







不同点:
顺序表和链表是两种常见的数据结构,他们的不同点在于存储方式和插入、删除操作、随机访问、cpu缓存利用率等方面。
一、存储方式不同:
顺序表:
顺序表的存储方式是顺序存储,在内存中申请一块连续的空间,通过下标来进行存储;
链表:
链表的存储方式是链式存储,申请的空间是未必连续的,以节点的形式连接,每个节点会有一个next指针,指向下一个节点,通过指针来访问元素;
二、插入、删除的效率不同:
顺序表:
插入删除元素时,需要移动元素的位置也就是搬移元素,导致效率低下
链表:
插入删除时只需要修改指针指向。
三、内存利用率:
顺序表:
需要扩容,创建空间大小是固定的,当空间不够时需要进行扩容,以2倍的关系扩增的,你少一个空间,我增大到原来的2倍,还会有多余空间未使用,所以扩容会造成空间浪费的现象。
但是注意我们因为用的realloc扩容,所以扩容本身会有消耗!!👉👉👉
由于realloc扩容的特性,不确定是原地还是异地扩容,这个与编译器有点关系
原地扩容:扩容的空间地址与原来地址相同
异地扩容:扩容的空间地址与原来地址不同(将原来的数据拷贝过来,还要销毁原来的空间)
链表:
按需申请的空间,不会存在空间浪费现象,利用率极高
四、随机访问:
顺序表:
支持用下标随机访问
链表:
不支持,因为空间在物理上就不是连续的,next找到下一个节点,在用该节点的next找一个,找起来比较麻烦
五、缓存利用率:
缓存👉CPU高速缓存🧑🎓🧑🎓 内存在带电的情况下存储,当断电后未保存的数据会丢失(就像我们在用画板时,画了画,你给电脑关机,下次进去就找不到了)但其速度快,而硬盘可以不带电存储,但是速度慢。
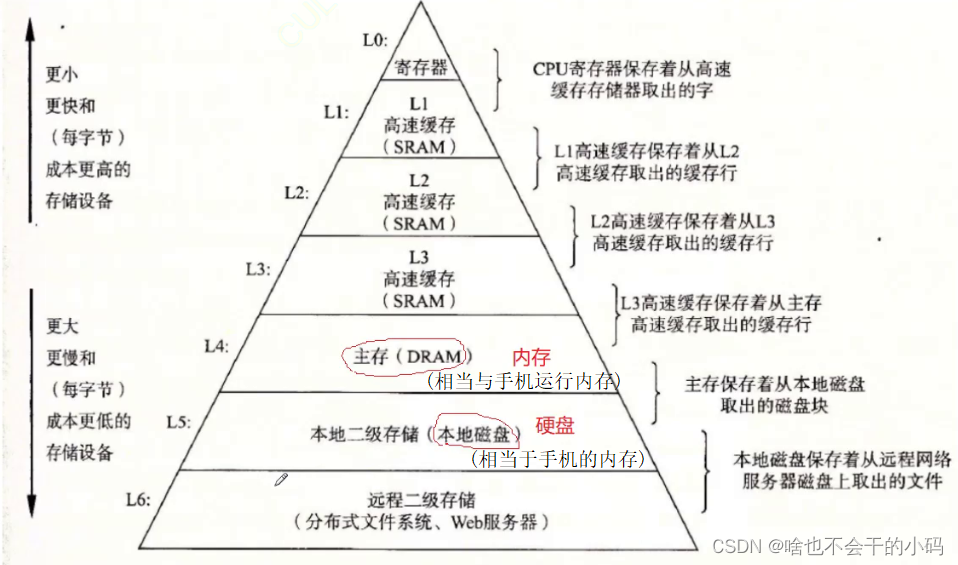
🤔🤔为啥有寄存器和三级缓存??
✨✨主要是cpu的运行速度很快,看不上内存日常不会去访问内存,但是寄存器和三级缓存的速度还是能入下眼✨✨
我们写的代码时,变量存在内存里面,当你要修改变量时会将数据放到寄存器,然后cpu对其接收指令进行修改
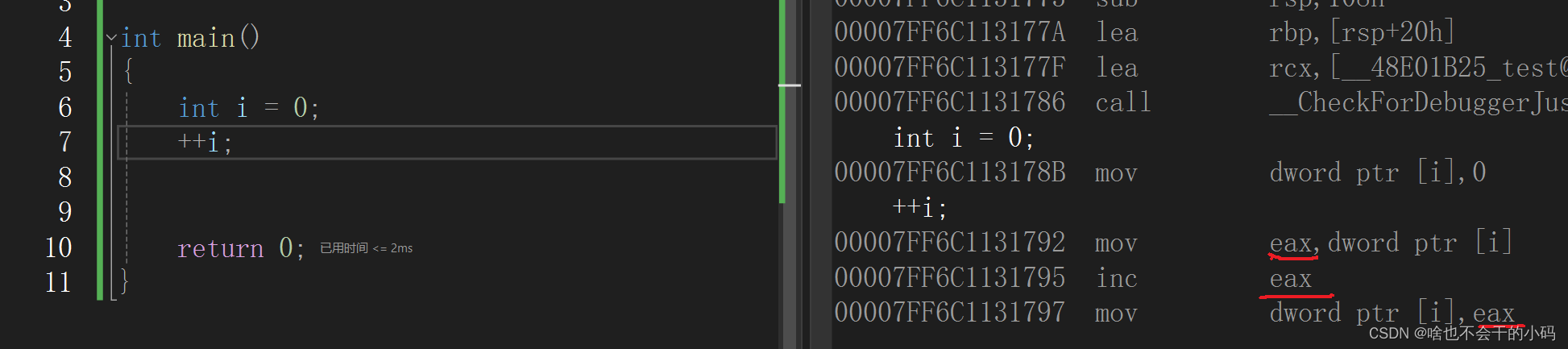
看下面代码的反汇编,mov 是将 i 放到 eax(寄存器)中,然后对寄存器的数据进行inc指令也就是加1, 在讲寄存器的数据放到可i中

但是寄存器个数有限,一般对于4个 8个字节会放到寄存器,数据比较大会加载到缓存,( 缓存里面还要涉及到三级缓存的调用,有点深奥,不讲这么难的,可以自己去查资料)
cpu访问数据会先访问数据是否在缓存中,在---》缓存命中,直接访问。
不在---》不命中,先将数据加载到缓存中,再进行访问。
🤔怎么加载到缓存的??
cpu会按cpu字长去读,会认为你访问当前数据后面(连续在一起的)都不在缓存中,给它加载进去
举个例子:数组为例子,下面的20个人就是一个数组。度假村相当于缓存,领导是cpu,大巴车也是cpu,cpu给你加载到缓存,再访问

注意:缓存有一定的范围,新进来的过多,放不下了,就给旧的清理掉!
对于链表了,你的物理空间是不连续,拉的数据太多,会把缓存区之前的一些数据排挤走了
顺序表:
CPU缓存利用率高。
链表:
CPU缓存利用率低。
六、总结:
| 不同点 | 顺序表 | 单链表 |
| 存储空间 | 物理上一定连续(底层是数组) | 只是逻辑上连续,物理上并不连续 |
| 随机访问 | 下标访问 O(1) | 不支持:要遍历O(N) |
| 任意位置的增删 | 需要搬运元素,效率低O(N) | 无需搬运,只需要修改指针指向 |
| 插入 | 动态顺序表,需要扩容(成倍扩容,可能会造成空间浪费) | 按需申请,没有扩容这一说法 |
| 应用场景 | 元素的高效存储+频繁的访问 | 任意位置插入+删除频繁 |
| CPU缓存利用率 | 缓存利用率高 | 缓存利用率低 |
链表和顺序表各有优势,互相弥补各自的缺点
总之,顺序表用于数据元素较少、读取操作频繁的场景,而链表更适用于数据元素较多、插入、删除操作频繁的场景。
 就到 这吧 ❤️🫰
就到 这吧 ❤️🫰















 176
176

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









