









Apriori 算法:(hadoop中实现)
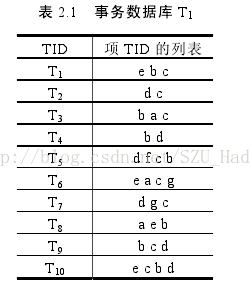
第一步:统计项的频度 (用一个MR统计出来)
假设是一个矩阵
U1 app1 , app3
U2 app1 , app2 , app3
U3 app2 , app3
把矩阵看成一行行的向量
U1<app1 , app3>
U2<app1 , app2 , app3>
U3<app2 , app3>
装置矩阵
<app1,U1><app3,U1>
<app1,U2><app2,U2><app3,U2>
<app2,U3><app3,U3>
key:app vaule:U
放到Reduce统计
如: app1 ,<U1,U2> 输出==>app1:2 app2:3 app3:2
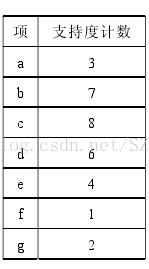
第二步:根据最小支持度进行筛选 假设最小支持度是3
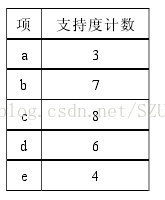
第三步:根据上面的表生成候选集

第四步:对每个候选对在矩阵的每一行去比较(数据库)看看它的频度
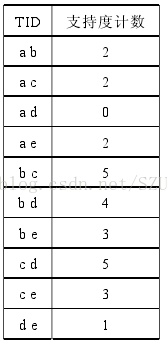
第五步:对比最小支持度筛选出来

第六步:继续生成3项频繁集
利用MR生成(本人构思 不推荐)
cd:5 ce:3 ==> c:1 d:1 c:1 e:1 ==> c:2 d:1 e:1 ==>1:c 1:d 1:e==>1:<c,d,e>
对value生成3项
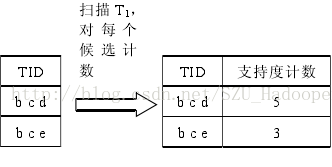
第七步:继续往下直到没有(K+1)频繁项
想法1:从k=1找频繁集直到到达目标k
想法2:从所有项集中找出所有的包含k个元素的子集,统计支持度和置信度(更好和容易实现















 594
594

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









