






python爬虫笔记,2023年5月27日写的,一次性分享出来。
requests
pip install requests
beautifulSoup
案例:爬取豆瓣top250榜电影名称
查看user-agent的小工具: 获取浏览器UA(userAgent)信息
import requests
from bs4 import BeautifulSoup
header = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36'}
url = 'https://movie.douban.com/top250'
response = requests.get(url, headers=header)
content = response.text
soup = BeautifulSoup(content, 'html.parser')
all_titles = soup.findAll('span', attrs={'class': 'title'})
for title in all_titles:
print(title.get_text())
xpath
# html/xml解析
pip install lxml
from lxml import etree
tree = etree.HTML(content)
titles = tree.xpath('//*[@id="content"]/div/div[1]/ol//li/div/div[2]/div[1]/a/span[1]/text()')
print(titles)
cookie的处理
session = requests.session()
# 会携带上下文的cookie
防盗链
溯源,当前请求的上一级
案例中使用防盗链下载梨视频
# -*- encoding: utf-8 -*-
__date__ = '2023/05/28 10:33:03'
# this python shell is used to download video from pearvideo
import requests
url = 'https://www.pearvideo.com/video_1413858'
contant_id = url.split('/')[-1].split('_')[-1]
session = requests.Session()
session.get(url)
request_json_url = 'https://www.pearvideo.com/videoStatus.jsp?contId=1413858&mrd=0.051782001313967596'
headers = {'Referer': url}
res_json = session.get(url=request_json_url, headers=headers).json()
print(res_json)
systemTime = res_json['systemTime']
srcUrl = res_json['videoInfo']['videos']['srcUrl']
videoImg = res_json['videoInfo']['video_image']
videoUrl = srcUrl.replace(systemTime, 'cont-'+contant_id)
print(videoUrl, videoImg)
basePath = './files/' + contant_id
import os
if not os.path.exists(basePath):
os.makedirs(basePath)
# download video image
img_save_path = os.path.join(basePath, videoImg.split('/')[-1])
with open(img_save_path, 'wb') as file:
file.write(session.get(videoImg).content)
# download video
video_save_path = os.path.join(basePath, videoUrl.split('/')[-1])
with open(video_save_path, 'wb') as file:
file.write(session.get(videoUrl).content)
代理
通过代理ip访问真实的网站
国内免费的HTTP代理:2023年5月28日7时 国内最新免费HTTP代理IP - 站大爷 - 企业级高品质Http代理IP_Socks5代理服务器_免费代理IP
url = 'http://www.baidu.com'
import requests
proxy_ip = 'https:114.251.193.153:3128'
proxies = {
"https": proxy_ip
}
response = requests.get(url=url, proxies=proxies)
# 直接爬取会出现乱码的问题
text = response.content.decode('utf-8')
print(text)
多线程
线程和进程的关系
线程:
进程:
多线程的创建和使用
from threading import Thread
def func(name):
for i in range(100):
print('func() called', i)
class MyThread(Thread):
def run(self):
for i in range(100):
print('mythread func() called', i)
if __name__ == '__main__':
# t = Thread(target=func, args=('shigen',))
# t.start()
t = MyThread()
t.start()
for i in range(100):
print(i)
多进程
和多线程的API相似
from multiprocess import Process
线程池和进程池
from concurrent.futures import ThreadPoolExecutor, ProcessPoolExecutor
def fn(name):
for i in range(100):
print(name, i)
if __name__ == "__main__":
with ThreadPoolExecutor(50) as t:
for i in range(100):
t.submit(fn, name=f'线程执行{i}')
print('all done')
获得线程运行结果信息:
# 创建一个包含5条线程的线程池
executor = ThreadPoolExecutor(max_workers=5)
lists = [1, 2, 3, 4, 5, 7, 8, 9, 10]
start_time = time.time()
result = [data for data in executor.map(action, lists)]
print(result)
executor.shutdown()
print(time.time() - start_time)
协程
当程序遇见了IO操作的时候,可以选择性的切换到其他任务上
在单线程的条件下
- 微观上:一个任务一个任务的切换,切换条件一般是IO操作
- 宏观上:多个任务一起异步执行
import asyncio
async def download(url):
print(f'start downloading {url}')
await asyncio.sleep(2)
print('downloading finished')
async def main():
urls = [
'http://www.google.com',
'http://www.baidu.com',
'http://www.xiaomi.com'
]
tasks = []
for url in urls:
tasks.append(asyncio.create_task(download(url)))
await asyncio.wait(tasks)
if __name__ == '__main__':
asyncio.run(main())
http的携程
import asyncio
import aiohttp
basepath = './files/'
headers = {'Referer': 'https://xxxx.cn/'}
async def download(url):
print(f'start downloading {url}')
filename = url.split('/')[-2]
async with aiohttp.ClientSession() as session:
async with session.get(url=url, headers=headers) as resp:
with open(basepath + filename, mode='wb') as f:
f.write(await resp.content.read())
print(f'downloading {url} finished')
async def main():
urls = []
tasks = []
for url in urls:
tasks.append(asyncio.create_task(download(url)))
await asyncio.wait(tasks)
if __name__ == '__main__':
asyncio.run(main())
selenium
自动化测试,打开浏览器,像人一样操作浏览器
pip install selenium
安装驱动
解压到python解释器的位置,并重命名
tar -zxvf chromedriver_mac_arm64.zip
ll
which python3
mv chromedriver ~/opt/anaconda3/bin
测试
from selenium.webdriver import Chrome
# 创建浏览器对象
web = Chrome()
web.get('http://www.baidu.com')
print(web.get_window_size())
print(web.title)
可能遇到的问题: 解决mac无法打开chromedriver报错,由于无法验证开发人员,因此无法打开“ chromedriver”_webdriver mac 无法打开_奈暮希的博客-CSDN博客
爬取京东书籍
爬取京东上关于python的书籍信息,并保存成csv文件。
todo:部分页面的页面元素不一样,导致元素的查找存在问题。
from selenium import webdriver
from selenium.webdriver.common.by import By
import time
import pandas as pd
driver = webdriver.Chrome()
driver.get('https://www.jd.com/')
# 获取搜索框
search = driver.find_element(By.XPATH, '//*[@id="key"]')
# 获取查询按钮
button = driver.find_element(By.XPATH, '//*[@id="search"]/div/div[2]/button')
# 在搜索框中输入 Python
search.send_keys('Python')
# 点击查询按钮
button.click()
time.sleep(2)
# 获得商品
goods_list = driver.find_elements(By.XPATH, '//*[@id="J_goodsList"]/ul/li')
datas = []
for good in goods_list[:-1]:
# 此处用css选择器比较保险
img = good.find_element(By.CSS_SELECTOR, 'a > img').get_attribute('src')
name = good.find_element(By.CSS_SELECTOR, 'div > div.p-name.p-name-type-2 > a > em').text
prize = good.find_element(By.TAG_NAME, 'i').text
url_element = good.find_element(By.CSS_SELECTOR, 'div > a')
url = url_element.get_attribute('href')
url_element.click()
# 进入到新窗口
driver.switch_to.window(driver.window_handles[-1])
book_detail = driver.find_element(By.XPATH, '//*[@id="detail-tag-id-3"]/div[2]/div').text
author_detail = driver.find_element(By.XPATH, '//*[@id="detail-tag-id-4"]/div[2]/div').text
book_menu = driver.find_element(By.XPATH, '//*[@id="detail-tag-id-6"]/div[2]/div').text
# 打开详情页获得内容简介、作者简介和目录
print(img, name, prize, url)
datas.append({
'img': img,
'name': name,
'prize': prize,
'url': url,
'book_detail': book_detail,
'author_detail': author_detail,
'book_menu': book_menu,
})
# 关闭并切回到原来的窗口
driver.close()
driver.switch_to.window(driver.window_handles[0])
df = pd.DataFrame(datas)
df.to_csv('book_detail.csv', index=True, header=True)
暂时无法在飞书文档外展示此内容
无头浏览器
没有任何的界面,操作浏览器
# 创建配置对象
options = webdriver.ChromeOptions()
# 配置对象添加开启无界面模式的命令
options.add_argument('--headless')
# 配置对象添加禁用gpu的命令
options.add_argument('--disable-gpu')
# 实例化带有配置对象的driver对象
driver =Chrome(chrome_options=options)
代理ip
# 配置代理ip
options.add_argument('--proxy-server=http://150.138.253.70:808')
更换user-agent
# 更换User-Agent
options.add_argument('--user-agent=Opera/9.23 (X11; Linux x86_64; U; en)')
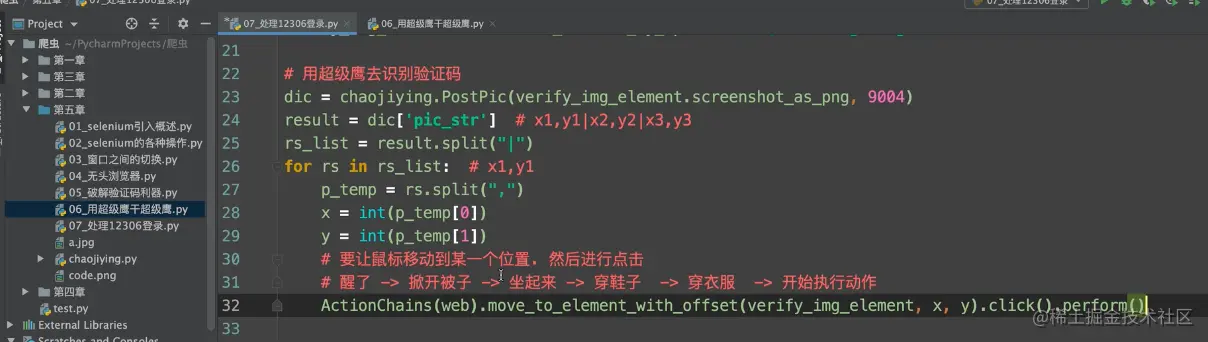
破解验证码
使用ocr或者超级鹰平台来识别验证码
识别图片的点击操作
题外话
当下这个大数据时代不掌握一门编程语言怎么跟的上时代呢?当下最火的编程语言Python前景一片光明!如果你也想跟上时代提升自己那么请看一下.

感兴趣的小伙伴,赠送全套Python学习资料,包含面试题、简历资料等具体看下方。

👉CSDN大礼包🎁:全网最全《Python学习资料》免费赠送🆓!(安全链接,放心点击)
一、Python所有方向的学习路线
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照下面的知识点去找对应的学习资源,保证自己学得较为全面。


二、Python必备开发工具
工具都帮大家整理好了,安装就可直接上手!
三、最新Python学习笔记
当我学到一定基础,有自己的理解能力的时候,会去阅读一些前辈整理的书籍或者手写的笔记资料,这些笔记详细记载了他们对一些技术点的理解,这些理解是比较独到,可以学到不一样的思路。

四、Python视频合集
观看全面零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

五、实战案例
纸上得来终觉浅,要学会跟着视频一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

六、面试宝典


简历模板
👉CSDN大礼包🎁:全网最全《Python学习资料》免费赠送🆓!(安全链接,放心点击)
若有侵权,请联系删除

















 598
598

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









