









1. 论文主要要点
1. 提出先验词的网格结构:
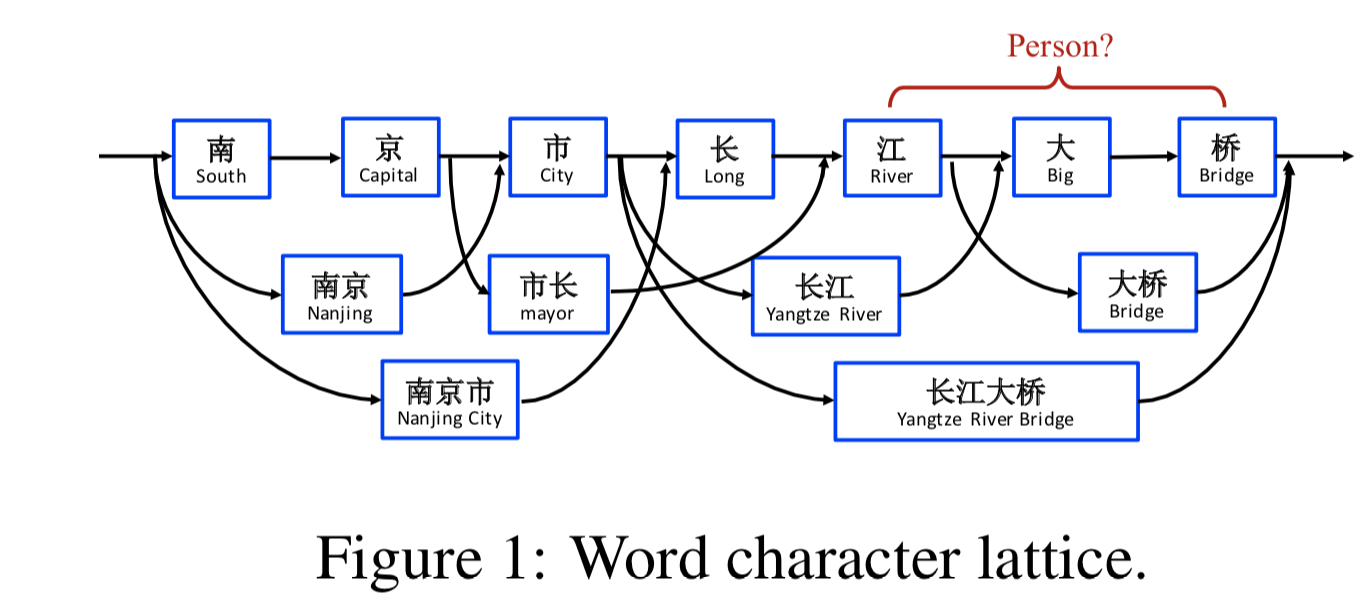
2. 基于上述网格结构,设计Lattice-LSTM,用于融合先验词信息:

实现细节
以字粒度LSTM模型未基础,融入单词网格信息:
- 单词如“南京市”,表示为向量,由预训练词向量如Word2Vec表示
- 并通过一个与LSTM Cell相同的运算,得到单词Cell State,以及一个类似于Input Gate的结果【注意这里使用是词向量,不是字向量】用于跟原本LSTM中的Input Gate去计算权值【word level 没有Output Gate】:
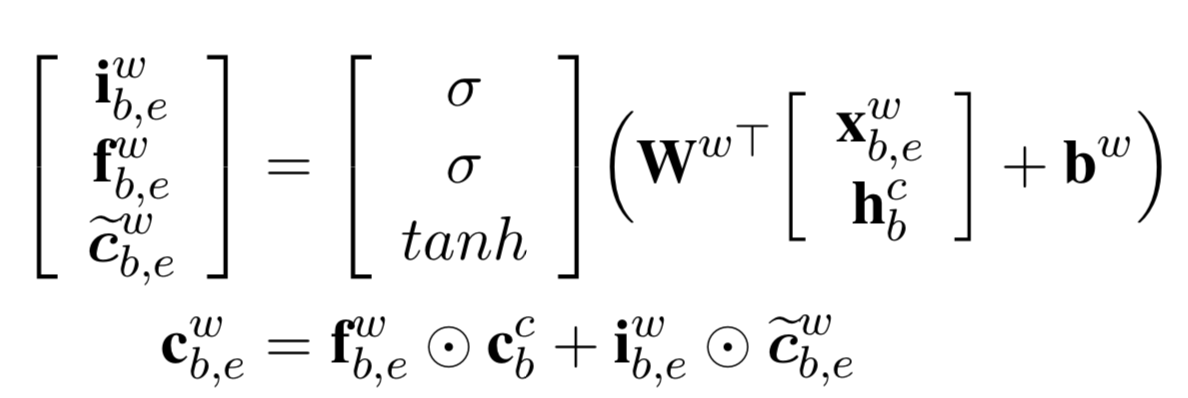
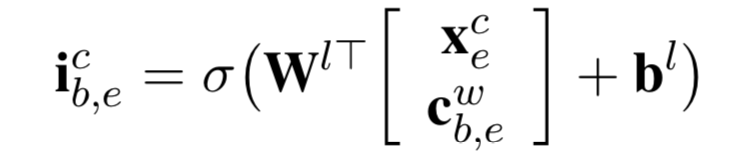
- char和word两部分的Input Gate进行归一化,并通过加权求和计算最终的Cell State【只是为了计算单词特征权值,感觉没必要弄得这么复杂】:
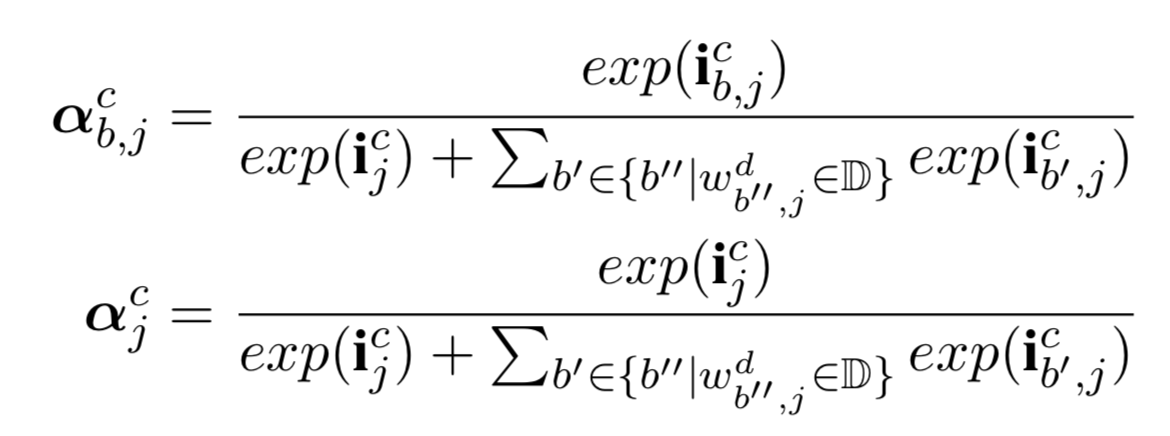
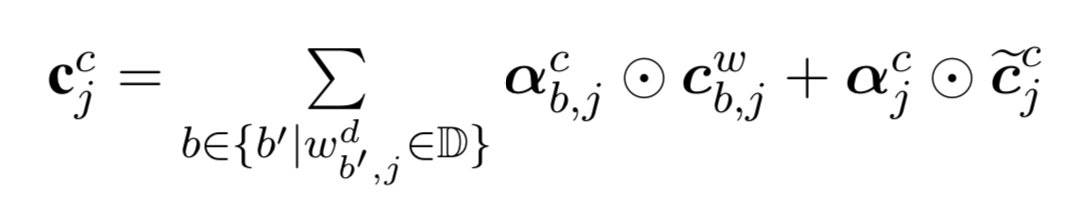
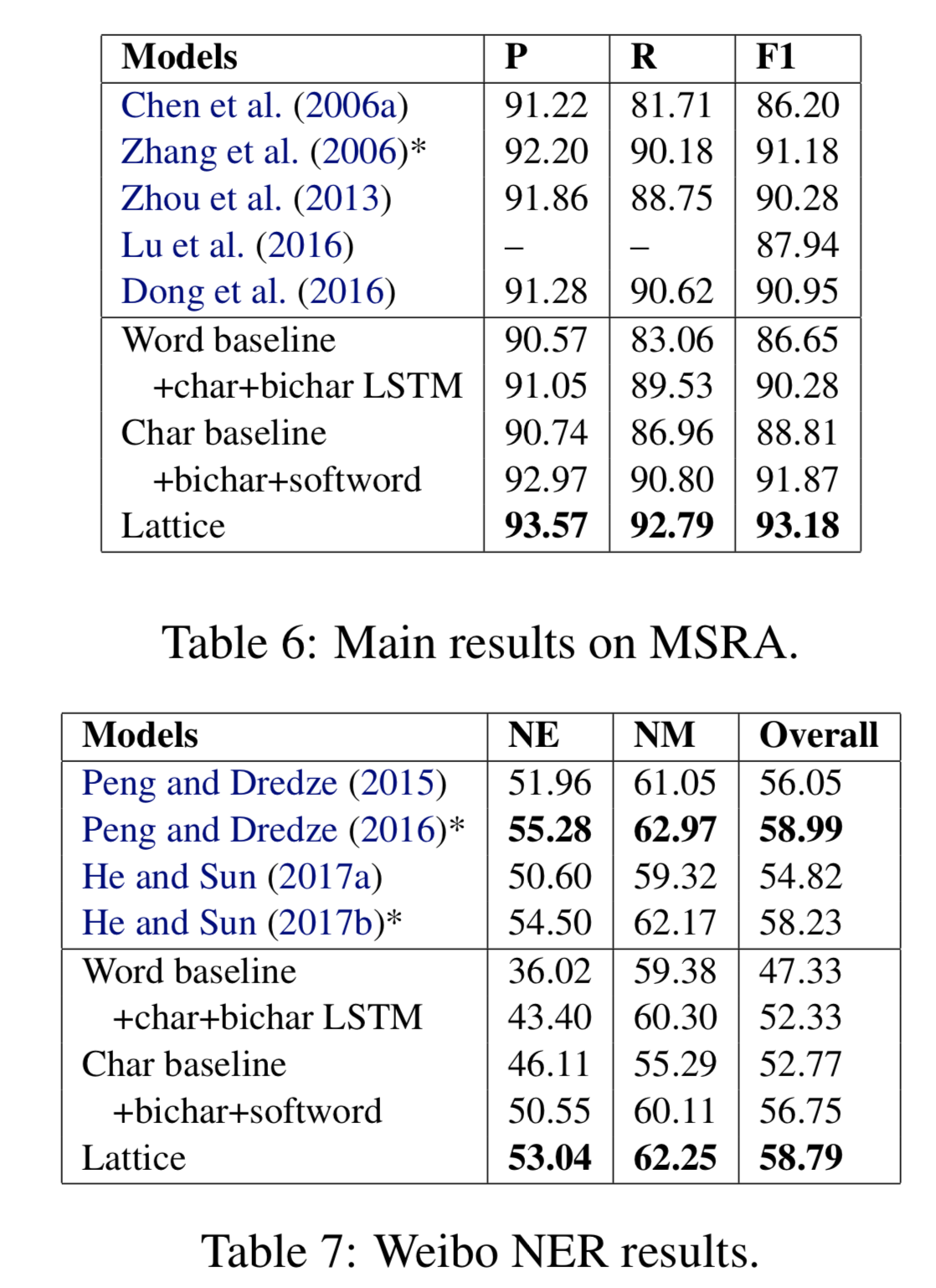
模型效果:
感觉提升比较有限
-
模型缺点:
- 结构复杂,每匹配一个词就多一步Cell计算
- 性能低下,因为其特殊的网格结构,每条query计算结构不统一,故而无法实现batch的训练和预测
- 每个单词的词信息只在单词结尾字才能获取到
- 需要使用词向量,无法添加新词














 783
783











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









