前言
在有些情况下,运行于Hadoop集群上的一些mapreduce作业本身的数据量并不是很大,如果此时的任务分片很多,那么为每个map任务或者reduce任务频繁创建Container,势必会增加Hadoop集群的资源消耗,并且因为创建分配Container本身的开销,还会增加这些任务的运行时延。如果能将这些小任务都放入少量的Container中执行,将会解决这些问题。好在Hadoop本身已经提供了这种功能,只需要我们理解其原理,并应用它。
Uber运行模式就是解决此类问题的现成解决方案。本文旨在通过测试手段验证Uber运行模式的效果,在正式的生成环境下,还需要大家具体情况具体对待。
Uber运行模式
Uber运行模式对小作业进行优化,不会给每个任务分别申请分配Container资源,这些小任务将统一在一个Container中按照先执行map任务后执行reduce任务的顺序串行执行。那么什么样的任务,mapreduce框架会认为它是小任务呢?
- 地图任务的数量不大于mapreduce.job.ubertask.maxmaps参数(默认值是9)的值;
- 减少任务的数量不大于mapreduce.job.ubertask.maxreduces参数(默认值是1)的值;
- 输入文件大小不大于mapreduce.job.ubertask.maxbytes参数(默认为1个Block的字节大小)的值;
- map任务和reduce任务需要的资源量不能大于MRAppMaster(mapreduce作业的ApplicationMaster)可用的资源总量;
上面显示的参数mapreduce.job.ubertask.enable用来控制是否开启
Uber运行模式,默认为false。
优化
限制任务划分数量
我们知道WordCount例子中的reduce任务的数量通过Job.setNumReduceTasks(int)方法已经设置为1,因此满足mapreduce.job.ubertask.maxreduces参数的限制。所以我们首先控制下map任务的数量,我们通过设置mapreduce.input.fileinputformat.split.maxsize参数来限制。看看在满足小任务前提,但是不开启
Uber运行模式时的执行情况。执行命令如下:
- hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.0.jar wordcount -D mapreduce.input.fileinputformat.split.maxsize = 30 /wordcount/input /wordcount/output/result1
观察执行结果,可以看到没有启用Uber模式,作业划分为6个分片,如下图:

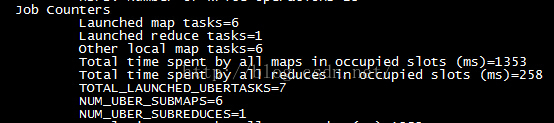
还可以看到一共是6个地图任务和1个减少任务,如下图:
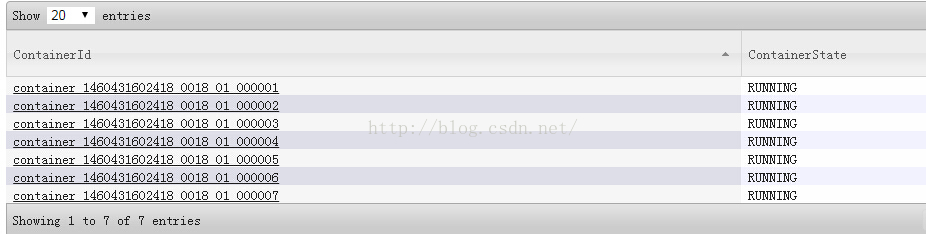
我在任务执行过程中,在web界面对于分配的Container进行截图,可以看到一共分配了7个Container:
开启Uber模式
现在我们开启mapreduce.job.ubertask.enable参数并使用Uber运行模式,命令如下:
- hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.0.jar wordcount -D mapreduce.input.fileinputformat.split.maxsize = 30 -D mapreduce.job.ubertask.enable = true /wordcount/input /wordcount/output/result2
然后观察执行结果,可以看到已经启用了Uber模式,如下图:

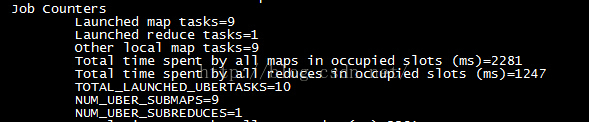
依然是6个地图任务和1个减少任务,但是之前的数据本地地图任务= 6一行信息已经变为当地的其他地图tasks=6。此外还增加了TOTAL_LAUNCHED_UBERTASKS、NUM_UBER_SUBMAPS、NUM_UBER_SUBREDUCES等信息,如下图所示:
以下列出这几个信息的含义:
| 输出字段 | 描述 |
| TOTAL_LAUNCHED_UBERTASKS | 启动的Uber任务数 |
| NUM_UBER_SUBMAPS | Uber任务中的地图任务数 |
| NUM_UBER_SUBREDUCES | Uber中减少任务数 |
因此我们知道这7个任务都在Uber模式下运行,其中包含6个map任务和1个reduce任务。
即便如此,有人依然会担心真正分配了多少Container资源,请看我在web界面的截图:
其它测试
由于我主动控制了分片大小,导致分片数量是6,这小于mapreduce.job.ubertask.maxmaps参数的默认值9。按照之前的介绍,当map任务数量大于9时,那么这个作业就不会被认为小任务。所以我们先将分片大小调整为20字节,使得map任务的数量刚好等于9,然后执行以下命令:
- hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.0.jar wordcount -D mapreduce.input.fileinputformat.split.maxsize = 20 -D mapreduce.job.ubertask.enable = true /wordcount/input /wordcount/output/result3
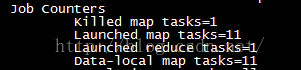
任务划分相关的信息截图如下:

。我们看到的确将输入数据划分为9份了其它信息如下:
我们看到一共10个Uber模式运行的任务,其中包括9个地图任务和1个减少任务。
最后,我们再将分片大小调整为19字节,使得map任务数量等于10,然后执行以下命令:
- hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.0.jar wordcount -D mapreduce.input.fileinputformat.split.maxsize = 19 -D mapreduce.job.ubertask.enable = true /wordcount/input /wordcount/output/result4
任务划分相关的信息截图如下:

。我们看到的确将输入数据划分为10份了其它信息如下:
可以看到又重新显示了数据的本地地图 地图
此外,还可以通过调整reduce任务数量或者输入数据大小等方式,使得Uber失效,有兴趣的同学可以自行测试。
源码分析
本文的最后,我们从源码实现的角度来具体分析下Uber运行机制。有经验的Hadoop工程师,想必知道当mapreduce任务提交给ResourceManager后,由RM负责向NodeManger通信启动一个Container用于执行MRAppMaster。启动MRAppMaster实际也是通过调用其main方法,最终会调用MRAppMaster实例的serviceStart方法,其实现如下:
- protected void serviceStart() throws Exception {
-
-
- job = createJob(getConfig(), forcedState, shutDownMessage);
-
-
- if (!errorHappenedShutDown) {
- JobEvent initJobEvent = new JobEvent(job.getID(), JobEventType.JOB_INIT);
-
- jobEventDispatcher.handle(initJobEvent);
-
-
-
- if (job.isUber()) {
- speculatorEventDispatcher.disableSpeculation();
- } else {
- dispatcher.getEventHandler().handle(
- new SpeculatorEvent(job.getID(), clock.getTime()));
- }
-
- }
serviceStart方法的执行步骤如下:
- 调用createJob方法创建JobImpl实例。
- 发送JOB_INIT事件,然后处理此事件。
- 使用Uber运行模式的一个附加动作——即一旦满足Uber运行的四个条件,那么将不会进行推断执行优化。
createJob方法的代码实现如下:
- protected Job createJob(Configuration conf, JobStateInternal forcedState,
- String diagnostic) {
-
-
- Job newJob =
- new JobImpl(jobId, appAttemptID, conf, dispatcher.getEventHandler(),
- taskAttemptListener, jobTokenSecretManager, jobCredentials, clock,
- completedTasksFromPreviousRun, metrics,
- committer, newApiCommitter,
- currentUser.getUserName(), appSubmitTime, amInfos, context,
- forcedState, diagnostic);
- ((RunningAppContext) context).jobs.put(newJob.getID(), newJob);
-
- dispatcher.register(JobFinishEvent.Type.class,
- createJobFinishEventHandler());
- return newJob;
- }
从以上代码可以看到创建了一个JobImpl对象,此对象自身维护了一个状态机(有关状态机转换的实现原理可以参阅《
Hadoop2.6.0中YARN底层状态机实现分析》一文的内容),用于在接收到事件之后进行状态转移并触发一些动作。JobImpl新建后的状态forcedState是JobStateInternal.NEW。最后将此JobImpl对象放入AppContext接口的实现类RunningAppContext的类型为Map<JobId,工作>的缓存上下文中。
JobEventDispatcher的handle方法用来处理JobEvent。之前说到serviceStart方法主动创建了一个类型是JobEventType.JOB_INIT的JobEvent,并且交由JobEventDispatcher的handle方法处理。handle方法的实现如下:
- private class JobEventDispatcher implements EventHandler<JobEvent> {
- @SuppressWarnings("unchecked")
- @Override
- public void handle(JobEvent event) {
- ((EventHandler<JobEvent>)context.getJob(event.getJobId())).handle(event);
- }
- }
处理方法从AppContext的实现类RunningAppContext中获取JobImpl对象,代码如下:
- @Override
- public Job getJob(JobId jobID) {
- return jobs.get(jobID);
- }
最后调用JobImpl实例的句柄方法,其实现如下:
- public void handle(JobEvent event) {
- if (LOG.isDebugEnabled()) {
- LOG.debug("Processing " + event.getJobId() + " of type "
- + event.getType());
- }
- try {
- writeLock.lock();
- JobStateInternal oldState = getInternalState();
- try {
- getStateMachine().doTransition(event.getType(), event);
- } catch (InvalidStateTransitonException e) {
- LOG.error("Can't handle this event at current state", e);
- addDiagnostic("Invalid event " + event.getType() +
- " on Job " + this.jobId);
- eventHandler.handle(new JobEvent(this.jobId,
- JobEventType.INTERNAL_ERROR));
- }
-
- if (oldState != getInternalState()) {
- LOG.info(jobId + "Job Transitioned from " + oldState + " to "
- + getInternalState());
- rememberLastNonFinalState(oldState);
- }
- }
-
- finally {
- writeLock.unlock();
- }
- }
处理方法的处理步骤如下:
- 获取修改JobImpl实例的锁;
- 获取JobImpl实例目前所处的状态
- 状态机状态转换;
- 释放修改JobImpl实例的锁。
getInternalState方法用于获取JobImpl实例当前的状态,其实现如下:
- @Private
- public JobStateInternal getInternalState() {
- readLock.lock();
- try {
- if(forcedState != null) {
- return forcedState;
- }
- return getStateMachine().getCurrentState();
- } finally {
- readLock.unlock();
- }
- }
我们之前介绍过,在创建JobImpl实例时,其forcedState字段应当是JobStateInternal.NEW。
JobImpl状态机转移时,处理的JobEvent的类型是JobEventType.JOB_INIT,因此经过状态机转换最终会调用InitTransition的transition方法。有关状态机转换的实现原理可以参阅《
Hadoop2.6.0中YARN底层状态机实现分析》一文的内容。
InitTransition的transition方法处理Uber运行模式的关键代码是
- @Override
- public JobStateInternal transition(JobImpl job, JobEvent event) {
-
- job.makeUberDecision(inputLength);
-
-
- }
最后我们看看JobImpl实例的makeUberDecision方法的实现:
- private void makeUberDecision(long dataInputLength) {
-
-
-
-
- int sysMaxMaps = conf.getInt(MRJobConfig.JOB_UBERTASK_MAXMAPS, 9);
-
- int sysMaxReduces = conf.getInt(MRJobConfig.JOB_UBERTASK_MAXREDUCES, 1);
-
- long sysMaxBytes = conf.getLong(MRJobConfig.JOB_UBERTASK_MAXBYTES,
- fs.getDefaultBlockSize(this.remoteJobSubmitDir));
-
-
-
- long sysMemSizeForUberSlot =
- conf.getInt(MRJobConfig.MR_AM_VMEM_MB,
- MRJobConfig.DEFAULT_MR_AM_VMEM_MB);
-
- long sysCPUSizeForUberSlot =
- conf.getInt(MRJobConfig.MR_AM_CPU_VCORES,
- MRJobConfig.DEFAULT_MR_AM_CPU_VCORES);
-
- boolean uberEnabled =
- conf.getBoolean(MRJobConfig.JOB_UBERTASK_ENABLE, false);
- boolean smallNumMapTasks = (numMapTasks <= sysMaxMaps);
- boolean smallNumReduceTasks = (numReduceTasks <= sysMaxReduces);
- boolean smallInput = (dataInputLength <= sysMaxBytes);
-
- long requiredMapMB = conf.getLong(MRJobConfig.MAP_MEMORY_MB, 0);
- long requiredReduceMB = conf.getLong(MRJobConfig.REDUCE_MEMORY_MB, 0);
- long requiredMB = Math.max(requiredMapMB, requiredReduceMB);
- int requiredMapCores = conf.getInt(
- MRJobConfig.MAP_CPU_VCORES,
- MRJobConfig.DEFAULT_MAP_CPU_VCORES);
- int requiredReduceCores = conf.getInt(
- MRJobConfig.REDUCE_CPU_VCORES,
- MRJobConfig.DEFAULT_REDUCE_CPU_VCORES);
- int requiredCores = Math.max(requiredMapCores, requiredReduceCores);
- if (numReduceTasks == 0) {
- requiredMB = requiredMapMB;
- requiredCores = requiredMapCores;
- }
- boolean smallMemory =
- (requiredMB <= sysMemSizeForUberSlot)
- || (sysMemSizeForUberSlot == JobConf.DISABLED_MEMORY_LIMIT);
-
- boolean smallCpu = requiredCores <= sysCPUSizeForUberSlot;
- boolean notChainJob = !isChainJob(conf);
-
-
-
-
-
-
-
-
- isUber = uberEnabled && smallNumMapTasks && smallNumReduceTasks
- && smallInput && smallMemory && smallCpu
- && notChainJob;
-
- if (isUber) {
- LOG.info("Uberizing job " + jobId + ": " + numMapTasks + "m+"
- + numReduceTasks + "r tasks (" + dataInputLength
- + " input bytes) will run sequentially on single node.");
-
-
- conf.setFloat(MRJobConfig.COMPLETED_MAPS_FOR_REDUCE_SLOWSTART,
- 1.0f);
-
-
-
- conf.setInt(MRJobConfig.MAP_MAX_ATTEMPTS, 1);
- conf.setInt(MRJobConfig.REDUCE_MAX_ATTEMPTS, 1);
-
-
- conf.setBoolean(MRJobConfig.MAP_SPECULATIVE, false);
- conf.setBoolean(MRJobConfig.REDUCE_SPECULATIVE, false);
- } else {
- StringBuilder msg = new StringBuilder();
- msg.append("Not uberizing ").append(jobId).append(" because:");
- if (!uberEnabled)
- msg.append(" not enabled;");
- if (!smallNumMapTasks)
- msg.append(" too many maps;");
- if (!smallNumReduceTasks)
- msg.append(" too many reduces;");
- if (!smallInput)
- msg.append(" too much input;");
- if (!smallCpu)
- msg.append(" too much CPU;");
- if (!smallMemory)
- msg.append(" too much RAM;");
- if (!notChainJob)
- msg.append(" chainjob;");
- LOG.info(msg.toString());
- }
- }
如果你认真阅读以上代码的实现,就知道这正是我在本文一开始说的Uber运行模式判断mapreduce作业是否采用Uber模式执行的4个条件,缺一不可。一旦判定为Uber运行模式,那么还告诉我们以下几点:
- 设置当map任务全部运行结束后才开始reduce任务(参数mapreduce.job.reduce.slowstart.completedmaps设置为1.0)。
- 将当前Job的最大map任务尝试执行次数(参数mapreduce.map.maxattempts)和最大reduce任务尝试次数(参数mapreduce.reduce.maxattempts)都设置为1。
- 取消当前Job的map任务的推断执行(参数mapreduce.map.speculative设置为false)和reduce任务的推断执行(参数mapreduce.reduce.speculative设置为false)。



























 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









