









文章目录
1、环境与版本说明
~~~~~~~
● ubuntu 18.04
~~~~~~~
● CUDA 10.0
~~~~~~~
● cudnn 7.6.5
~~~~~~~
● gcc 7.3
~~~~~~~
● python 3.6
~~~~~~~
● tensorflow 1.14
~~~~~~~
● tensort 6.0.1
2、环境安装
2.1、CUDA 安装
驱动drivers
ubuntu-drivers devices # 查看设备支持的驱动

我本机支持410,,因此先安装驱动
# 1、更新apt-get源列表
sudo apt-get update
sudo apt-get upgrade
# 2. 添加驱动源
sudo add-apt-repository ppa:graphics-drivers/ppa
sudo apt-get update
sudo apt-get install nvidia-410 # 安装
sudo nvidia-smi # 查看驱动的安装状态
并根据下图进行选择cuda版本的匹配,选择10.0版本的 CUDA,点击这查看CUDA官网对应驱动
,如下图部分数据:

切换gcc
选择10.0版本的 CUDA,点击这查看CUDA官网对应GCC版本
,如下图部分数据:

博主采用的是gcc本来就是7.3的,因此不需要进行装换,如要装换,采用以下命令进行切换
# 安装gcc5
sudo apt-get install gcc-5 gcc-5-multilib
sudo apt-get install g++-5 g++-5-multilib
# 设置优先级
sudo update-alternatives --install /usr/bin/gcc gcc /usr/bin/gcc-5 50
sudo update-alternatives --install /usr/bin/g++ gc++/usr/bin/g++-5 50
# 看gcc可选版本与当前版本
sudo update-alternatives --config gcc
# 查看gcc版本
gcc -version
安装cuda
官网,点击这里

下载结束后,运行sudo sh *.run进行安装
一直按Enter直至把声明看完
如果驱动是独立安装了,一定要选择不安装驱动!选择如下:
期间会有一些警告,忽略即可,安装后需要进行以下的配置
# 添加环境变量
sudo gedit ~/.bashrc
# 添加到最后
export PATH=$PATH:/usr/local/cuda/bin
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/cuda/lib64
export LIBRARY_PATH=$LIBRARY_PATH:/usr/local/cuda/lib64
# 保存退出
source ~/.bashrc
#测试是否成功
sudo rm -rf /usr/local/cuda
sudo ln -s /usr/local/cuda-10.0 /usr/local/cuda
nvcc --version
cd /usr/local/cuda/samples/1_Utilities/deviceQuery
sudo make
./deviceQuery
# 重启
reboot
#输入
nvidia-smi # 查看最新安装状态

安装cudnn
官网,点击这里,进行版本选择和下载

删除旧版本,若无则跳过
sudo rm -rf /usr/local/cuda/include/cudnn.h
sudo rm -rf /usr/local/cuda/lib64/libcudnn*
安装新版本,cd进入刚才解压的cuda文件夹
sudo cp include/cudnn.h /usr/local/cuda/include/
sudo cp lib64/lib* /usr/local/cuda/lib64/
建立软链接
cd /usr/local/cuda/lib64/
sudo chmod +r libcudnn.so.7.6.5
sudo ln -sf libcudnn.so.7.6.5 libcudnn.so.7
sudo ln -sf libcudnn.so.7 libcudnn.so
sudo ldconfig
测试验证
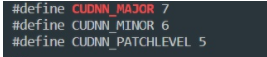
cat /usr/local/cuda/include/cudnn.h | grep CUDNN_MAJOR -A 2
若出现下图版本显示,则安装成功
2.2、安装TensorRT
下载地址,点击官网,这里

选择6.0的tar版本进行下载,并解压得到以下工作
# 在home下新建文件夹,命名为tensorrt,然后将下载的压缩文件拷贝进来解压
tar xzvf TensorRT-6.0.1.5.Ubuntu-18.04.x86_64-gnu.cuda-10.0.cudnn7.6.tar.gz
# 解压得到TensorRT-6.0.1.5的文件夹,将里边的lib绝对路径添加到环境变量中
gedit ~/.bashrc
# 添加
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/home/jason/tensorrt/TensorRT-6.0.1.5/lib
# 生效
source ~/.bashrc
#安装TensorRT
cd TensorRT-6.0.1.5/python/
pip install tensorrt-6.0.1.5-cp36-none-linux_x86_64.whl
#安装UFF,这个与tensorflow相关,可以不装
cd TensorRT-6.0.1.5/uff
pip install uff-0.6.5-py2.py3-none-any.whl
#安装graphsurgeon
cd TensorRT-6.0.1.5/graphsurgeon
pip install graphsurgeon-0.4.1-py2.py3-none-any.whl
# 进入python环境,测试,不报错误则安装成功
import tensorrt
2.3、安装TF与其他环境
sudo pip3 install tensorflow-gpu==1.14.0
sudo pip3 install numpy==1.19.5
sudo pip3 install h5py==3.1.0
sudo pip3 install onnx==1.4.1
sudo pip3 install Pillow==6.1.0
sudo pip3 install pycuda==2019.1.1
sudo pip3 install uff==0.6.5
sudo pip3 install wget==3.2
3、模型训练(以InceptionV3为例)–>略
略,参考
4、使用tensorRT推理加速
4.1、模型保存
在TensorFlow中模型的保存和调用,相信大家都不会陌生,使用关键语句saver = tf.train.Saver()和saver.save()就可以完成。
但是,不知道大家是否了解,tensorflow通过checkpoint这一种格式文件,是将模型的结构和权重数据分开保存的,这就造成了一些使用场景下的不方便。
所以,我们需要一种方式将模型结构和权重数据合并在一个文件中,tensorflow提供了freeze_graph函数和pb文件格式,来解决这一问题。
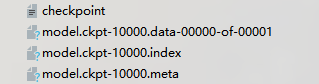
在save之后,模型会保存在ckpt文件中,checkpoint文件保存了一个目录下所有的模型文件列表,events文件是给可视化工具tensorboard用的。
和保存的模型直接相关的是以下这三个文件:
.data文件保存了当前参数值
.index文件保存了当前参数名
.meta文件保存了当前图结构
当你使用saver.restore()载入模型时,你用的就是这一组的三个checkpoint文件。但是,当我们需要将模型和权重整合成一个文件时,我们就需要以下的操作了。
4.2、生成PB文件
ensorflow提供了freeze_graph这个函数来生成pb文件。以下的代码块可以完成将checkpoint文件转换成pb文件的操作:
载入你的模型结构,
提供checkpoint文件地址
使用tf.train.writegraph保存图,这个图会提供给freeze_graph使用
使用freeze_graph生成pb文件

具体实现代码如下
# -*-coding: utf-8 -*-
import tensorflow as tf
import numpy as np
import cv2
from tensorflow.python.framework import graph_util
resize_height = 224
resize_width = 224
depths = 3
def read_image(filename, resize_height, resize_width, normalization=False):
bgr_image = cv2.imread(filename)
if len(bgr_image.shape) == 2:
print("Warning:gray image", filename)
bgr_image = cv2.cvtColor(bgr_image, cv2.COLOR_GRAY2BGR)
rgb_image = cv2.cvtColor(bgr_image, cv2.COLOR_BGR2RGB)
if resize_height > 0 and resize_width > 0:
rgb_image = cv2.resize(rgb_image, (resize_width, resize_height))
rgb_image = np.asanyarray(rgb_image)
if normalization:
rgb_image = rgb_image / 255.0
return rgb_image
def freeze_graph_test(pb_path, image_path):
with tf.Graph().as_default():
output_graph_def = tf.GraphDef()
with open(pb_path, "rb") as f:
output_graph_def.ParseFromString(f.read())
tf.import_graph_def(output_graph_def, name="")
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
input_image_tensor = sess.graph.get_tensor_by_name("input:0")
input_keep_prob_tensor = sess.graph.get_tensor_by_name("keep_prob:0")
input_is_training_tensor = sess.graph.get_tensor_by_name("is_training:0")
output_tensor_name = sess.graph.get_tensor_by_name("InceptionV3/Logits/SpatialSqueeze:0")
im = read_image(image_path, resize_height, resize_width, normalization=True)
im = im[np.newaxis, :]
out = sess.run(output_tensor_name, feed_dict={input_image_tensor: im,
input_keep_prob_tensor: 1.0,
input_is_training_tensor: False})
print("out:{}".format(out))
score = tf.nn.softmax(out, name='pre')
class_id = tf.argmax(score, 1)
print("pre class_id:{}".format(sess.run(class_id)))
def freeze_graph(input_checkpoint, output_graph):
output_node_names = "InceptionV3/Logits/SpatialSqueeze"
saver = tf.train.import_meta_graph(input_checkpoint + '.meta', clear_devices=True)
with tf.Session() as sess:
saver.restore(sess, input_checkpoint)
output_graph_def = graph_util.convert_variables_to_constants(
sess=sess,
input_graph_def=sess.graph_def,
output_node_names=output_node_names.split(","))
with tf.gfile.GFile(output_graph, "wb") as f:
f.write(output_graph_def.SerializeToString())
print("%d ops in the final graph." % len(output_graph_def.node))
if __name__ == '__main__':
# 转换
input_checkpoint = './input_model/model.ckpt-10000'
out_pb_path = "./output_model/frozen_model.pb"
freeze_graph(input_checkpoint, out_pb_path)
# 测试
image_path = './test_img/guitar.jpg'
freeze_graph_test(pb_path=out_pb_path, image_path=image_path)
4.3、pb转换成uff
准备工作
import tensorflow as tf
import uff
import tensorrt as trt
import pycuda.driver as cuda
import pycuda.autoinit
from tensorrt.parsers import uffparser
● uff:是将刚才的pb转化为TensorRT引擎支持的uff文件,该文件可以序列化,也可以直接当作流传过去。
● pycyda:用于显卡cuda编程的,如果要使用TensorRT的python API,这是一个必须的库
● uffparser :用于解析uff模型
参数设置
# 数据自定义
MODEL_DIR = './output_model/frozen_model.pb'
CHANNEL = 3
HEIGHT = 224
WIDTH = 224
ENGINE_PATH = './model_seg/model_.pb.plan'
INPUT_NODE = 'input'
OUTPUT_NODE = ['InceptionV3/Logits/SpatialSqueeze']
INPUT_SIZE = [CHANNEL, HEIGHT ,WIDTH]
MAX_BATCH_SIZE = 1
MAX_WORKSPACE = 1<<30
● MODEL_DIR:第一步中生成的pb模型地址
● CHANNEL、HEIGHT、WIDTH:图片的通道、高和宽,根据模型的输入大小确定
● ENGINE_PATH:等会保存TensorRT引擎的地址
● INPUT_NODE:模型的输入节点
● OUTPUT_NODE:模型的输出节点,是一个列表,如果有许多个输出节点,就将节点名都列入这个列表中
● INPUT_SIZE:输入图片的大小,注意通道在前还是后,这里输入的是 CHANNEL, HEIGHT ,WIDTH
● MAX_BATCH_SIZE:在推理的时候,每次输入几张图片
● MAX_WORKSPACE:显存的大小1<<30也就是1GB的大小。有的时候,程序运行是会报内存溢出的错,这个时候就可以调小MAX_WORKSPACE,比如2 << 10
pb转uff 并解析模型
G_LOGGER = trt.infer.ConsoleLogger(trt.infer.LogSeverity.INFO)
uff_model = uff.from_tensorflow_frozen_model(FROZEN_GDEF_PATH, OUTPUT_NODE)
parser = uffparser.create_uff_parser()
parser.register_input(INPUT_NODE, INPUT_SIZE, 0)
parser.register_output(OUTPUT_NODE)
这里做的事情是将pb的文件格式转成了uff文件格式。你需要知道的一个概念是,UFF(Universal Framework Format)是一种描述DNN执行图的数据格式。绑定执行图的是输入与输出,所以parser.register_input和parser.register_output做的事情是将tensorflow模型的输入输出在UFF文件中记录。
注意,对于多个输出,因为OUTPUT_NODE是一个列表,所以将多个输出节点依次放入列表就可以了。
如果是多个输入的话,则需要将输入节点名一个个的记录在uff中。register_input()需要3个参数:
name – Input name.
shape – Input shape.
order – Input order on which the framework input was originally.
假设你的模型在输入层同时输入了三张图片,那么你需要定义3个输入节点,并且指定order分别为0、1、2。这里的order指的是模型的输入在uff结构中的顺序,这种order在接下来的binding会得到体现。
● parser.register_input(INPUT_NODE1, INPUT_SIZE, 0)
● parser.register_input(INPUT_NODE2, INPUT_SIZE, 1)
● parser.register_input(INPUT_NODE3, INPUT_SIZE, 2)
保存模型
engine = trt.utils.uff_to_trt_engine(
G_LOGGER,
uff_model,
parser,
MAX_BATCH_SIZE,
MAX_WORKSPACE,
datatype=trt.infer.DataType.FLOAT)
# 以上代码创建了TensorRT中的engine,即引擎,这个engine将负责模型的前向运算。TensorRT是一个用于推理的加速工具,所以前向计算就够了。
# 在engine创建成功之后,就可以使用了。不过,一个建议是将结果保存下来。毕竟到目前为止,虽然代码很少,但是将pb文件成功转换成uff文件是不容易的(谁用谁知道!)
# 使用以下语句,我们就保存了一个.plan文件。PLAN文件是运行引擎用于执行网络的序列化数据。包含权重,网络中执行步骤以及用来决定如何绑定输入与输出缓存的网络信息。
trt.utils.cwrite_engine_to_file('./model_.pb.plan',engine.serialize())
4.4、推理步骤
现在,让我们调用之前保存的plan文件,启用引擎,开始使用TensorRT实现推理。
engine = trt.utils.load_engine(G_LOGGER, './model_.pb.plan')
引擎叫做engine,而引擎运行的上下文叫做context。engine和context在推理过程中都是必须的,这两者的关系如下:
context = engine.create_execution_context()
engine = context.get_engine()
在运行前向运算前,我们还需要做一次确认。get_nb_bindings()是为了获取与这个engine相关的输入输出tensor的数量。对于本例中单输入输出的模型,tensor的数量是2。如果有多个输入输出,这个确认值就要相应的变化,比如3个输入,1个输出的模型,tensor的数量就是4。我们需要知道这个数量,是为了之后的显存分配做准备。
print(engine.get_nb_bindings())
assert(engine.get_nb_bindings() == 2)
现在准备好一张可以输入给模型的图像 img.jpg,并且转换成fp32
img = cv2.imread(img.jpg)
img = img.astype(np.float32)
同时,创建一个array来“接住”输出数据。为什么说“接住”呢,因为之后你就会看到,引擎做前向推理计算的时候,是生成了一个数据流,这个数据流会写入output array中
#create output array to receive data
OUTPUT_SIZE = 10
output = np.zeros(OUTPUT_SIZE , dtype = np.float32)
我们需要为输入输出分配显存,并且绑定。
# 使用PyCUDA申请GPU显存并在引擎中注册
# 申请的大小是整个batchsize大小的输入以及期望的输出指针大小。
d_input = cuda.mem_alloc(1 * img.size * img.dtype.itemsize)
d_output = cuda.mem_alloc(1 * output.size * output.dtype.itemsize)
# 引擎需要绑定GPU显存的指针。PyCUDA通过分配成ints实现内存申请。
bindings = [int(d_input), int(d_output)]
现在,我们可以开始TensorRT上的推理计算了!
# 建立数据流
stream = cuda.Stream()
# 将输入传给cuda
cuda.memcpy_htod_async(d_input, img, stream)
# 执行前向推理计算
context.enqueue(1, bindings, stream.handle, None)
# 将预测结果传回
cuda.memcpy_dtoh_async(output, d_output, stream)
# 同步
stream.synchronize()
这个时候,如果你将output打印出来,就会发现output数组中已经有值了,这就是TensorRT计算的结果。
如过你使用tensorflow的方法,对同一组输入数据做预测,看看计算的结果是否一致 ,因为精度的差异会有一些差异,但是大体上来说,使用tensorflow和TensorRT,会得到一致的结果。
4.5、完整代码
上诉流程是假的参数,下面该部分为真实有效路径
import uff
import tensorrt as trt
import pycuda.driver as cuda
import pycuda.autoinit
from tensorrt.parsers import uffparser
import cv2
MODEL_DIR = '/home/liyang/ly/inception2trt/tf_pb/output_model/frozen_model.pb'
CHANNEL = 3
HEIGHT = 224
WIDTH = 224
ENGINE_PATH = './model_.pb.plan'
INPUT_NODE = 'input'
output_node = 'InceptionV3/Logits/SpatialSqueeze'
INPUT_SIZE = [CHANNEL, HEIGHT, WIDTH]
MAX_BATCH_SIZE = 1
MAX_WORKSPACE = 1<<30
# PB-UFF
G_LOGGER = trt.infer.ConsoleLogger(trt.infer.LogSeverity.INFO)
uff_model = uff.from_tensorflow_frozen_model(FROZEN_GDEF_PATH, [OUTPUT_NODE])
parser = uffparser.create_uff_parser()
parser.register_input(INPUT_NODE, INPUT_SIZE, 0)
parser.register_output(OUTPUT_NODE)
# SERIVER
engine = trt.utils.uff_to_trt_engine(G_LOGGER,uff_model,
parser,MAX_BATCH_SIZE,
MAX_WORKSPACE,datatype=trt.infer.DataType.FLOAT)
# save
trt.utils.cwrite_engine_to_file('./checkpoint/model_.pb.plan',engine.serialize())
# start tensorR
engine = trt.utils.load_engine(G_LOGGER, './model_.pb.plan')
context = engine.create_execution_context()
input_img = cv2.imread('./1.jpg')
def infer32(batch_size):
# commissioning
engine = context.get_engine()
assert(engine.get_nb_bindings() == 2)
start = time.time()
dims = engine.get_binding_dimensions(1).to_DimsCHW()
elt_count = dims.C() * dims.H() * dims.W() * batch_size
input_img = input_img.astype(np.float32)
output = cuda.pagelocked_empty(elt_count, dtype=np.float32)
d_input = cuda.mem_alloc(batch_size * input_img.size * input_img.dtype.itemsize)
d_output = cuda.mem_alloc(batch_size * output.size * output.dtype.itemsize)
bindings = [int(d_input), int(d_output)]
stream = cuda.Stream()
cuda.memcpy_htod_async(d_input, input_img, stream)
context.enqueue(batch_size, bindings, stream.handle, None)
cuda.memcpy_dtoh_async(output, d_output, stream)
end = time.time()
return output
infer32(1)
参考:https://blog.csdn.net/qq_34067821/article/details/90710192
~~~~~~~~~~
https://zhuanlan.zhihu.com/p/139767249
~~~~~~~~~~
https://zhuanlan.zhihu.com/p/64099452
~~~~~~~~~~
https://zhuanlan.zhihu.com/p/64114667
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









