





译注:
个性化推荐是当前很热的一个概念。网站,服务(service)要更好的为客户提供个性化的服务,都应该有个性化的推荐服务。因为现在信息量太大,即使使用搜索用户也需要花费一定的时间和技能才能找到想要的信息。而推荐不需要用户花任何时间和学习就能找到有用的信息(如果推荐够准确的话)。我们身边有很多推荐的例子:搜索引擎的广告,信息聚合推送服务,LBS应用等。面向企业的SaaS服务也可以利用推荐技术提供对客户的服务质量,减少客户使用服务的难度。
看到一篇推荐引擎技术的介绍文章,翻译出来与大家共享。原文出处:http://java.dzone.com/articles/recommendation-engine-models?utm_source=feedburner&utm_medium=feed&utm_campaign=Feed%3A+zones%2Farchitects+%28Architects+Zone%29
推荐引擎模型
推荐系统的经典模型中有两种元素:用户(User)和物品(Item)。用户包含一些相关的元数据,包括年龄,性别,种族和其他一些人口统计相关信息。物品也有一些相关元数据,例如描述,价格,重量等。另外用户和物品之间还会有关联(或交易),例如userA下载或购买了movieB,userX给productY评5分等。
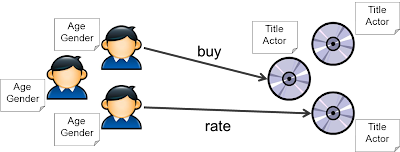
给定用户和物品的元数据,以及它们在一段时间里的关联,我们是否能回答以下几个问题:
- userX购买itemY的概率是多少?
- userX会改itemY评多少分?
- 最应该推荐给userX的k个从未见过的物品是哪些?
基于内容的方法
该方法是用元数据对用户和物品进行分类,然后在将类别进行匹配。例如要给找工作的人推荐职位,我们可以利用IR(信息检索)或文本搜索来对用户的简历和职位的描述进行匹配。另一个例子是向用会推荐一个和他买过的东西类似的物品。相似度可以用物品的元数据进行测量,可以使用各种距离函数。目标是找出和用户已经喜欢的物品距离最近(最相似)的k个物品。
协同过滤法
该方法只关心用户和物品的关联信息,用这些信息来作推荐。关联数据可以表示为一个矩阵。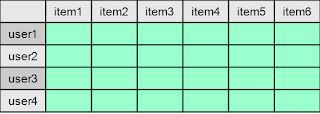
单元格(译注:绿色)表示用户和物品之间的关联。例如,单元格可以表示用户对物品的评分(如果单元格是数值的话),或者是一个二项值,用来表示用户和物品之间是否有关联(如:1表示userX购买了itemY,0表示没有)。
这个矩阵可能是非常稀疏的,即大部分的单元格都是空白的。我们需要想清楚如何处理这些空白单元格,通常有2中做法:
- 将这些单元格视为0。等同于用户给物品评分为0。这对有的应用场景可能是可行的,对别的可能不行。
- 估算单元格应该填什么值。例如,如果我们知道userX给itemB给了什么评分,要估算他会给itemA评多少分,我们可以看看那些给itemA和itemB都给了评分的用户(或和userX同一年龄段的用户),计算一个他们所给评分的平均值。然后使用itemA和itemB的平均分,结合userX给itemB的评分,来计算应该(译注:在userX和itemA的单元格)插入什么分值。
基于用户的协同过滤
该模型中,我们要做以下事情
- 找到和userX相似的一组用户
- 找到所有改组用户都喜欢而userX没看过的电影
- 给这些电影评分并推荐给userX
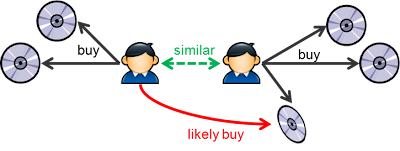
这里引入了用户相似度的概念,其实也就是用户/物品矩阵中2个行向量的相似度。要计算和某个用户最相似的K个用户,一个简单的做法就是计算和所有用户的相似度并取最高的K个。
有不同的相似度函数可以使用。Jaccard距离函数可以计算2个用户看过的电影的交集中的元素数量与并集中的元素数量的比值(译注:比值越大相似度越大)。Pearson相似度则先对用户评分进行规格化,再计算余弦距离。
但该方法有2个问题:
- 比较userX和userY代价大,因为用户的属性可能是百万级的。
- 找出与userX最相似的K的用户需要对所有与的userX和userY用户对进行计算
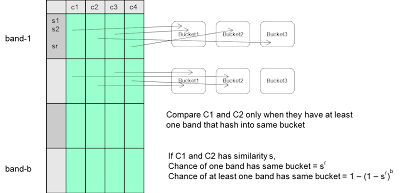
位置敏感Hash和Minhash。要解决问题1,我们可以使用称为minhash的小代价估算函数来初略估算相似度。其基本思想就是找到一个哈希函数h(),使得h(userX) = h(userY)的概率和userX与userY相似的概率成正比。如果我们能找到100个h()函数,我们就能计算h(userX) = h(userY)的那些函数的数量来判断userX和userY有多相似了。该思想如下图所示。

如果行数很多的话对行进行排列的代价会很大。记住h(c1)的目的是返回值为1的第一行的行号,所以我们可以扫描c1的每一行看它是否为1。如果是,我们就可以应用一个函数newRowNum = hash(rowNum)来模拟一个排列。取目前为止看到到的最小的newRowNum。
作为一个优化,我们可以一次处理一行,而不是一列。该算法如下图所示:
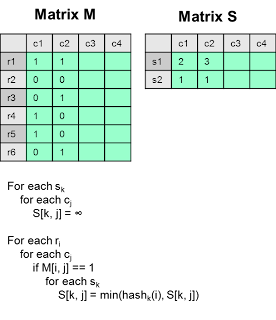
要解决问题2,我们需要避免计算所有用户与userX的相似度。方法是将用户hash到一些桶中,且使相似的用户落在同一个桶中。那么,我们就不用计算所有的用户和userX的相似度了,而只需要计算和userX在同一个桶的用户和他的相似度就可以了。
这个方法是将列水平拆分为b个段,每一段都有r行。通过选择参数b和r,我们可以控制不同列至少有一个段落入同一个桶的可能性(相似度的函数)。
基于物品的协同过滤
如果我们交换用户/物品矩阵并做与上面相同的事情,就可以计算物品与物品的相似度。该模型中我们做以下事情。- (从关联数据中)找出userX喜欢的电影的集合
- 找出和userX喜欢的这个电影集合类似的一组电影
- 给这些电影评分并推荐给userX。
事实证明计算基于物品的协同过滤要优于计算用户与用户的相似度,理由如下:
- 物品的数量通常都小于用户的数量。
- 用户的品位会随着时间而变化,所以需要经常更新相似度矩阵。而物品之间的相似度更趋于稳定,不需要经常更新。
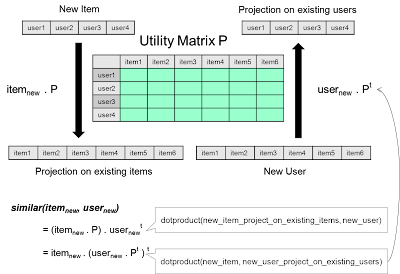
单值分解
回头再看看矩阵,可以看到矩阵相乘实际等同于将物品空间中的一个物品映射到用户空间。换言之,如果我们将每个现有物品看作是用户空间的一个轴(注意,用户是一个对现有物品评分的向量),那么将一个新物品与该矩阵相乘就能得到一个和该用户相似的向量。所以我们可以计算投影后的新物品与用户的点积来判断它的相似度。结果表明这和将用户映射到物品空间并计算点积是一回事。
换言之,矩阵乘积等同于物品空间和用户空间间的映射。现在假设有一个隐藏在两者之间的概念空间。我们可以认为是从用户空间跳到一个概念空间,再从那跳到物品空间,而不是从用户空间直接跳到物品空间。
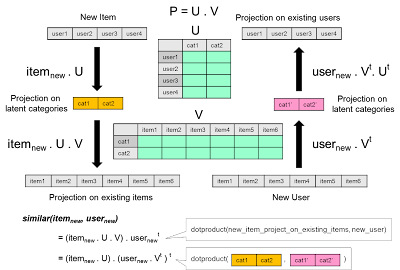
这里要注意,我们先将用户空间映射到概念空间,同时也将物品空间映射到概念空间。然后我们在概念空间将用户和物品进行匹配。这是我们的推荐系统的一个概括。
我们可以用SVD将矩阵分解为2部分。设P是m×n的矩阵(m行,n列)。P = UDV,U是一个m×n的矩阵,每列都是一个P×转置(P)的特征向量。V是一个n×m矩阵,每行都是一个转置(P)×P的特征向量。D是一个包含P×转置(P)或转置(P)×P的特征向量的对角矩阵。
换言之,我么可以将P分解为U×平方根(D)和平方根(D)×V。
注意,D可以认为是概念空间中每个概念的强度。值是根据数量级降序排列的。如果我们通过将值设为0的方式去掉那些最弱的概念,就减少了非0元素的数量,这能有效的概括(generalize)概念空间(集中在重要概念上)。
计算大维度的矩阵的SVD分解的代价很大。幸运的是,如果我们的目标是计算一个近似SVD,我们就可以使用本文描述的随机投影机制。
基于关联规则的方法
该模型中,我们使用购物篮关联规则算法来发现类似这样的规则: {item1, item2} => {item3, item4, item5}
我们将每个用户表示为一个篮子,每次浏览作为一个事物(注意我们忽略评分,只用二项值)。然后用关联规则挖掘算法来检测频繁项集和关联规则。
然后,对每个用户,我们将用户以前浏览过的事物匹配到规则集来决定应该推荐哪些其他的电影。
评估推荐系统
有了推荐系统后,如何评估它的效果呢。
基本思想就是把数据分为训练集和测试集。对测试集,我们去掉特定的一些用户和电影的关联数据(将单元格的值从1变为0),假装用户没看过这些电影。然后我们用训练集来训练推荐系统,并将(去除部分数据后的)测试集注入推荐系统。推荐的效果可以用推荐项和去除项的重合度来测量。换言之,一个好的推荐系统应该能恢复那些从测试集中去除的项。
有些情况可以使用物品的标签信息。物品有明确的标签与之相关联(我们可以认为标签是加在物品上的一种用户标注的概念空间)。可以认为每个物品都用一个标签向量进行描述。那就可以根据与用户关联的物品来对用户进行自动标记了。例如,如果userX买了附有标签Z1和Z2的itemY,就可以在userX的标签向量中添加标签Z1和Z2。我们可以使用一种时间衰减机制来更新用户的标签向量。如下:
current_user_tag = alpha * item_tag + (1 - alpha) * prev_user_tag
要想用户推荐一个物品,我们只需要通过计算用户标签向量和物品标签向量的点积(例如:余弦距离)找出最值得推荐的K个物品。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









