







1 故障概述
最近使用 HUE 的时,在浏览 hdfs 文件切换目录的时候,经常会出现卡住的现象,点进某个目录就一直转圈圈,并且 Yarn 上的任务跑的也很慢。
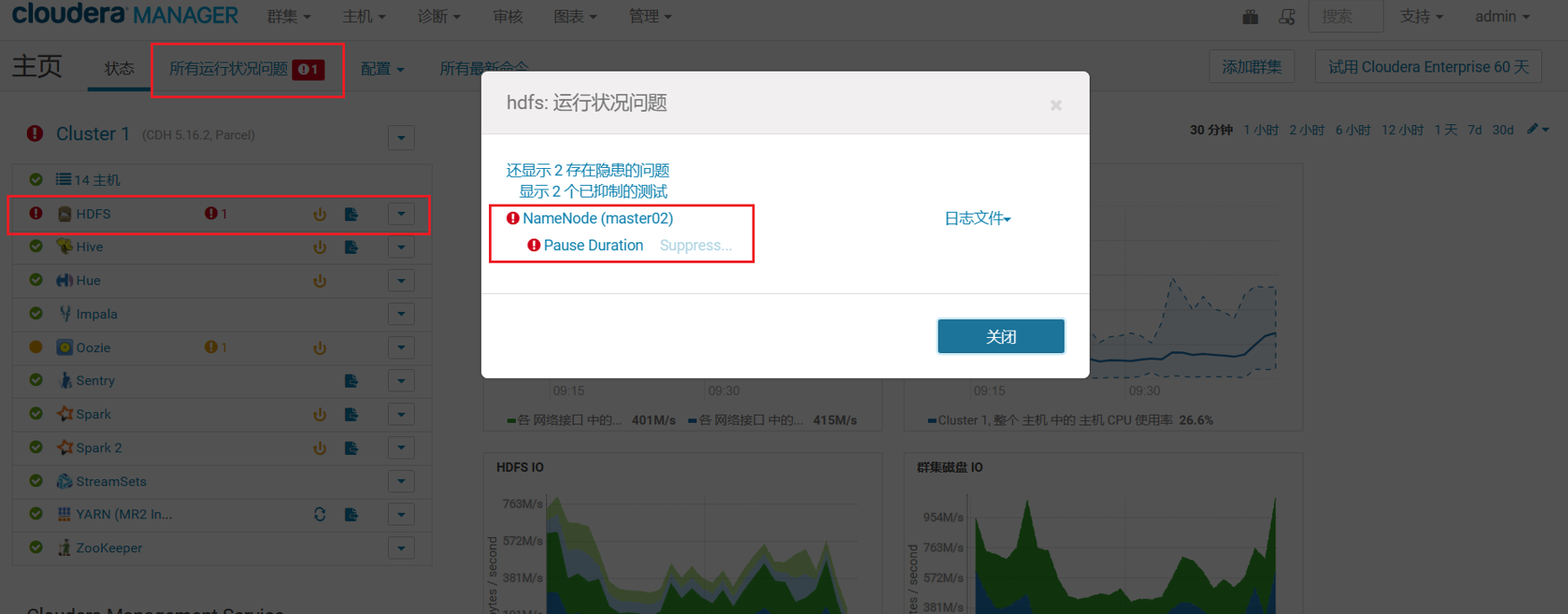
出现这种情况怀疑是集群出现什么问题了,于是通过 CDH 管理界面查看,果然存在一个异常,描述信息是暂停持续时间,在前 5 分众内暂停所花的平均时间是每分钟 37.8秒(63.00%)。临界阈值:60%
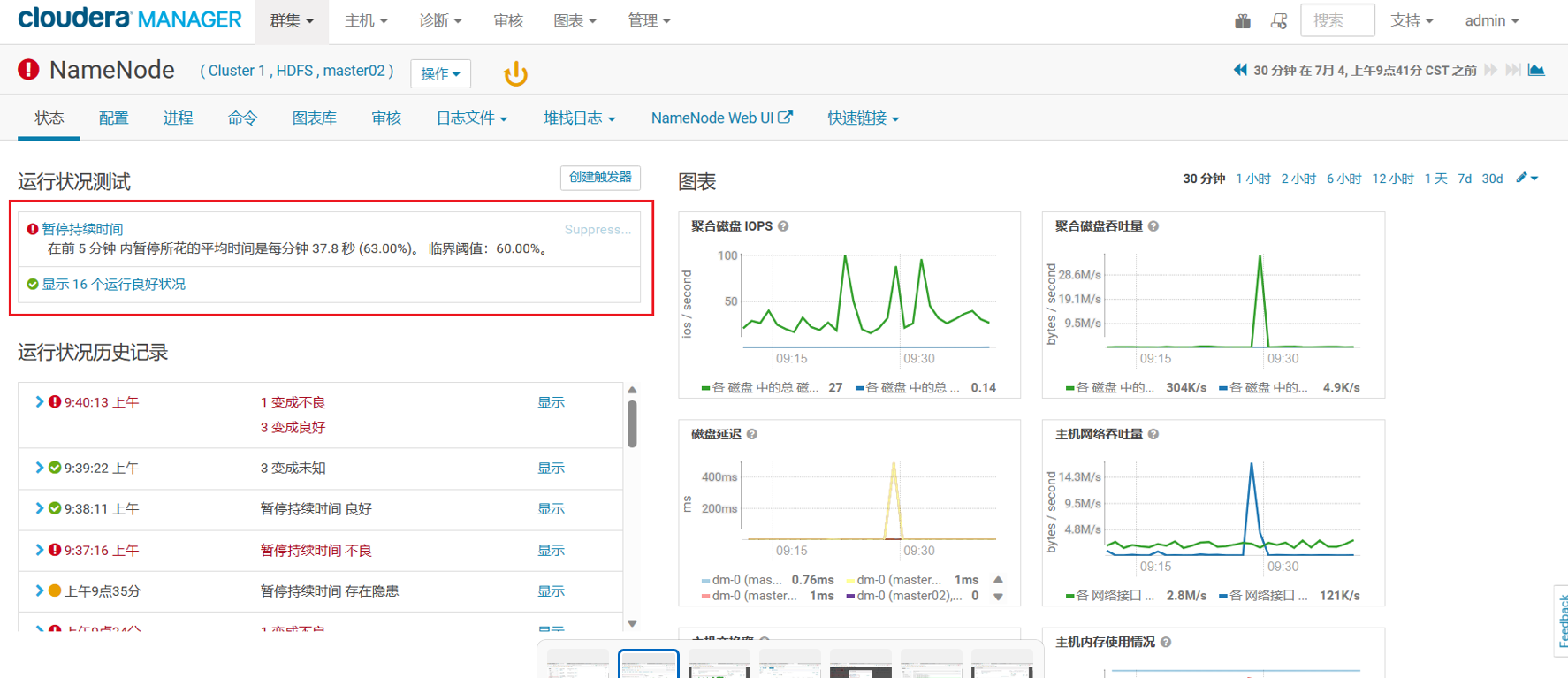
因为 Namenode 也是基于 JVM 实现的,这种情况一般都是(堆)内存不够,hdfs 使用过程中存储的文件越来越多,占用的内存也就越来越大。默认情况下 namenode 堆内存分配仅 4g,很快就占满了,看了一下 cdh 上namenode 堆内存的使用图确实只分配了 4g,JVM 的堆内存监控也确实出现了中断问题。
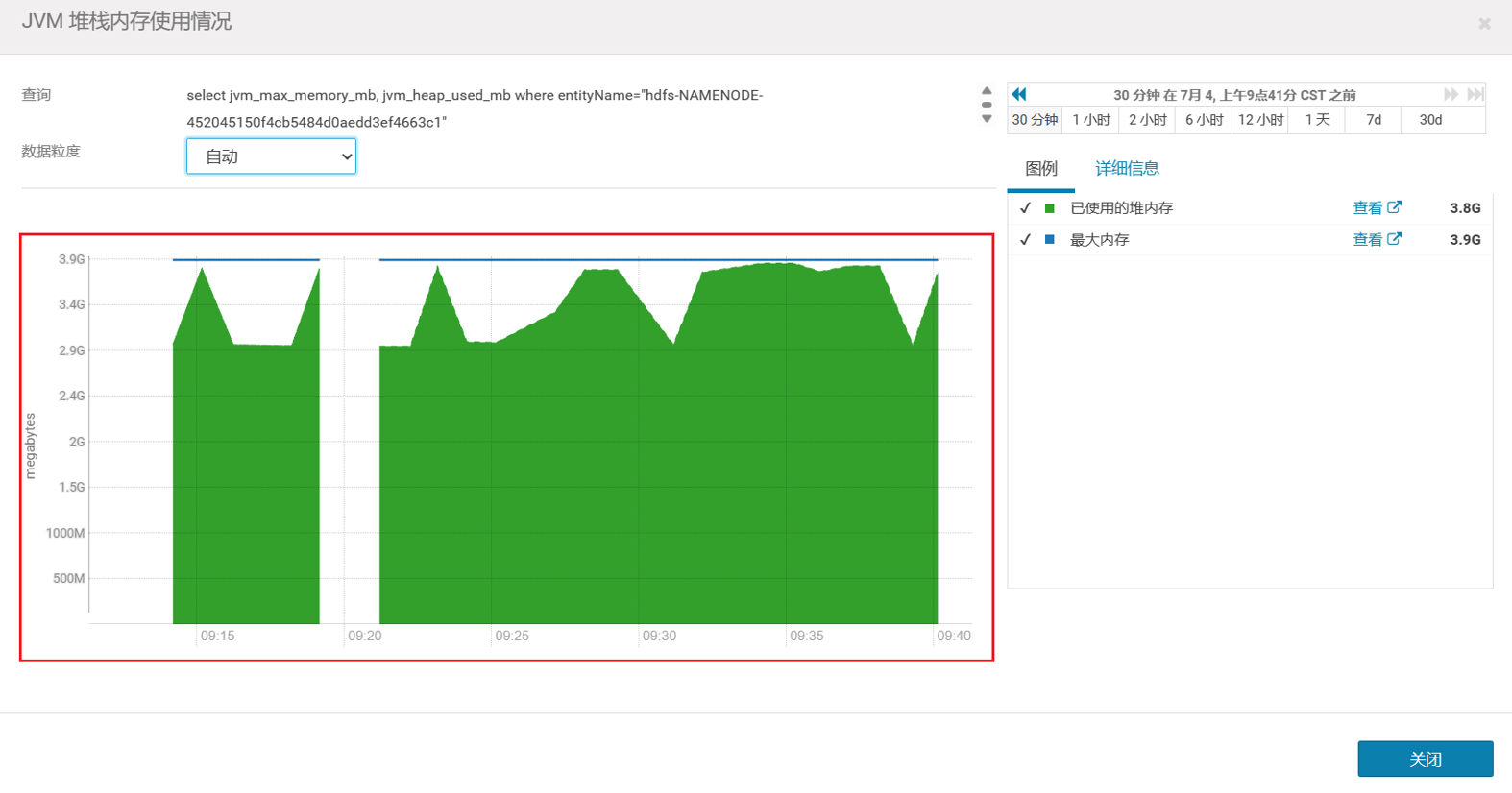
不使用 cdh 管理集群的,也可以使用 Jdk 带的命令来查看 namenode 的内存占用,也可以看到 namenode 的堆内存信息。
[root@master02 ~]# jps
4352 Bootstrap
26946 ResourceManager
5828 RunJar
27604 RunJar
28997 Bootstrap
4279 DFSZKFailoverController
26617 Jps
27610 RunJar
29003 HistoryServer
28157 NameNode
4687
[root@master02 ~]# jmap -heap 28157
Attaching to process ID 28157, please wait...
Debugger attached successfully.
Server compiler detected.
JVM version is 25.201-b09
using parallel threads in the new generation.
using thread-local object allocation.
Concurrent Mark-Sweep GC
Heap Configuration:
MinHeapFreeRatio = 40
MaxHeapFreeRatio = 70
MaxHeapSize = 4294967296 (4096.0MB)
NewSize = 1134100480 (1081.5625MB)
MaxNewSize = 1134100480 (1081.5625MB)
OldSize = 3160866816 (3014.4375MB)
NewRatio = 2
SurvivorRatio = 8
MetaspaceSize = 21807104 (20.796875MB)
CompressedClassSpaceSize = 1073741824 (1024.0MB)
MaxMetaspaceSize = 17592186044415 MB
G1HeapRegionSize = 0 (0.0MB)
Heap Usage:
New Generation (Eden + 1 Survivor Space):
capacity = 1020723200 (973.4375MB)
used = 889337712 (848.1385345458984MB)
free = 131385488 (125.29896545410156MB)
87.12819616522873% used
Eden Space:
capacity = 907345920 (865.3125MB)
used = 889337712 (848.1385345458984MB)
free = 18008208 (17.173965454101562MB)
98.01528748815005% used
From Space:
capacity = 113377280 (108.125MB)
used = 0 (0.0MB)
free = 113377280 (108.125MB)
0.0% used
To Space:
capacity = 113377280 (108.125MB)
used = 0 (0.0MB)
free = 113377280 (108.125MB)
0.0% used
concurrent mark-sweep generation:
capacity = 3160866816 (3014.4375MB)
used = 3160866816 (3014.4375MB)
free = 0 (0.0MB)
100.0% used
26383 interned Strings occupying 2608240 bytes.
2 解决方案
既然是 namenode 的堆内存太小,那就调大即可,在 cdh 的管理界面调整 hdfs 的配置,点击 hdfs -> 配置 找到如下资源配置项,修改为合适的大小即可(我这里主机是 64g 的,并且平时有很多的空闲内存,所以分了一半给到 namenode)。
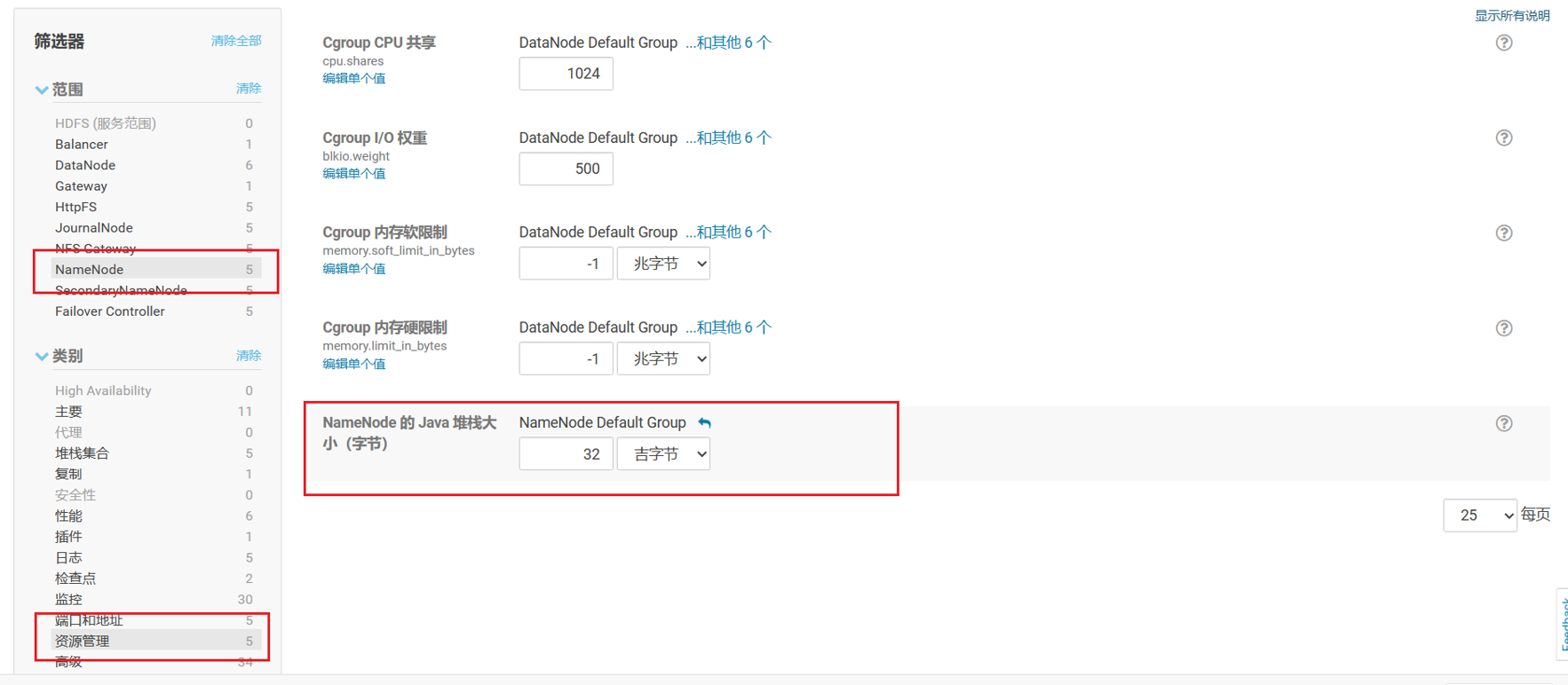
修改完成后,点击保存更改,然后重启集群并且勾选重新部署客户端配置即可。注意重启集群时比较重量级的操作,因为需要重启 hdfs 所以上层的所有应用都需要跟着重启,所以一定要规划好时间,并且那些持续向 hdfs 输出文件的任务(如 flume,Streamsets,Maxwell 等)最好也先暂停,之后再启动。
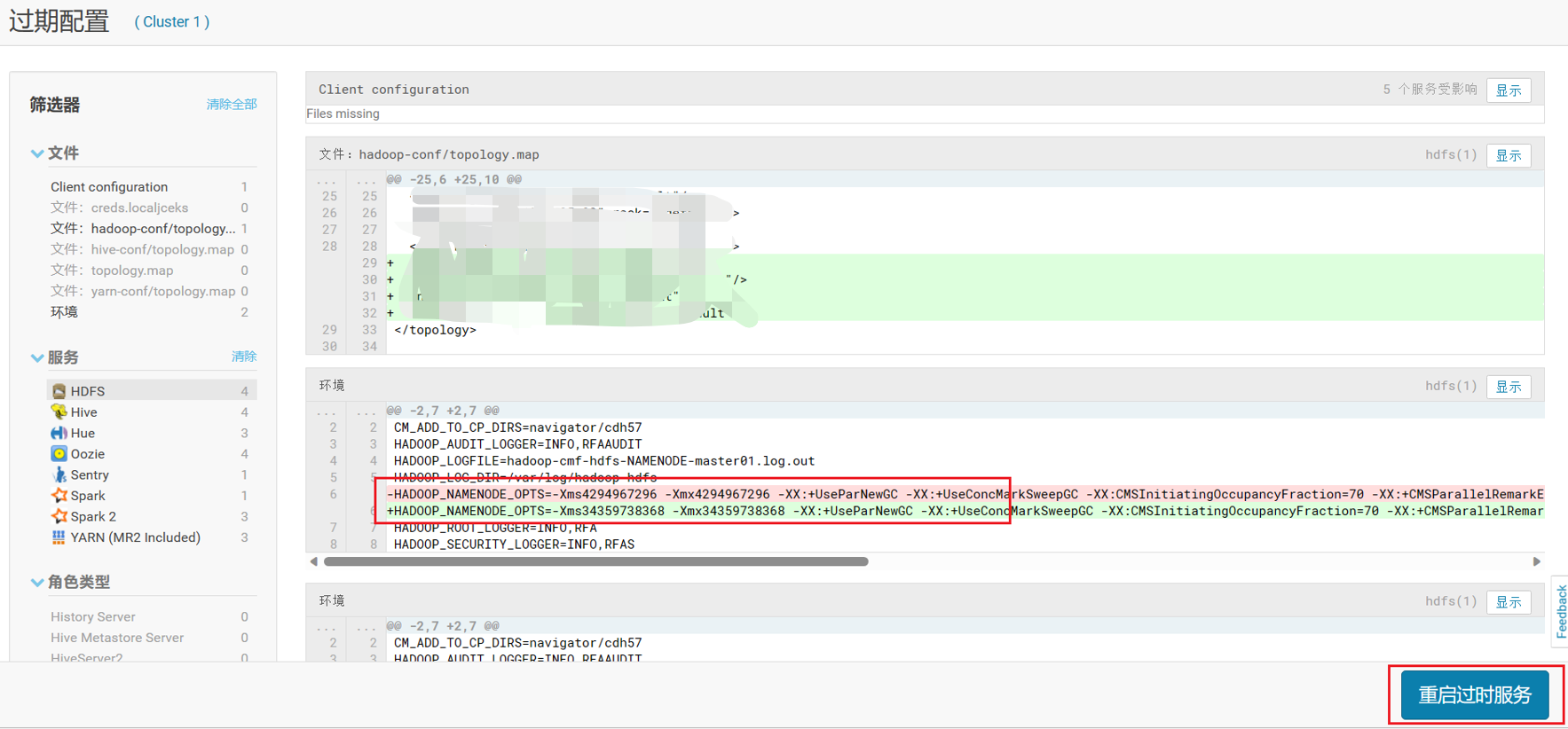
重启时看一下配置参数:
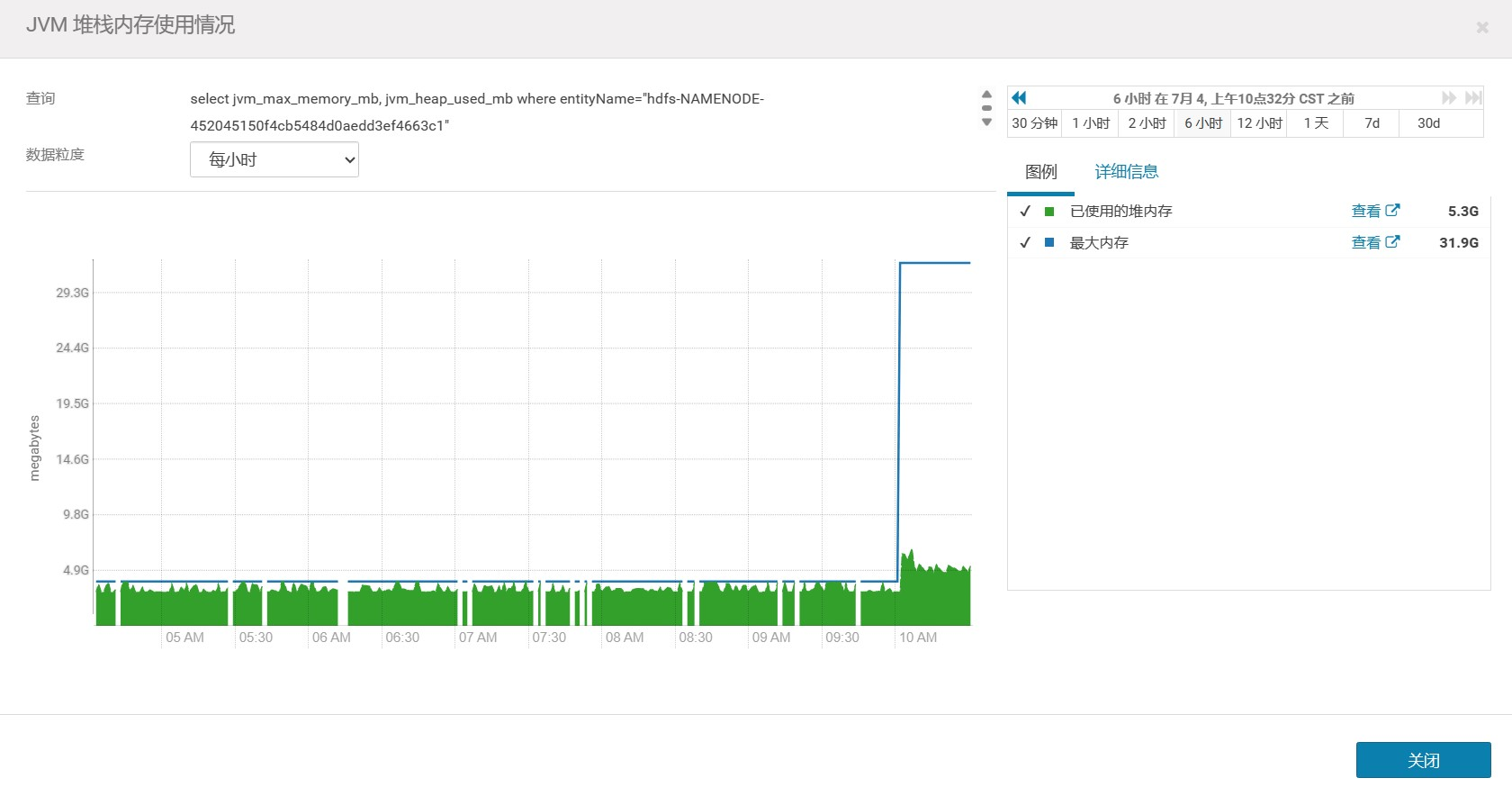
重启完成之后再看看 JVM 的堆内存信息,可以看到最大堆内存已经变为 32g,并且之前的那种暂停情况也消失了。
对于非 CDH 的集群,需要修改 $HADOOP_HOME/conf/hadoop-env.sh 增加如下配置,也可以完成堆内存的调整,具体数值根据自身的主机调整。
export HADOOP_NAMENODE_OPTS="-Xms34259738368 -Xmx34259738368 $HADOOP_NAMENODE_OPTS"















 621
621

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









