 yarn.nodemanager.disk-health-checker.max-disk-utilization-per-disk-percentage 用来检查磁盘健康度的,当磁盘使用率超过了默认值 90%,Yarn 就认为磁盘故障,进而使节点下线,导致集群上的 CPU 和内存资源不足。
The maximum percentage of disk space utilization allowed after which a disk is marked as bad. Values can range from 0.0 to 100.0. If the value is greater than or equal to 100, the nodemanager will check for full disk. This applies to yarn.nodemanager.local-dirs and yarn.nodemanager.log-dirs.

2 解决
看到这之后,迅速去集群上看了下,缺失是很多节点的磁盘使用率已经超过了 90%,赶紧清了一波临时文件和一些 flume 上传的文本文件,节点都恢复过来了。
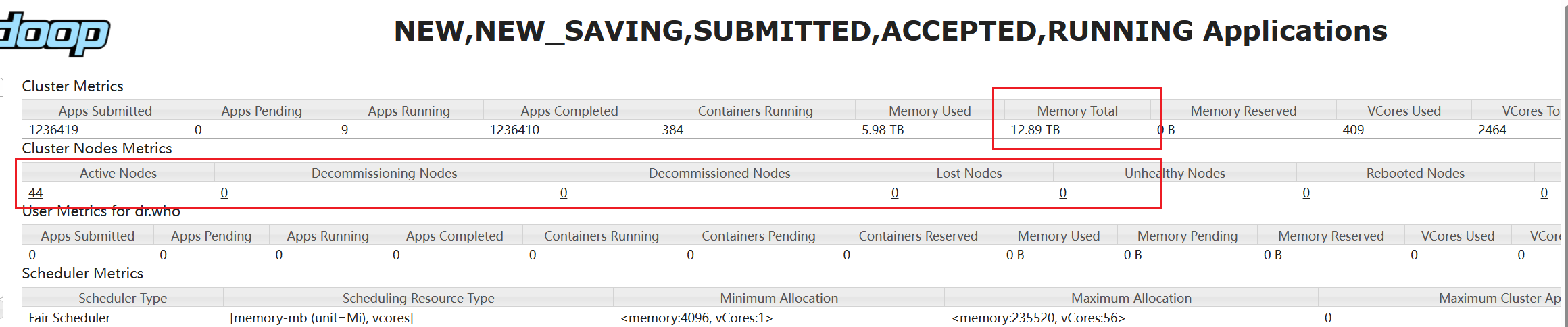
后续计划,加快冷数据出库进度,集群存储使用率控制在 70% 左右。
当然修改上面提到的参数并且重启集群也可以解决这个问题,但是不建议这么做,因为集群空间占用达到 90% 以上确实是比较危险的了,建议大家一定要控制好集群的资源,如果实在无法清理出足够的空间,就要考虑对集群进行扩容了。















 1617
1617

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









