









冒泡排序
-
所谓冒泡排序,即是对于一个给定长度为n的无序数组,由初始位置开始,比较数组相邻两个元素,如果是逆序排列的,就交换它们的位置,重复多次之后,最大数就“沉”到了最下面的位置。第二次再从初始位置开始,将第二大的元素沉到倒数第二个位置。这样一直做n-1次,整个数组就是有序的了。
简单的说:每一个元素和下一个元素比较,如果小则交换位置 -
值得一提的是,在第一轮操作结束之后,第二轮的操作无需比较最后一位,因为最后一位已经是最大的元素了。所以对于一个长度为n的数组,整个算法消耗的时间为: (n-1)+(n-2)+…+1=n(n-1)/2,即时间复杂度为O(n^2)。同时,显而易见,整个算法只消耗一份数组的空间,所以空间复杂度为O(1)。
-
排序算法另一个重要的特性:稳定性。所谓稳定性,通俗地讲就是能保证排序前2个相等的数其在序列的前后位置顺序和排序后它们两个的前后位置顺序相同。即假定原数组2个相同的元素a[i]和a[j],在排序前a[i]在a[j]的前面,那么在排序之后,a[i]仍然在a[j]的前面。冒泡排序是一种稳定排序。
#冒泡
def bubbleSort(x):
if len(x)<=1:
return x
for i in range(len(x)-1):
for j in range(len(x)-1-i):
if x[j]>x[j+1]:
x[j],x[j+1]=x[j+1],x[j]
冒泡排序的优缺点总结:
优点:
空间复杂度T=O(1)
稳定排序
在排序过程中,整个数组趋向稳定
对于已经有序的数组,排序效率高
缺点:
效率低,时间复杂度T=O(n^2),上面提及的优化手段很容易失效(最小值在数组末尾)
交换次数多,交换效率低(每次交换只减少一组逆序对)
不能并发执行
选择排序
和冒泡排序一样,选择排序也是蛮力法的一种实际应用。
选择排序的思想,就是首先扫描整个数组,找到最小的元素,然后和第一个元素进行交换,如此一来就等同于将最小的元素放到它在有序表中最终的位置上。然后从第二个元素开始扫描整个表,找到剩余n-1个元素中最小的元素,与第二个元素交换位置。以此类推,在执行n-1遍之后,这个数组就自然有序了。(当然每次找最大的元素,与最后一个元素交换也是可行的)
#选择
def selectSort(x):
if len(x)<=1:
return x
for i in range(len(x)):
index=i
for j in range(i+1,len(x)):
if x[index]>x[j]:
index=j
#放到外层循环内存循环会找出最小的索引
x[i],x[index]=x[index],x[i]
直接插入排序
对于一个数组A[0,n]的排序问题,假设认为数组在A[0,n-1]排序的问题已经解决了。
考虑A[n]的值,从右向左扫描有序数组A[0,n-1],直到第一个小于等于A[n]的元素,将A[n]插在这个元素的后面。
直接插入排序的时间复杂度是O(n^2),空间复杂度是O(1),同时也是稳定排序。

- 未优化版本
def insertSort(x):
if len(x)<=1:
return x
for i in range(1,len(x)):
for j in range(i,0,-1):
if x[j]<x[j-1]:
x[j],x[j-1]=x[j-1],x[j]
- 优化版本
def insertSort2(x):
if len(x)<=1:
return x
for i in range(1,len(x)):
temp=x[i]
j=i
while j>0 and temp<x[j-1]:
#如果前一个比后一个大了,则把元素向后移
x[j]=x[j-1]
j=j-1
#经过while循环过后会得到合适的位置 j
x[j]=temp
总结:
自我感觉下面的优化版本才是真正的插入排序,上面的有点像把冒泡排序反过来了
希尔排序(高级算法)
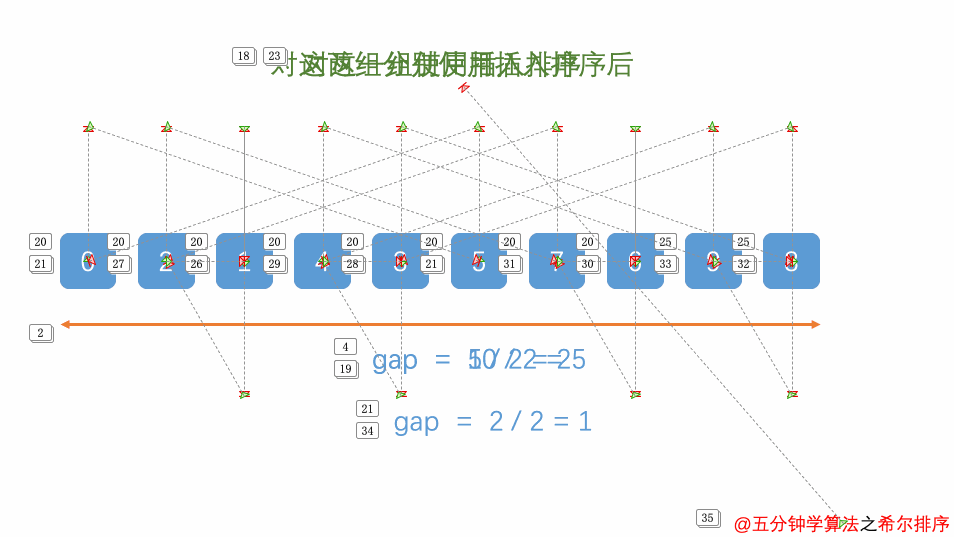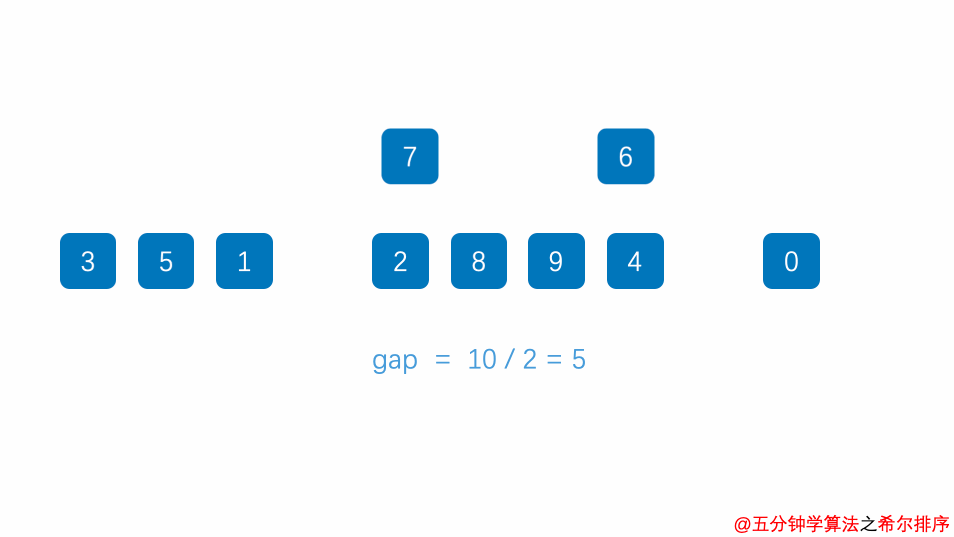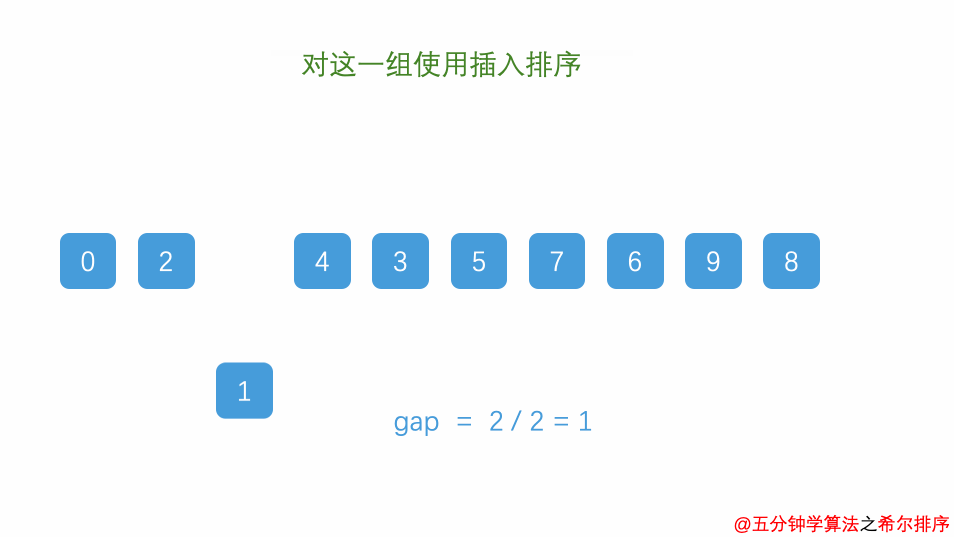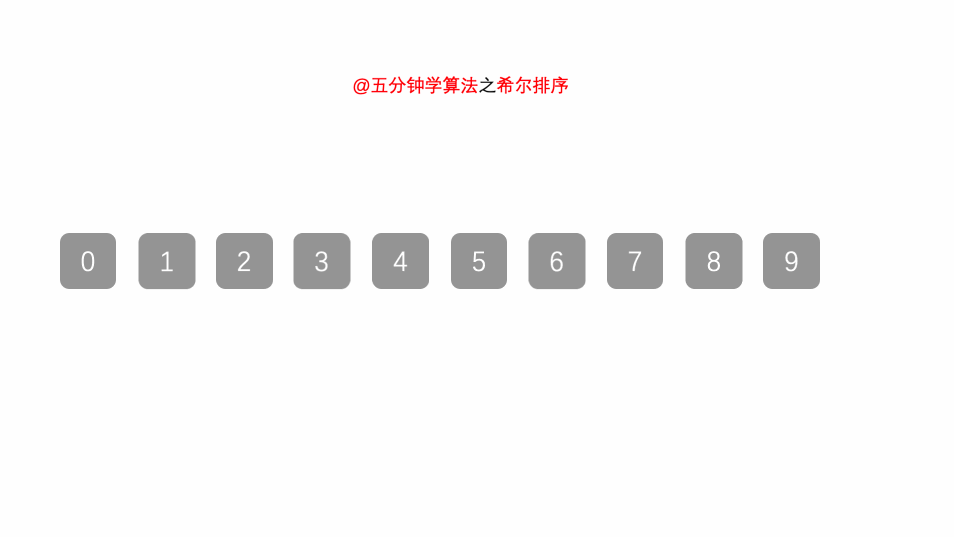
希尔排序就是按照下标一定增量进行分组,每组再按照直接插入算法排序,随着组的减少,每组的元素也越来越少,当组数减少至为1时,整个文件分成1组,算法便终止。
看图理解:
排序动画过程解释
-
首先,选择增量 gap = 10/2 ,缩小增量继续以 gap = gap/2 的方式
-
初始增量为 gap = 10/2 = 5,整个数组分成了 5 组
-
按划分为【 8 , 3 】,【 9 , 5 】,【 1 , 4 】,【 7 , 6 】,【 2 , 0 】
-
对这分开的 5 组分别使用
-
缩小增量 gap = 5/2 = 2,整个数组分成了 2 组
【 3 , 1 , 0 , 9 , 7 】,【 5 , 6 , 8 , 4 , 2 】
-
再缩小增量 gap = 2/2 = 1,整个数组分成了 1 组
【 0, 2 , 1 , 4 , 3 , 5 , 7 , 6 , 9 , 0 】
此时,只需要对以上数列进行简单的微调,不需要大量的移动操作即可完成整个数组的排序
动画解释出自:
作者:五分钟学算法
链接:https://www.jianshu.com/p/40dcc3b83ddc
来源:简书。
def shellSort(alist):
if len(alist)<=1:
return x
n=len(alist)
#为什么除以2:可以得到最多的只有2个数据的几组
dk=n//2
while dk>0:
n=len(alist)
for k in range(dk):
for i in range(k+dk,n,dk):
key = alist[i]
j=i-dk
while j>=k and alist[j]>key:
alist[j+dk]=alist[j]
j -= dk
alist[j+dk]=key
dk=dk//2
快速排序
同冒泡排序一样,快速排序也属于交换排序,通过元素之间的比较和交换位置来达到排序的目的。
不同的是,冒泡排序在每一轮只把一个元素冒泡到数列的一端,而快速排序在每一轮挑选一个基准元素,并让其他比它大的元素移动到数列一边,比它小的元素移动到数列的另一边,从而把数列拆解成了两个部分。

def quicksort(x):
if len(x)<=1:
return x
else:
base=x[0]
left=[ i for i in x[1:] if i<base ]
right=[ i for i in x[1:] if i>base ]
middle=[ i for i in x if i==base ]
#递归实现
return quicksort(left)+middle+quicksort(right)
归并排序
归并排序(Merge Sort),又称二路归并排序,是指将一个数组一分为二,对每一个子数组递归排序,最后将排好的子数组合并为一个有序数组的过程。归并排序,是“分治法”应用的完美实现。

通过图示,可以发现归并排序一共只需要两个步骤:
- 分:将原数组分为n个子数组,每个子数组长度为1(长度为1的数组自然有序)。
- 合:依次将两个相邻的有序数组,合并成一个有序数组,重复操作直至剩下一个有序数组。
def merageSort(x):
if len(x)<=1:
return x
middle=len(x)//2
#观察是怎么递归的
print(" ",x[middle:])
left=merageSort(x[middle:])
print(left)
right=merageSort(x[:middle])
print(left,right,merage(left,right))
return merage(left,right)
#合并两个集合
def merage(x,y):
c=[]
h=j=0
if x==None:
return y
if y==None:
return x
while j<len(x) and h<len(y):
if x[j]<y[h]:
c.append(x[j])
j+=1
else:
c.append(y[h])
h+=1
if j==len(x):
for i in y[h:]:
c.append(i)
else:
for i in x[j:]:
c.append(i )
return c














 2578
2578











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









