







 本文介绍了字符集的概念,详细阐述了ASCII码的原理和局限性,进而引出Unicode编码,特别是UTF-8编码的特点。讨论了为何在不同应用间需要指定字符编码以避免乱码问题,强调了字符编码在信息技术交流中的重要性。
本文介绍了字符集的概念,详细阐述了ASCII码的原理和局限性,进而引出Unicode编码,特别是UTF-8编码的特点。讨论了为何在不同应用间需要指定字符编码以避免乱码问题,强调了字符编码在信息技术交流中的重要性。
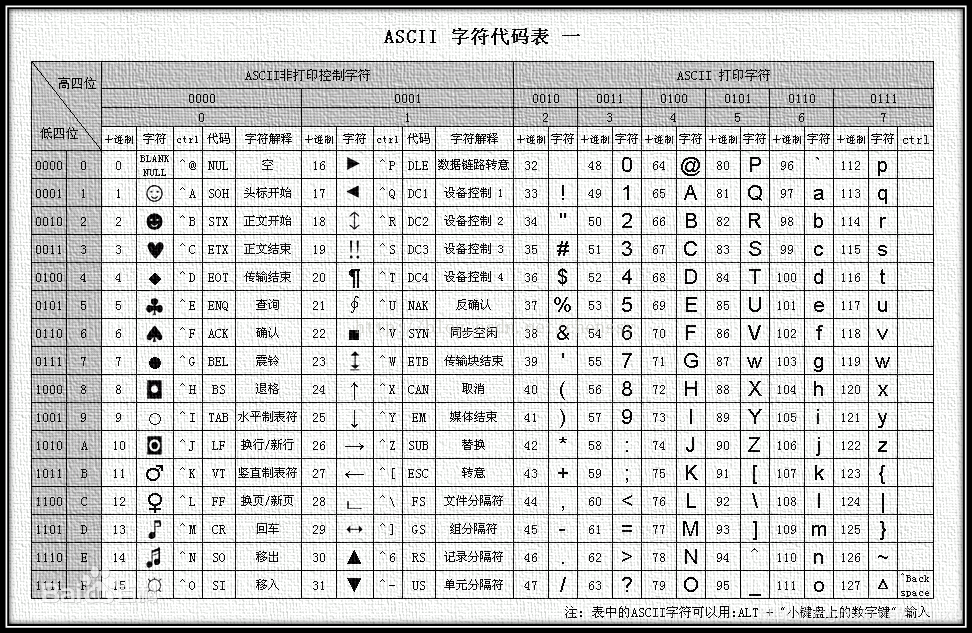
ASCII是国际通用的字符集。
字符集
计算机之间通信最终要转化为二进制的机器码进行通信,但是我们通常不可能使用机器码,也同样很难读懂机器码。如果我们要输入一个字符a,我们需要将字符a转化为一个二进制码,再进行通信。而字符集,把所有的我们可能用到的字符定义为指定二进制进行编排。
ASCII码
ASCII码就是我们最常用的一套字符集规范
百度百科
一个字符通常由8个比特(bit),也就是1个字节(byte)来表示。一个byte最大可以表示255。我们可以看到ASCII通过0~127描述常用的符号和大小写英文。
输入一个字符E,E的十进制表示位69,那么转化成二进制码就是0100 0101(编码),计算机识别后再对应显示出来E(解码)。
那么,中文该如何表示?

Unicode(万国码、统一码)
由于ASCII不能表示除英文外的其他字符,比如中文、拉丁文,因此世界推出了Unicode码,包含世界上所有文字和符号的编码。
Unicode码是用16进制表示的,有很多方案。eg:utf-8、utf-16、ISO10646。这些编码方案都只用了少量的Unicode平面(可以理解为内容),不同编码方案有他们独特的特点。
比如utf-8:
- 以字节为单位对Unicode进行编码
- 对不同范围的字符使用不同长度的编码
- UTF-8编码的最大长度是4个字节。4字节模板有21个x,即可以容纳21位二进制数字。Unicode的最大码位0x10FFFF也只有21位。
- UTF-8编码方案前128的表示跟ASCII相同
思考
之前一直有个疑问,为什么我们的html页面、jsp页面…或者springboot连接数据库等应用之间通信,都需要指定字符编码。原来是因为不同的应用可能采用的不同的Unicode编码方案,而这些不同的编码方案对于字符的编码格式很有可能不同,以至于计算机在识别的时候出现格式混乱,而打印出不同的字符,造成乱码
结语
莫要 书山有路勤为径,学海无涯苦作舟
而应 日积月累,乐在其中
希望能帮助到您


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









