









论文题目:Chinese NER Using Lattice LSTM
论文出处:ACL 2018
论文地址: https://arxiv.org/abs/1805.02023
源码: https://github.com/jiesutd/LatticeLSTM
概要
论文提出了一种适用于中文NER任务的Lattice-Lstm结构。

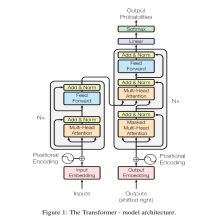
主要思想,综合利用字符级和单词级信息。如上图所示。在每一个字符节点,同时利用字符级输出以及所有在词典中以该字符结尾的词语级输出。
模型结构

整体结构如上图所示。图中为了表达简洁,只绘制了单方向的LSTM。
字符级信息处理方式使用标准的LSTM结构。其中
x
j
c
x^{c}_j
xjc为对应字符的字符嵌入。lattice lstm 与 一般lstm主要区别在于
c
j
c
c^{c}_j
cjc的计算方式。

词语级信息处理模块如下:

注意,与字符级信息的处理模块主要区别是此处没有输出门,因为NER任务最终输出label只在字符级级别进行。
综合字符级信息与词语级信息来计算
c
j
c
c^{c}_j
cjc。
使用一个补充门结构计算每个词语级信息对
c
j
c
c^{c}_j
cjc的贡献。

c
j
c
c^{c}_j
cjc的最终计算方式如下:

文章提出一种归一化算法求出当前字符 Cell 各种输入的权重,类似 Softmax 函数,如上图公式所示。分母为句子中以当前字符结尾的所有词汇的权重以及当前字符输入门,求指数后求和。
最终解码层使用标准CRF层:

论文总结
以下仅代表个人观点
- lattice-lstm的主要思想是综合利用字符级和词语级信息来做NER任务。因为单纯的字符级信息缺少词语级的知识表示,而单纯的词语级表示会导致对分词准确度十分依赖,分词错误会直接导致实体边界划分错误。
- 文章中提到词语级信息是基于文本数据集进行预训练,生成词典及向量(类似word2vec)。使用大量特定下游任务相关领域的语料进行预训练可能对任务效果有帮助。
- 实际跑了一下作者提供的开源代码,目前有一个问题,目前代码只支持batch_size=1.可能是由于模型中信息流需要根据不同样本单独处理导致的,作者在issue中说明目前未编写批量训练版本。模型的运行速度相对较慢。















 5481
5481











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









