







一、hadoop简介
1.历史
2004年,Apache在google的云计算系统GFS的基础上编写的一个分布式计算框架,经过不断地发展完善形成了今天的hadoop
2.功能
hadoop是一个能够对大数据进行可靠的分布式处理的可扩展开源软件框架,应用于大量低成本计算机构成的分布式运算环境。在确保容错能力的情况下,依然能够以并行的方式工作,极大地加快了计算速度。
二、hadoop的模块组成
1.Hadoop Common
Hadoop Common项目为Hadoop整体架构提供基础支撑性功能,主要包括文件系统(FileSystem)、远程过程调用协议(RPC)和数据串行化库(Serilaliztion Libaries)。
一般来说hadoop common对编程人员透明,在大数据计算中主要关注HDFS和MapReduce的交互。
2.HDFS
#1 介绍
HDFS(Hadoop Distributed File System)是Hadoop中的分布式文件系统,具有低成本、高可靠性、高吞吐量的特点。
#2 组件
(1) NameNode:NameNode是系统中的管理者,负责管理文件系统的命名空间,维护文件系统的文件树,存储各数据的元数据信息以及各block分块的所在DateNode位置。
(2) Secondery NameNode:NameNode的备用结点,由于NameNode单点机制容易出现故障,为确保系统稳定,Secondery NameNode独立占据一台物理机,并保持与NameNode通信,当NameNode出现故障时,由人工切换。
SecondeyNameNode是Hadoop 1.0版本的组件,2.0之后被另一个处于standby状态的NameNode所取代。2.0定义了两个NameNode结点以及两种NameNode状态,active和standby。同一时间只有一个NameNode结点(处于active状态)进行工作,同时,两个NameNode会保持通信以保持数据一致,当出现故障时,由差错处理模块(如:Zookeeper)直接改变结点状态,完成两个NameNode的实时切换。
(3)DataNode:DateNode是HDFS文件系统中保存数据的结点。HDFS中的文件存储的文件一般被分割成多个块(block)进行存储,并且为确保系统具备容错性,每个块会被重复存储(冗余备份)到多个不同的DateNode中,DateNode还会定期向NameNode报告其存储的数据块信息。

HDFS基本架构
3.MapReduce
#1 介绍
MapReduce是hadoop中的编程模型和软件框架,用于在大规模计算集群上编写对大数据进行快速处理计算的并行化程序
#2 组件
(1).JobClient:jobClient是基于MapReduce接口编写的客户端程序,负责提交MapReduce作业。
(2).JobTracker:JobTracker主要负责资源监控和作业调度。JobTracker监控所有TaskTracker与作业的健康状况,一旦发现失败情况后,会将相应的任务转移到其他节点;同时,JobTracker会跟踪任务的执行进度、资源使用量等信息,并将这些信息告诉任务调度器,而调度器会在资源出现空闲时,选择合适的任务使用这些资源。在hadoop中,任务调度器是一个可插拔的模块,用户可以根据自己的需要设计相应的调度器。
(3)TaskTracker:TaskTracker负责执行由JobTracker分配的任务,每个TaskTracker可以启动一个或多个Map或Reduce任务。同时TaskTracker与JobTracker之间通过心跳(HeartBeat)机制保持通信,以维护整个集群的正常工作。
(4)MapTask与ReduceTask:MapTask与ReduceTask是由TaskTracker启动的负责执行Map任务和Reduce任务的程序。
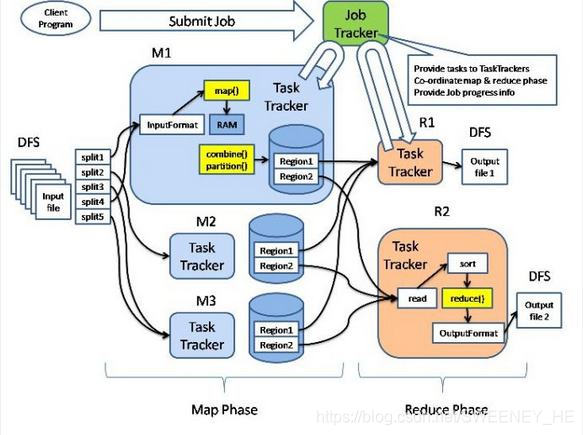
MapReudce运行机制图
Hadoop运行机制如图所示:
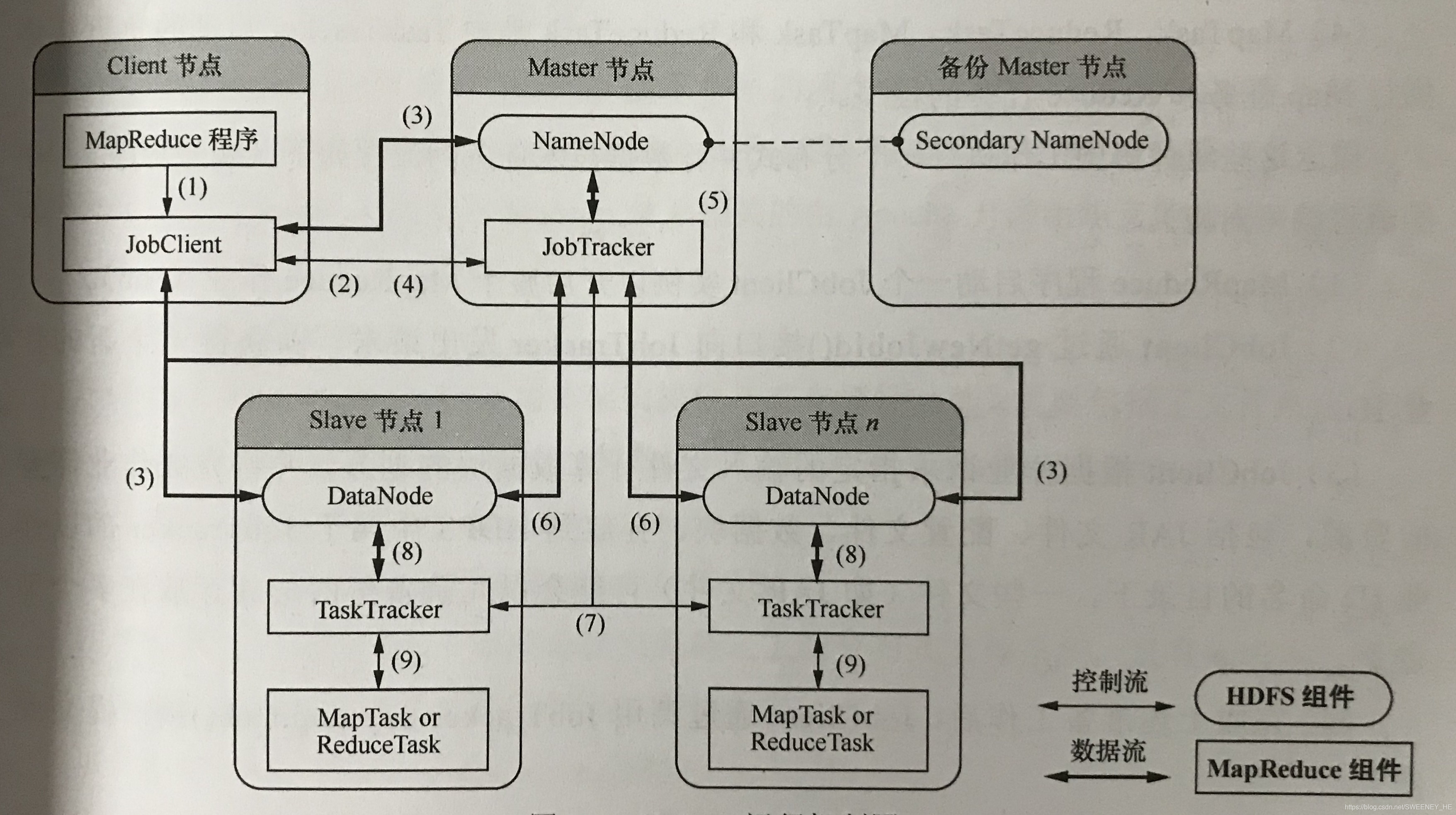
Hadoop1.0版本运行机制图

















 897
897

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









