









一、总览
Hadoop 的四大组件:
- HDFS:分布式存储系统。
- MapReduce:分布式计算系统。
- YARN: Hadoop 的资源调度系统。
- Common: 以上三大组件的底层支撑组件,主要提供基础工具包和 RPC 框架等。
Mapreduce 是一个分布式运算程序的编程框架,是用户开发“基于 hadoop的数据分析应用”的核心框架。 Mapreduce 核心功能是将用户编写的业务逻辑代码和自带默认组件整合成一个完整的分布式运算程序,并发运行在一个 hadoop 集群上。
MapReduce是一种编程模型,用于大规模数据集(大于1TB)的并行运算。 概念"Map(映射)“和"Reduce(归约)”,是它们的主要思想,都是从函数式编程语言里借来的,还有从矢量编程语言里借来的特性。 它极大地方便了编程人员在不会分布式并行编程的情况下,将自己的程序运行在分布式系统上。
二、执行原理
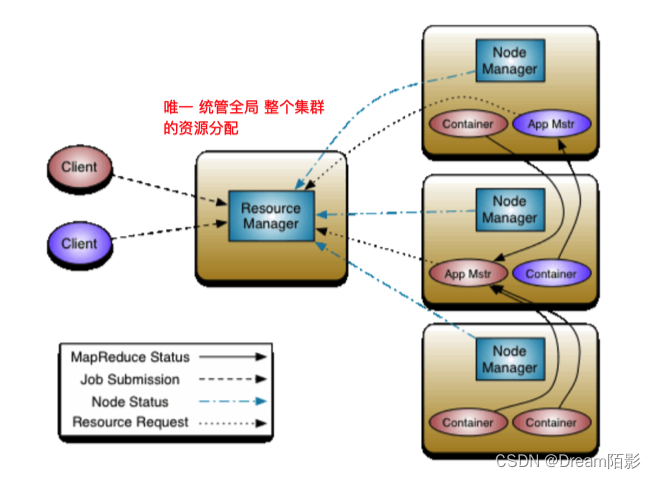
在MR程序运⾏时,有五个独⽴的进程:
- YarnRunner:⽤于提交作业的客户端程序
- ResourceManager:yarn资源管理器,是在系统中的所有应⽤程序之间仲裁资源的最终权威,即管理整个集群上的所有资源分配,内部含有⼀个Scheduler(资源调度器)
- NodeManager:yarn节点管理器,是每台机器的资源管理器,也就是单个节点的管理者,负责启动和监视容器 (container)资源使⽤情况,并向ResourceManager及其 Scheduler报告使⽤情况
- Application Master:负责协调运⾏MapReduce作业的任务,他和任务都在容器中运⾏,这些容器由资源管理器分配并由节点管理器进⾏管理。实际上是框架的特定的库,每启动⼀个应⽤程序,都会启动⼀个AM,它的任务是与ResourceManager协商资源,并与NodeManager⼀起执⾏和监视任务
- HDFS:⽤于共享作业所需⽂件。
三、MapReduce作业运行流程:
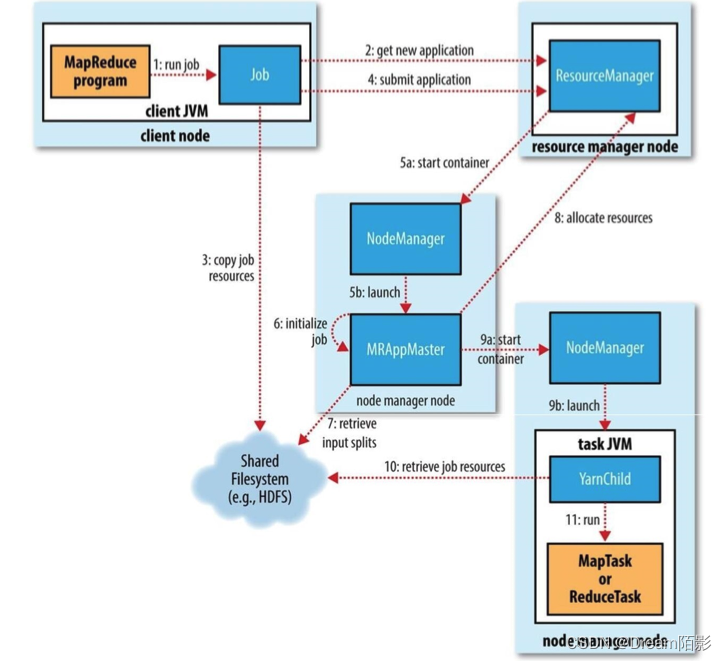
作业提交(Job Submission)
在mapreduce程序的job类中,通过set Configuration对象,得到相应的job对象,在job对象中指定Mapper类、Reducer类,Job类等属性后,调⽤waitForCompletion方法提交并等待job执行,waitForCompletion方法每秒轮询作业的进度,内部封装了submit()⽅法,⽤于创建JobCommiter实例,并且调⽤其的submitJobInternal⽅法。提交成功后,如果有状态改变,就会把进度报告到控制台。错误也会报告到控制台。
JobCommiter实例会向ResourceManager申请⼀个新应⽤ID,⽤于MapReduce作业 ID。这期间JobCommiter会检查作业指定的输出(output)目录。例如,如果该输出目录没有被指定或者已经存在,作业不会被提交且一个错误被抛出给 MapReduce 程序。也会为作业计算输入分片(input splits)。如果分片不能被计算(可能因为输入路径(input paths)不存在),该作业不会被提交且一个错误被抛出给 MapReduce 程序。
如果成功申请到ID,就会将运⾏作业所需要的资源上传到⼀个⽤ID命名的⽬录下的HDFS上。资源包括作业 JAR 文件,配置文件以及计算的输入分片。作业 JAR 文件以一个高副本因子(a high replication factor)进行拷贝(由 mapreduce.client.submit.file.replication 属性控制,副本个数默认值为 10),所以在作业任务运行时,在集群中有很多的作业 JAR 副本供节点管理器来访问。
准备⼯作已经做好,再通知ResourceManager调⽤submitApplication⽅法提交作业。
作业初始化(Job Initialization)
ResourceManager调⽤submitApplication⽅法后,会通知Yarn调度器 (Scheduler),调度器分配⼀个容器,在节点管理器的管理下在容器中启动 application master进程。该进程被节点管理器(NodeManager)管理。
MapReduce 作业的 application master 是一个 Java 应用,它的主类是 MRAppMaster。它通过创建一定数量的簿记对象(bookkeeping object)跟踪作业进度来初始化作业,该簿记对象接受任务报告的进度和完成情况。接下来,application master 从hdfs共享文件系统中获取客户端计算的输入分片。然后它为每个分片创建一个 map 任务,同样创建由 mapreduce.job.reduces 属性控制的多个reduce 任务对象(或者在 Job 对象上通过 setNumReduceTasks() 方法设置)。任务ID在此时分配。
Applcation master 必须决定如何运行组成 MapReduce 作业的任务。如果作业比较小,application master 可能选择在和它自身运行的 JVM 上运行这些任务。这种情况发生的前提是,application master 判断分配和运行任务在一个新的容器上的开销超过并行运行这些任务所带来的回报,据此和顺序地在同一个节点上运行这些任务进行比较。这样的作业被称为 uberized,或者作为一个 uber 任务运行。
一个小的作业具有哪些资格?默认的情况下,它拥有少于 10 个 mapper,只有一个 reducer,且单个输入的 size 小于 HDFS block 的。(注意,这些值可以通过 mapreduce.job.ubertask.maxmaps, mapreduce.job.ubertask.maxreduces, mapreduce.job.ubertask.maxbytes 进行设置)。Uber 任务必须显示地将 mapreduce.job.ubertask.enable 设置为 true。
最后,在任何任务运行之前, application master 调用 OutputCommiter 的 setupJob() 方法。系统默认是使用 FileOutputCommiter,它为作业创建最终的输出目录和任务输出创建临时工作空间(temporary working space)。
任务分配(Task Assignment)
如果作业没有资格作为 uber 任务来运行,那么 application master 为作业中的 map 任务和 reduce 任务向资源管理器(ResourceManager)请求容器(container)。首先要为 map 任务发送请求,该请求优先级高于 reduce 任务的请求,因为所有的 map 任务必须在 reduce 的排序阶段(sort phase)能够启动之前完成。reduce 任务的请求至少有 5% 的 map 任务已经完成才会发出(可配置)。
reduce 任务可以运行在集群中的任何地方,但是 map 任务的请求有数据本地约束(data locality constraint),调度器尽力遵守该约束(try to honor)。在最佳的情况下,任务的输入是数据本地的(data local)-- 也就是任务运行在分片驻留的节点上。或者,任务可能是机架本地的(rack local),也就是和分片在同一个机架上,而不是同一个节点上。有一些任务既不是数据本地的也不是机架本地的,该任务从不同机架上面获取数据而不是任务本身运行的节点上。对于特定的作业,你可以通过查看作业计数器(job’s counters)来确定任务的位置级别(locality level)。
请求也为任务指定内存需求和 CPU 数量。默认,每个 map 和 recude 任务被分配 1024 MB的内存和一个虚拟的核(virtual core)。这些值可以通过如下属性(mapreduce.map.memory.mb, mapreduce.reduce.memory.mb, mapreduce.map.cpu.vcores, mapreduce.reduce.cpu.vcores)在每个作业基础上进行配置(遵守 Memory settings in YARN and MapReduce 中描述的最小最大值)。
任务执行
一旦资源调度器在一个特定的节点上为一个任务分配一个容器所需的资源,application master 通过连接节点管理器来启动这个容器。任务通过一个主类为 YarnChild 的 Java 应用程序来执行。在它运行任务之前,它会将任务所需的资源本地化,包括作业配置,JAR 文件以及一些在分布式缓存中的文件。最后,它运行 map 或者 reduce 任务。
YarnChild 在一个指定的 JVM 中运行,所以任何用户自定义的 map 和 reduce 函数的 bugs(或者甚至在 YarnChild)都不会影响到节点管理器(NodeManager) – 比如造成节点管理的崩溃或者挂起。
每个任务能够执行计划(setup)和提交(commit)动作,它们运行在和任务本身相同的 JVM 当中,由作业的 OutputCommiter 来确定。对于基于文件的作业,提交动作把任务的输出从临时位置移动到最终位置。提交协议确保当推测执行可用时,在复制的任务中只有一个被提交,其他的都被取消掉。
进度和状态的更新
MapReduce 作业是长时间运行的批处理作业(long-running batch jobs),运行时间从几十秒到几小时。由于可能运行时间很长,所以用户得到该作业的处理进度反馈是很重要的。
作业和任务都含有一个状态,包括运行状态、maps 和 reduces 的处理进度,作业计数器的值,以及一个状态消息或描述(可能在用户代码中设置)。这些状态会在作业的过程中改变。那么它是如何与客户端进行通信的?
当一个任务运行,它会保持进度的跟踪(就是任务完成的比例)。对于 map 任务,就是被处理的输入的比例。对于 reduce 任务,稍微复杂一点,但是系统任然能够估算已处理的 reduce 输入的比例。通过把整个过程分为三个部分,对应于 shuffle 的三个阶段。例如,如果一个任务运行 reducer 完成了一半的输入,该任务的进度就是 5/6,因为它已经完成了 copy 和 sort 阶段(1/3 each)以及 reduce 阶段完成了一半(1/6)。
MapReduce 的进度组成进度不总是可测的,但是它告诉 Hadoop 一个任务在做的一些事情。例如,任务的写输出记录是有进度的,即使不能用总进度的百分比(因为它自己也可能不知道到底有多少输出要写,也可能不知道需要写的总量)来表示进度报告非常重要,Hadoop 不会使一个报告进度的任务失败(not fail a task that’s making progress)。
如下的操作构成了进度:
- 读取输入记录(在 mapper 或者 reducer 中)。
- 写输出记录(在 mapper 或者 reducer 中)。
- 设置状态描述(由 Reporter 的或 TaskAttempContext 的 setStatus() 方法设置)。
- 计数器的增长(使用 Reporter 的 incrCounter() 方法 或者 Counter 的 increment() 方法)。
- 调用 Reporter 的或者 TaskAttemptContext 的 progress() 方法。
任务有一些计数器,它们在任务运行时记录各种事件,这些计数器要么是框架内置的,例如:已写入的map输出记录数,要么是用户自定义的。
当 map 或 reduce 任务运行时,子进程使用 umbilical 接口和父 application master 进行通信。任务每隔三秒钟通过 umbilical 接口报告其进度和状态(包括计数器)给 application master,application master会形成一个作业的聚合视图。
在作业执行的过程中,客户端每秒通过轮询 application master 获取最新的状态(间隔通过 mapreduce.client.progressmonitor.polinterval 设置)。客户端也可使用 Job 的 getStatus() 方法获取一个包含作业所有状态信息的 JobStatus 实例,过程如下:
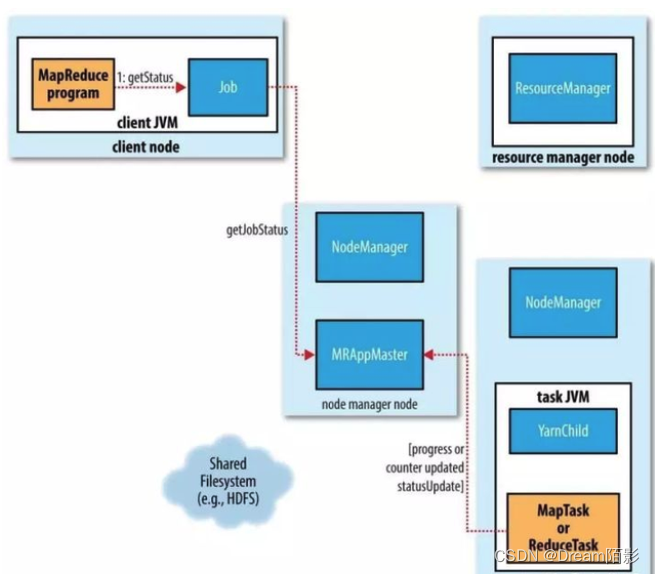
作业完成(Job Completion)
当 application master 接受到最后一个任务完成的通知,它改变该作业的状态为 “successful”。当 Job 对象轮询状态,它知道作业已经成功完成,所以它打印一条消息告诉用户以及从 waitForCompletion() 方法返回。此时,作业的统计信息和计数器被打印到控制台。
Application master 也可以发送一条 HTTP 作业通知,如果配置了的话。当客户端想要接受回调时,可以通过 mapreduce.job.end-notification.url 属性进行配置。
最后,当作业完成,application master 和作业容器清理他们的工作状态(所以中间输入会被删除),然后 OutputCommiter 的 commitJob() 方法被调用。作业的信息被作业历史服务器存档,以便日后用户查询。
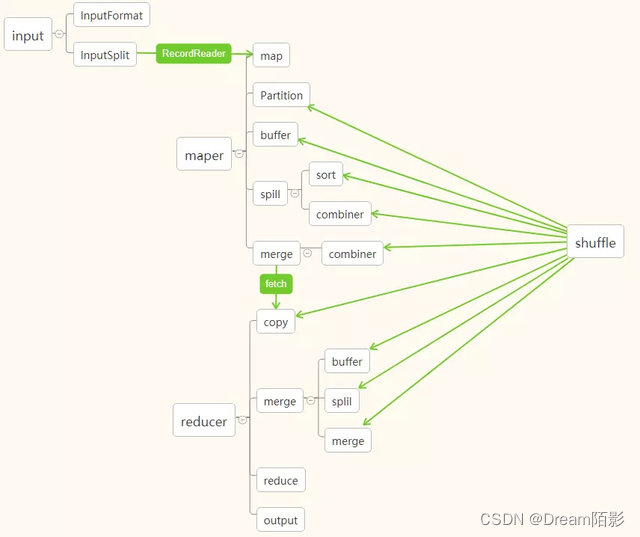
四、MapReduce计算流程
官方流程图:
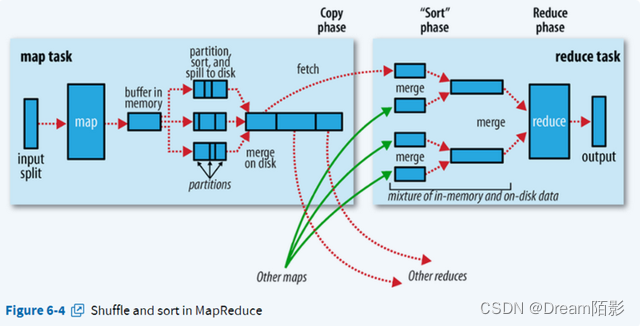
处理结构:















 4969
4969











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









