







 本文介绍了Python数据可视化中的14种常见图表,包括条形图、线形图、饼图、直方图、面积图、点阵图、散点图、气泡图、雷达图、象形图、样条图、箱形图和小提琴图。通过plotly和seaborn库展示了各类图表的代码实现,并探讨了它们在数据解释和决策辅助中的应用。
本文介绍了Python数据可视化中的14种常见图表,包括条形图、线形图、饼图、直方图、面积图、点阵图、散点图、气泡图、雷达图、象形图、样条图、箱形图和小提琴图。通过plotly和seaborn库展示了各类图表的代码实现,并探讨了它们在数据解释和决策辅助中的应用。

写在前面
收集数据后,需要对其进行解释和分析,以深入了解数据所蕴含的深意。而这个含义可以是关于模式、趋势或变量之间的关系。
数据解释是通过明确定义的方法审查数据的过程,有助于为数据赋予意义并得出相关结论。
数据分析是对数据进行排序、分类和总结以回答研究问题的过程。我们应该快速有效地完成数据分析,并得出脱颖而出的结论。
而不同可视化的数据绘图类型是实现以上目标的一个重要方面。随着数据的不断增长,这种需求也在持续增长,因此数据可视化图是非常重要的。但是,数据可视化类型图繁多,在实际工作中,要选择最适合当前业务或数据的类型通常很棘手。
可视化辅助决策
研究表明,人眼是一个高带宽大量视觉信号并行GPU,带宽在2.339G/s,相当于一个两万兆网卡,具有超强的模式识别能力,且对可视符号的处理速度比数字或者文本快多个数量级,在大数据时代,数据可视化是人们洞察数据内涵、理解数据蕴藏价值的有力工具。
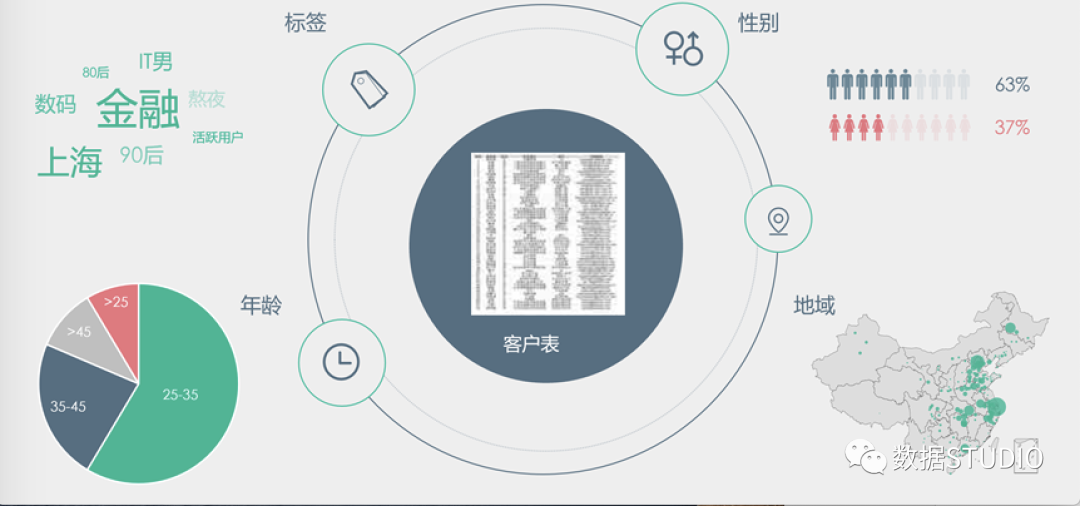
因此,可视化常常被用来辅助决策,如上图,中间的一张密密麻麻的客户表,到底能得出什么有价值的信息指导决策呢?光看一行行一列列的数据,可能需要很久才能得出一些结论,但是经过可视化,我们可以轻松的以各种形式的可视化快速掌握结论,从而辅助决策。
这就是:可视分析,即将信息提炼为知识,起到“观物至知”对作用,便于决策者从复杂、大量、多维度的数据中快速挖掘有效信息。
本文总结介绍了多种可视化图及其适合使用场景,并同时展示使用了常用的绘图包(plotly、 seaborn 和 matplotlib )绘制这些图的代码。
条形图
条形图是用矩形条显示分类数据的图形。这些条的高度或长度与它们所代表的值成正比。条形可以是垂直的或水平的。垂直条形图有时也称为柱形图。
以下是按年指示加拿大人口的条形图。
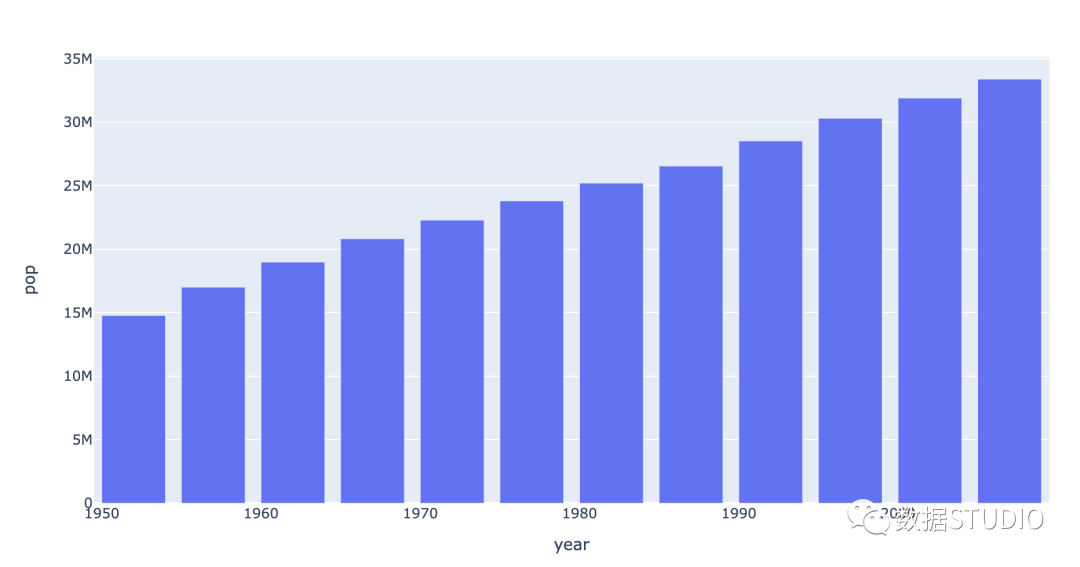
条形图适合应用到分类数据对比,横置时也称条形图。注意: 条形图数据条数不宜超过12条;条形图数据条数不宜超过30条。
plotly code
import plotly.express as px
data_canada = px.data.gapminder().query("country == 'Canada'")
fig = px.bar(data_canada, x='year', y='pop')
fig.show()
seaborn code
import seaborn as sns
sns.set_context({'figure.figsize':[14, 8]})
sns.set_theme(style="whitegrid")
ax = sns.barplot(x="year", y="pop", data=data_canada)
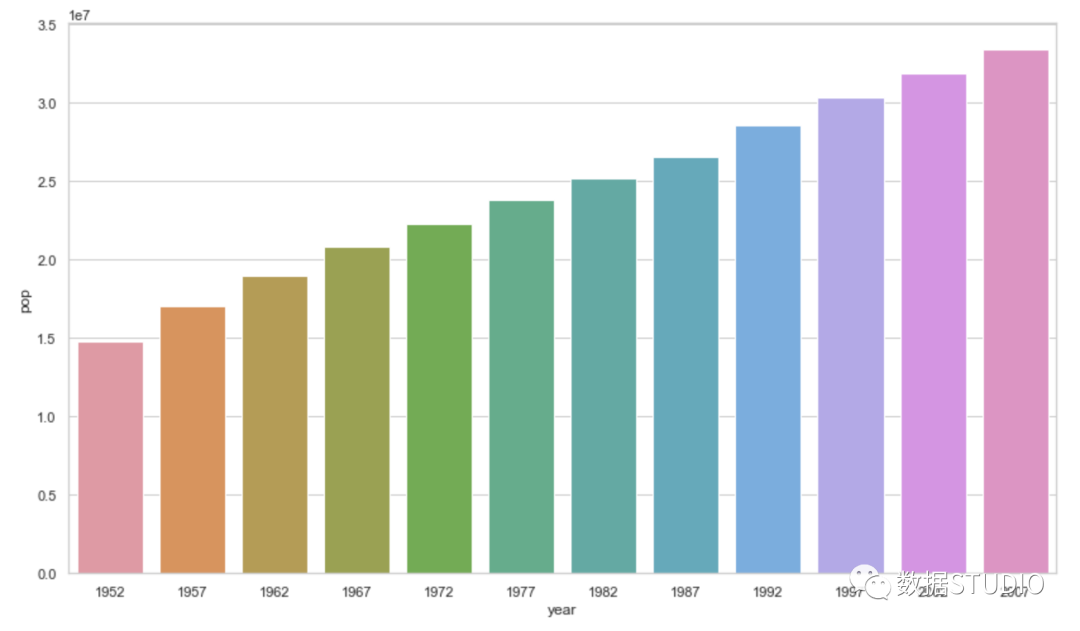
改变seaborn图表大小的三种方法
1. seaborn自带的设置:
sns.set_context({'figure.figsize':[20, 20]})
sns.boxplot(x)
2. 结合matplotlib:
from matplotlib import pyplot as plt
import seaborn as sns
plt.figure(figsize=(20,20))
# 或者 plt.rcParams['figure.figsize'] = (20.0, 20.0)
sns.distplot(launch.date)
plt.show()
3. displot和jointplot中
ax = sns.boxplot(x)
ax.figure.set_size_inches(12,6)
以下是条形图的类型
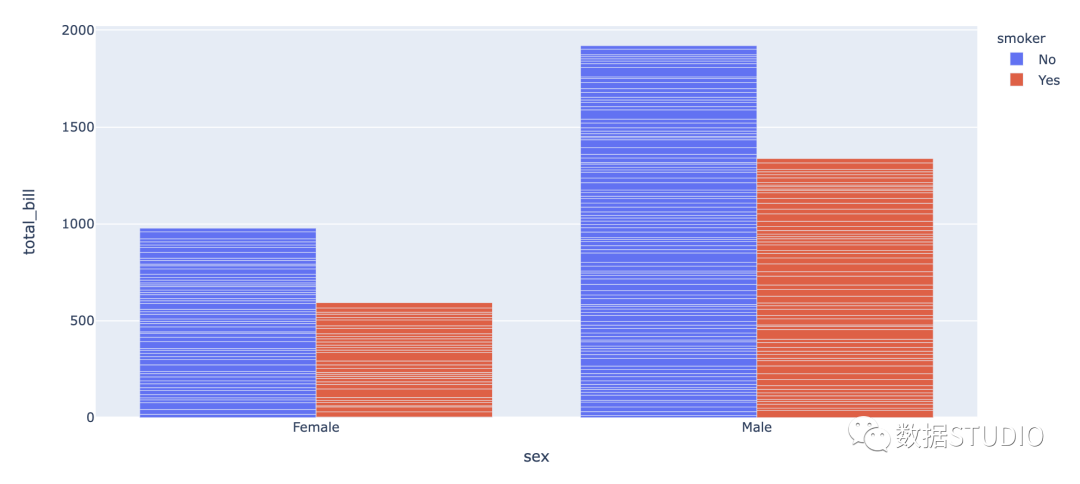
分组条形图
当数据集具有需要在图形上可视化的子组时,将使用分组条形图。亚组通过不同的颜色进行区分。下面是这样一个图表的说明:
plotly code
import plotly.express as px
df = px.data.tips()
fig = px.bar(df, x="sex", y="total_bill",
color='smoker', barmode='group',
height=500)
fig.show()
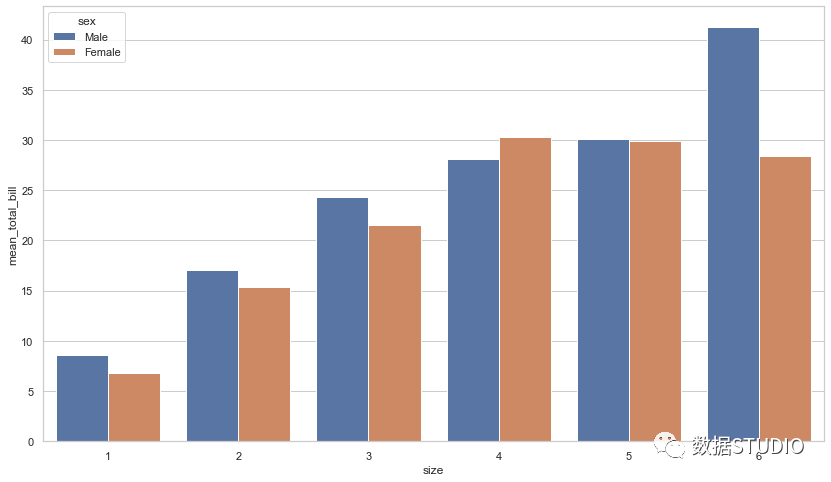
seaborn code
import seaborn as sb
df = sb.load_dataset('tips')
df = df.groupby(['size', 'sex']).agg(mean_total_bill=("total_bill", 'mean'))
df = df.reset_index()
sb.barplot(x="size", y="mean_total_bill",
hue="sex", data=df)
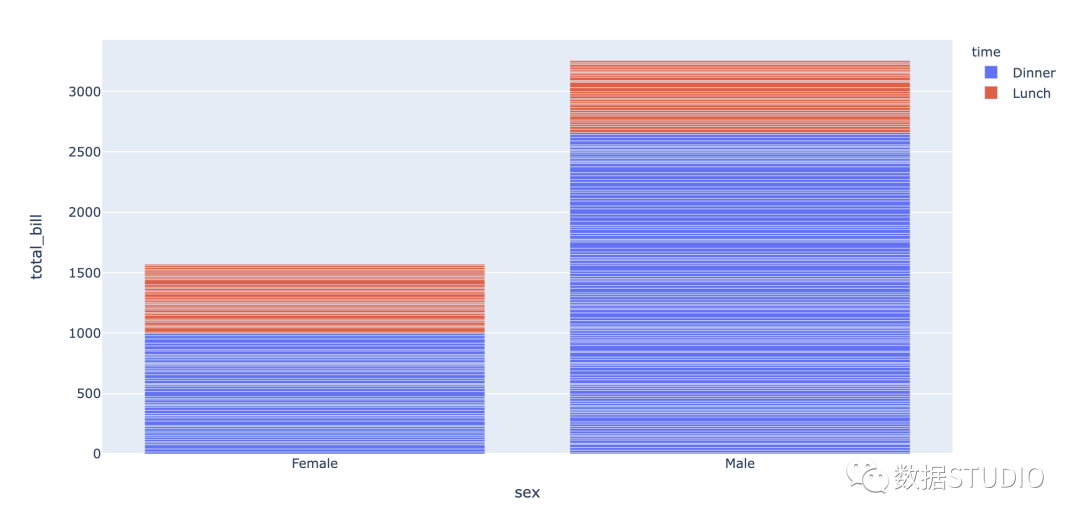
堆积条形图
堆叠条形图用于显示数据集子组。堆叠柱状图将每个柱子进行分割以显示相同类型下各个数据的大小情况。
分类:
-
堆积柱状图:
比较同类别各变量和不同类别变量总和差异。 -
百分比堆积柱状图:
适合展示同类别的每个变量的比例。
数据可视化类型的概念与代码.jpg
plotly code
import plotly.express as px
df = px.data.tips()
fig = px.bar(df, x="sex", y="total_bill", color='time')
fig.show()
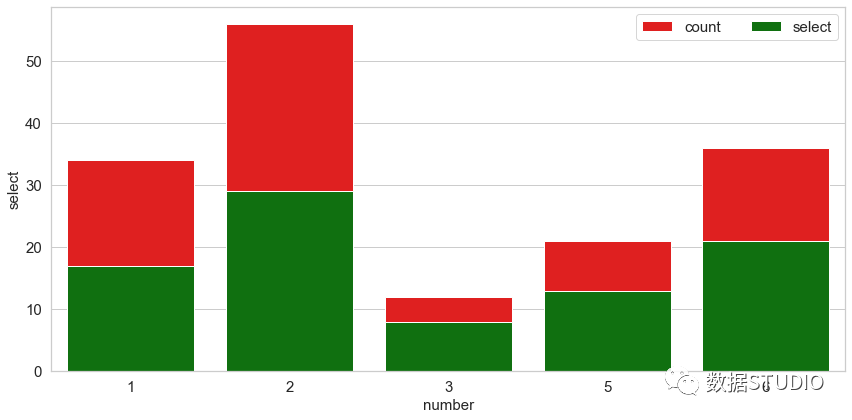
Seaborn code
import pandas
import matplotlib.pylab as plt
import seaborn as sns
plt.rcParams["figure.figsize"] = [12, 6]
plt.rcParams["figure.autolayout"] = True
df = pandas.DataFrame(dict(
number=[2, 5, 1, 6, 3],
count=[56, 21, 34, 36, 12],
select=[29, 13, 17, 21, 8]
))
bar_plot1 = sns.barplot(x='number', y='count',
data=df, label="count",
color="red")
bar_plot2 = sns.barplot(x='number', y='select',
data=df, label="select",
color="green")
plt.legend(ncol=2, loc="upper right",
frameon=True, fontsize=15)
plt.xlabel('number', fontsize=15)
plt.ylabel('select',fontsize=15)
plt.xticks(fontsize=15)
plt.yticks(fontsize=15)
plt.show()
分段条形图
这是堆叠条形图的类型,其中每个堆叠条形显示其离散值占总值的百分比。总百分比为 100%。
线形图
它将一系列数据点显示为标记。这些点通常按其 x 轴值排序。这些点用直线段连接。折线图用于可视化一段时间内数据的趋势。
以下是折线图中按年计算的加拿大预期寿命的说明。
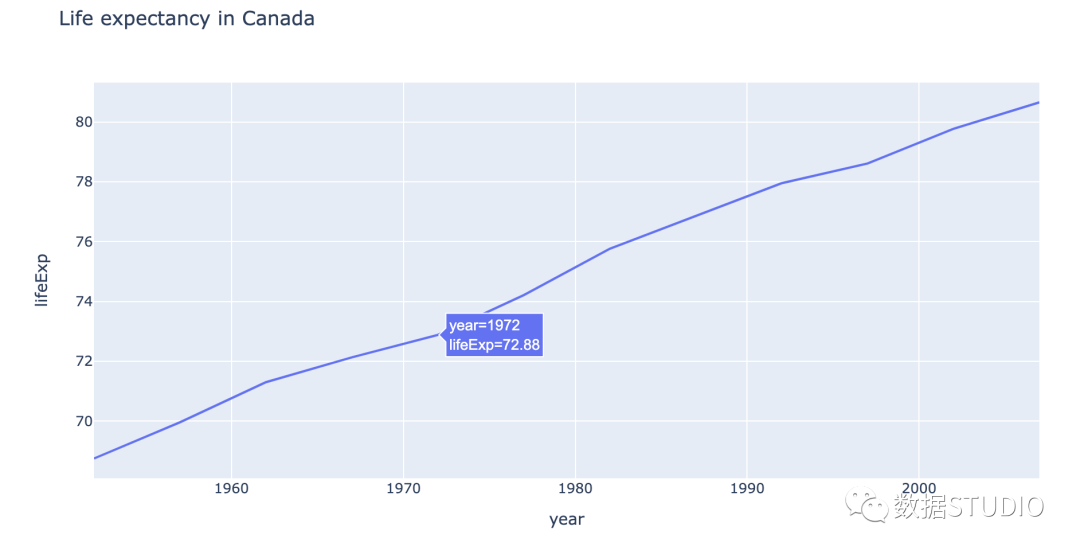
以下是如何在情节中做到这一点:
import plotly.express as px
df = px.data.gapminder().query("country=='Canada'")
fig = px.line(df, x="year", y="lifeExp",
title='Life expectancy in Canada')
fig.show()
以下是在 seabron 中的操作方法:
import seaborn as sns
sns.lineplot(data=df,
x="year",
y="lifeExp")
以下是折线图的类型
简单线图
简单的折线图仅在图形上绘制一条线。其中一个轴定义了自变量。另一个轴包含一个依赖于它的变量。
多线图
多条线图包含多条线。它们代表数据集中的多个变量。这种类型的图表可用于研究同一时期的多个变量。
import plotly.express as px
df = px.data.gapminder().query("continent == 'Oceania'")
fig = px.line(df, x='year', y='lifeExp', color='country')fig.show()
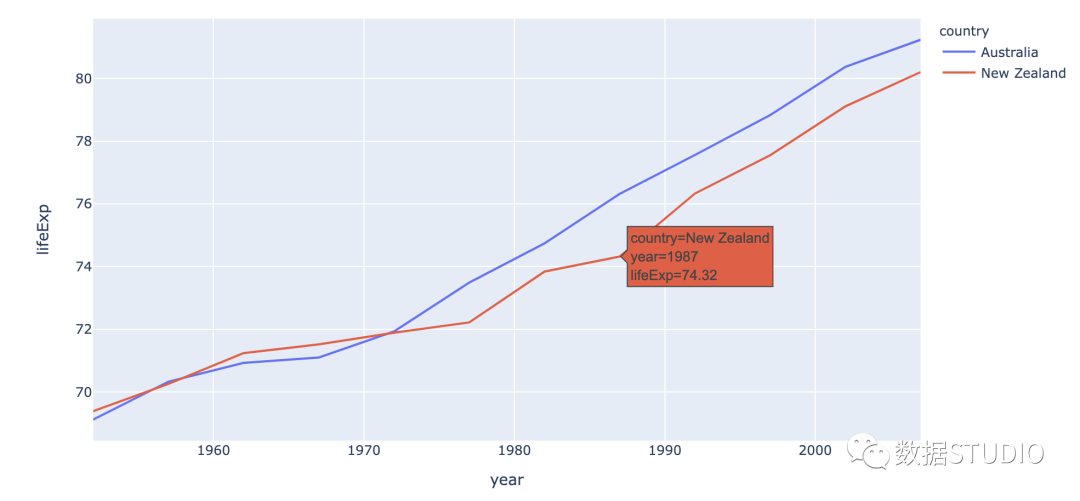
seaborn code
import seaborn as snssns.line
plot(data=df, x='year',
y='lifeExp', hue='country')
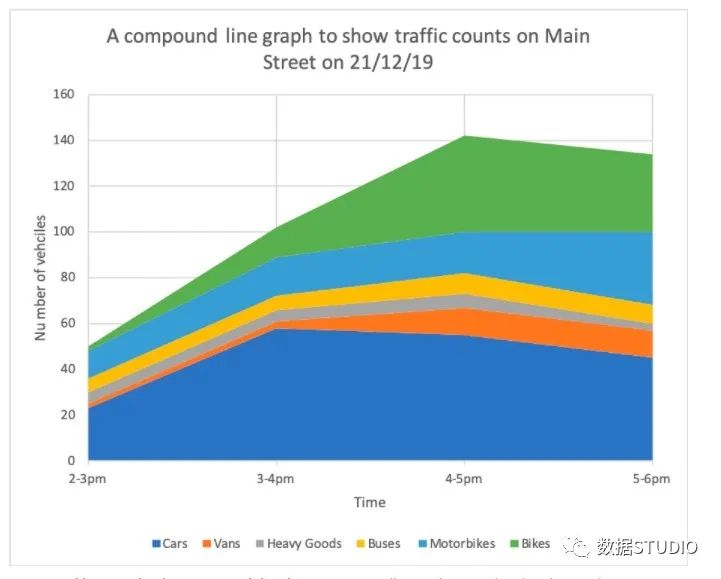
复合折线图
它是简单折线图的扩展。它用于处理来自较大数据集的不同数据组。它的每个折线图都向下阴影到 x 轴。它让每一组彼此堆叠。
复合折线图也可以称作堆叠面积图,堆叠面积图和基本面积图一样,唯一的区别就是图上每一个数据集的起点不同,起点是基于前一个数据集的,用于显示每个数值所占大小随时间或类别变化的趋势线,展示的是部分与整体的关系。
适用: 堆叠面积图不适用于表示带有负值的数据集。非常适用于对比多变量随时间变化的情况。
分类:
-
堆积面积图
同类别各变量和不同类别变量总和差异。 -
百分比堆积面积图
比较同类别的各个变量的比例差异。
饼形图
饼图是圆形统计图形。为了说明数字比例,将其分为切片。在饼图中,对于每个切片,其每个弧长都与其代表的数量成正比。中心角和面积也是成比例的。它以切片馅饼命名。饼图广泛得应用在各个领域,用于表示不同分类的占比情况,通过弧度大小来对比各种分类。
适用: 适用于比较一个数据分类上各个模块的大小占比的需求。
注意事项: 饼图不适用于多分类的数据,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









