







 本文深入探讨Hadoop MapReduce的设计思想、优缺点及其工作机制,包括MapReduce的两个阶段、运行机制的五个步骤,以及MapTask和ReduceTask的工作原理。通过详细阐述MapReduce的执行流程,揭示其在大数据处理中的核心作用和优化潜力。
本文深入探讨Hadoop MapReduce的设计思想、优缺点及其工作机制,包括MapReduce的两个阶段、运行机制的五个步骤,以及MapTask和ReduceTask的工作原理。通过详细阐述MapReduce的执行流程,揭示其在大数据处理中的核心作用和优化潜力。
文章目录
前言-MR概述
MapReduce是一个分布式计算框架,是用户开发“基于Hadoop的数据分析应用”的核心框架。主要由两部分组成:编程模型和运行时环 境。其中,编程模型为用户提供了非常易用的编程接口,用户只需要像编写串行程序 一样实现几个简单的函数即可实现一个分布式程序,而其他比较复杂的工作,如节点 间的通信、节点失效、数据切分等,全部由MapReduce运行时环境完成,用户无须 关心这些细节。
1.Hadoop MapReduce设计思想及优缺点
设计思想
Hadoop MapReduce诞生于搜索领域,主要解决搜索引擎面临的海量数据处理扩展性差的问 题。它的实现很大程度上借鉴了谷歌MapReduce的设计思想,包括简化编程接口、 提高系统容错性等。
优点:
易于编程:
传统的分布式程序设计(如MPI)非常复杂,用户需要关注的细节 非常多,比如数据分片、数据传输、节点间通信等,因而设计分布式程序的门槛非常 高。Hadoop的一个重要设计目标便是简化分布式程序设计,将所有并行程序均需要关注的设计细节抽象成公共模块并交由系统实现,而用户只需专注于自己的应用程序逻辑实现,这样简化了分布式程序设计且提高了开发效率。
良好的扩展性:
随着公司业务的发展,积累的数据量(如搜索公司的网页量) 会越来越大,当数据量增加到一定程度后,现有的集群可能已经无法满足其计算能力和存储能力,这时候管理员可能期望通过添加机器以达到线性扩展集群能力的目的。
高容错性:
在分布式环境下,随着集群规模的增加,集群中的故障率(这里 的“故障”包括磁盘损坏、机器宕机、节点间通信失败等硬件故障和坏数据或者用户 程序bug产生的软件故障)会显著增加,进而导致任务失败和数据丢失的可能性增 加。为此,Hadoop通过计算迁移或者数据迁移等策略提高集群的可用性与容错性。
适合PB级以上海量数据的离线处理:
可以实现上千台服务器集群并发工作,提供数据处理能力。
缺点:
不擅长实时计算:
MapReduce无法像MySQL一样,在毫秒或者秒级内返回结果。
不擅长流式计算
流式计算的输入数据是动态的,而MapReduce的输入数据集是静态的,不能动态变化。这是因为MapReduce自身的设计特点决定了数据源必须是静态的。
不擅长DAG(有向图)计算
多个应用程序存在依赖关系,后一个应用程序的输入为前一个的输出。在这种情况下,MapReduce并不是不能做,而是使用后,每个MapReduce作业的输出结果都会写入到磁盘,会造成大量的磁盘IO,导致性能非常的低下。
2. Hadoop MapReduce核心思想
从MapReduce自身的命名特点可以看出,MapReduce由两个阶段组成:Map阶段 和Reduce阶段。
(1)分布式的运算程序往往需要分成至少2个阶段。
(2)第一个阶段的MapTask并发实例,完全并行运行,互不相干。
(3)第二个阶段的ReduceTask并发实例互不相干,但是他们的数据依赖于上一个阶段的所有MapTask并发实例的输出。
(4)MapReduce编程模型只能包含一个Map阶段和一个Reduce阶段,如果用户的业务逻辑非常复杂,那就只能多个MapReduce程序,串行运行。
每一个Map阶段和Reduce阶段都可以由多个Map Task和Reduce Task
实际应用中我们只需编写map()和reduce()两个函数,即可完成简单的分布式程序的 设计。
map()函数以key/value对作为输入,产生另外一系列key/value对作为中间输出 写入本地磁盘。
MapReduce框架会自动将这些中间数据按照key值进行聚集,且key 值相同(用户可设定聚集策略,默认情况下是对key值进行哈希取模)的数据被统一 交给reduce()函数处理。
reduce()函数以key及对应的value列表作为输入,经合并key相同的value值后, 产生另外一系列key/value对作为最终输出写入HDFS。
hadoop MapReduce对外提供了5个可编程组件,分别是 InputFormat、Mapper、Partitioner、Reducer和OutputFormat
3.MapReduce工作机制
剖析MapReduce运行机制
过程描述
- 客户端:提交MapReduce作业
- YARN资源管理器,负责协调集群上计算机资源的分配
- YARN节点管理器,负责启动和监视集群中机器上的计算容器(container)
- MapReduce的application master,负责协调运行MapReduce作业的任务。他和MapReduce任务在容器中运行,这些容器有资源管理器分配并由节点管理器进行管理
- 分布式文件系统(一般为HDFS),用来与其他实体间共享作业文件
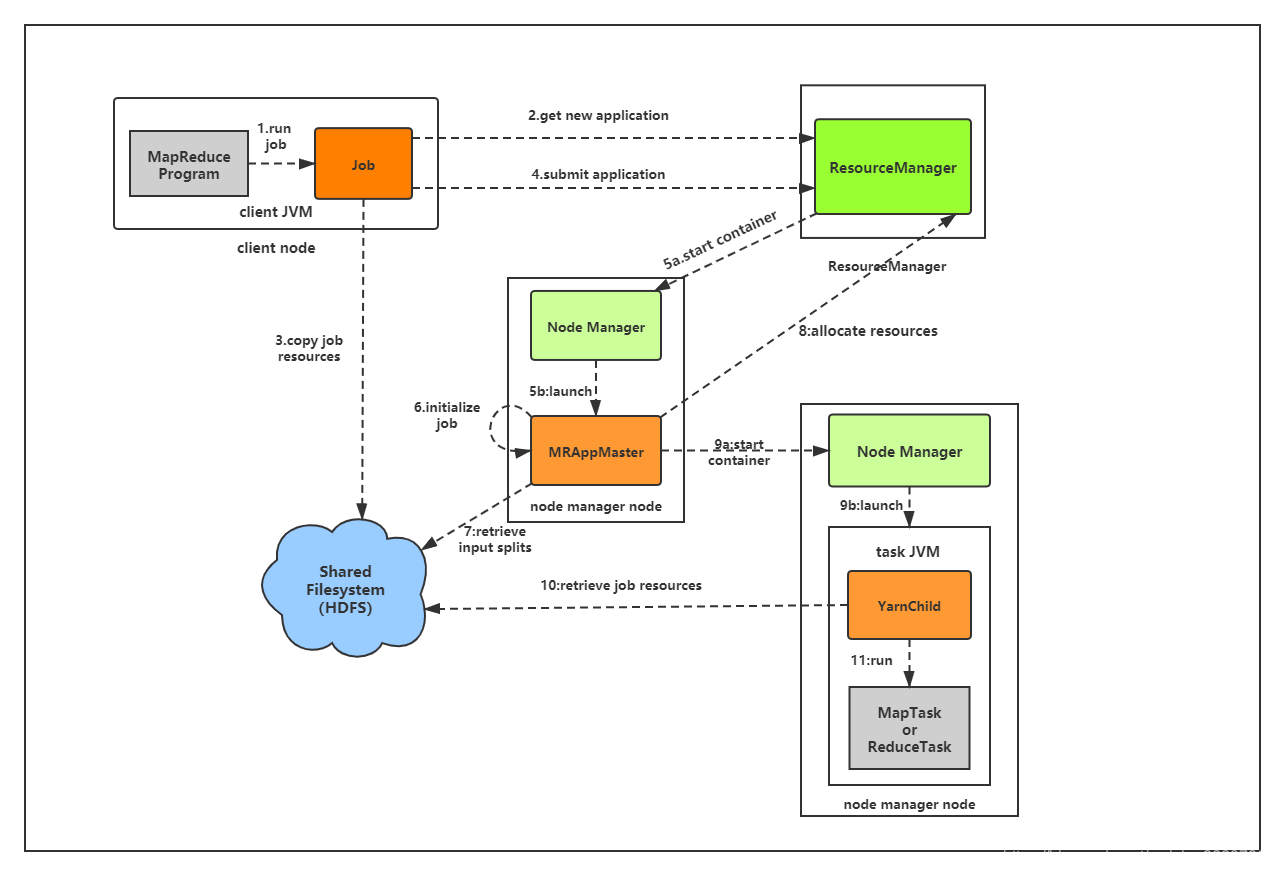
第一阶段:作业提交(图1-4步)
步骤:
Job的submit()方法创建一个内部的JobSummiter实例,并且调用其submitJobInternal()方法。提交作业后,waitForCompletion()每秒轮询作业的进度,如果发现自上次报告后有改变,便把进度报告到控制台。作业完成后,如果成功,就显示作业计数器;如果失败,则导致作业失败的错误被记录到控制台。
1.客户端提交作业Job,并轮询监控作业进度和状态;
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1217
1217

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









