







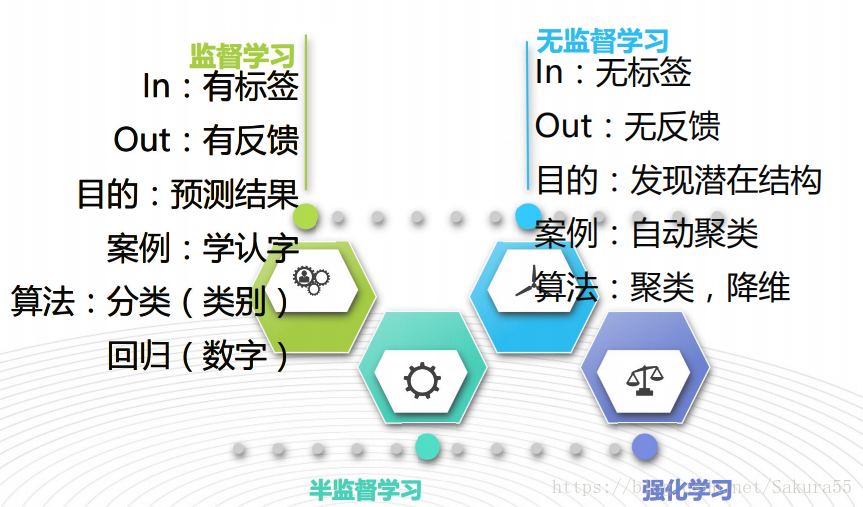
一、什么是K近邻
K最近邻(k-Nearest Neighbour,KNN)分类算法,是一个理论上比较成熟的方法,也是最简单的机器学习算法之一。该方法的思路是:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。
用官方的话来说,所谓K近邻算法,即是给定一个训练数据集,对新的输入实例,在训练数据集中找到与该实例最邻近的K个实例(也就是上面所说的K个邻居), 这K个实例的多数属于某个类,就把该输入实例分类到这个类中。
● 她是一种懒惰的学习方法,只有新的数据来的时候,才会给出分类判断
● KNN没有训练模型的过程,训练和预测是结合在一起的
首先看一下算法的分类

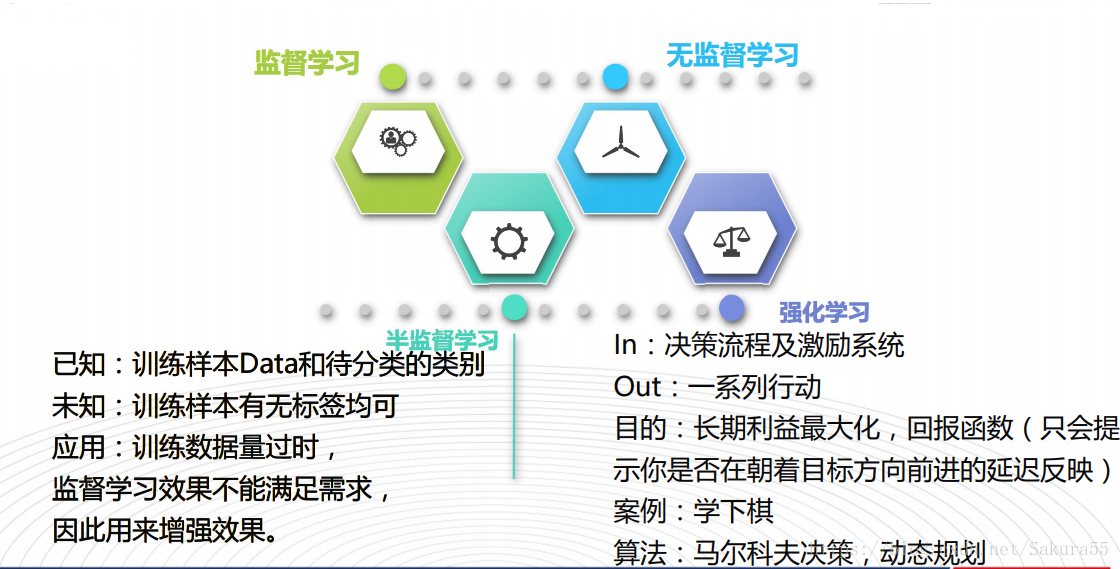
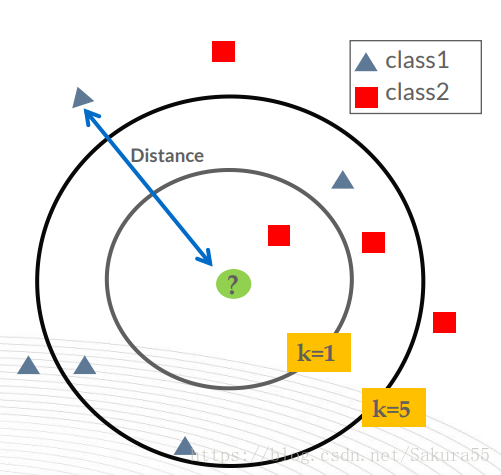
该算法的思想是:一个样本与数据集中的k个样本最相似,如果这k个样本中的
大多数属于某一个类别,则该样本也属于这个类别。
二、基本流程
1)计算已知类别数据集中的点与当前点之间的距离
2)按距离递增次序排序
3)选取与当前点距离最小的k个点
4)统计前k个点所在的类别出现的频率
5)返回前k个点出现频率最高的类别作为当前点的预测分类

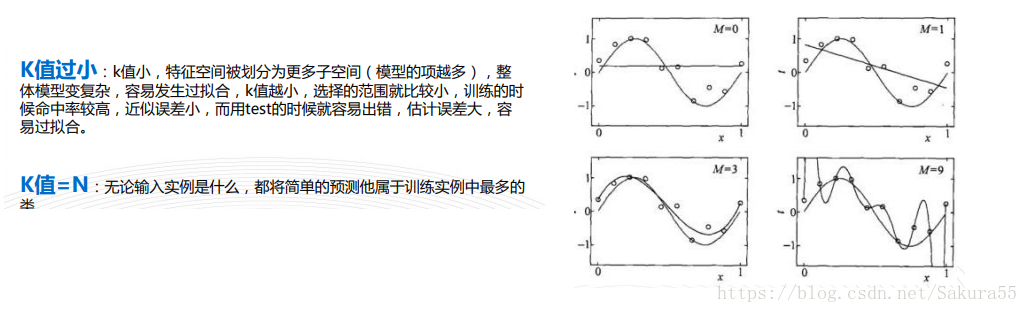
三、近似误差和估计误差

四、K值确定
五、Kd树
给定一个二维空间数据集:T={(2,3),(5,4),(9,6),(4,7),(8,1),(7,2)},构造一个平衡kd树。
代码如下:
#from operator import itemgetter
import sys
import importlib
importlib.reload(sys)
# sys.setdefaultencoding('utf8')
# kd-tree每个结点中主要包含的数据结构如下
class KdNode(object):
def __init__(self, dom_elt, split, left, right):
self.dom_elt = dom_elt # k维向量节点(k维空间中的一个样本点)
self.split = split # 整数(进行分割维度的序号)
self.left = left # 该结点分割超平面左子空间构成的kd-tree
self.right = right # 该结点分割超平面右子空间构成的kd-tree
class KdTree(object):
def __init__(self, data):
k = len(data[0]) # 数据维度
def CreateNode(split, data_set): # 按第split维划分数据集exset创建KdNode
if not data_set: # 数据集为空
return None
# key参数的值为一个函数,此函数只有一个参数且返回一个值用来进行比较
# operator模块提供的itemgetter函数用于获取对象的哪些维的数据
#参数为需要获取的数据在对象中的序号
#data_set.sort(key=itemgetter(split)) # 按要进行分割的那一维数据排序
data_set.sort(key=lambda x: x[split])
split_pos = len(data_set) // 2 # //为Python中的整数除法
median = data_set[split_pos] # 中位数分割点
split_next = (split + 1) % k # cycle coordinates
# 递归的创建kd树
return KdNode(median, split, # 创建左子树
CreateNode(split_next, data_set[split_pos + 1:]))
# 创建右子树
self.root = CreateNode(0, data)
# 从第0维分量开始构建kd树,返回根节点
# KDTree的前序遍历
def preorder(root):
print (root.dom_elt)
if root.left: # 节点不为空
preorder(root.left)
if root.right:
preorder(root.right)
if __name__ == "__main__":
data = [[2,3],[5,4],[9,6],[4,7],[8,1],[7,2]]
kd = KdTree(data)
preorder(kd.root)六、算法实践
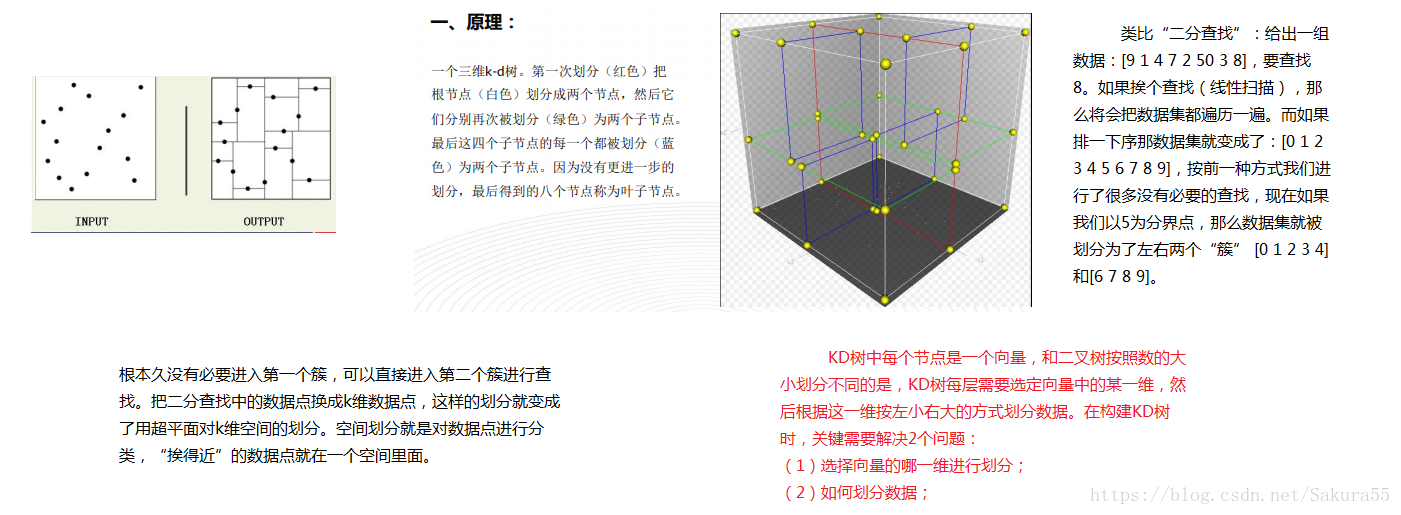
用KNN进行回归。
预测的点的值通过求与它距离最近的K个点的值的平均值得到,“距离最近”可以
是欧氏距离,也可以是其他距离,具体的效果依数据而定。
import numpy as np
import matplotlib.pyplot as plt
from sklearn import neighbors
np.random.seed(0)
X = np.sort(5 * np.random.rand(40, 1), axis=0)
T = np.linspace(0, 5, 500)[:, np.newaxis]
y = np.sin(X).ravel()
# 添加噪音
y[::5] += 1 * (0.5 - np.random.rand(8))
# 适用回归模型
n_neighbors = 5
for i, weights in enumerate(['uniform','distance']):
knn = neighbors.KNeighborsRegressor(n_neighbors, weights=weights)
y_ = knn.fit(X, y).predict(T)
plt.subplot(2, 1, i + 1)
plt.scatter(X, y, c='k', label='data')
plt.plot(T, y_, c='g', label='prediction')
plt.axis('tight')
plt.legend()
plt.title("KNeighborsRegressor(k=%i,weights='%s')"%(n_neighbors,weights))
plt.show()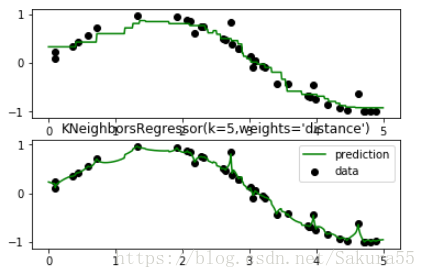
KNN分类问题案例
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.colors import ListedColormap
from sklearn import neighbors, datasets
n_neighbors = 15
# 导入一些数据
iris = datasets.load_iris()
#切片
X = iris.data[:, :2]
y = iris.target
h = .02 # 步长
# 创建彩色区域
cmap_light = ListedColormap(['#FFAAAA', '#AAFFAA', '#AAAAFF'])
cmap_bold = ListedColormap(['#FF0000', '#00FF00', '#0000FF'])
for weights in ['uniform', 'distance']:
# 我们创建一个分类的实例并适合数据。
clf = neighbors.KNeighborsClassifier(n_neighbors, weights=weights)
clf.fit(X, y)
# 绘制决策边界.分配颜色
# 在网格中指向[x_min,x_max] x [y_min,y_max]。
x_min, x_max = X[:, 0].min() - 1, y[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, y[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, h),
np.arange(y_min, y_max, h))
Z = clf.predict(np.c_[xx.ravel(), yy.ravel()])
# 将结果放入颜色图中
Z = Z.reshape(xx.shape)
plt.figure()
plt.pcolormesh(xx, yy, Z, cmap=cmap_light)
# 绘制了训练点
plt.scatter(X[:, 0], X[:, 1], c=y, cmap=cmap_bold,
edgecolor='k', s=20)
plt.xlim(xx.min(), xx.max())
plt.ylim(yy.min(), yy.max())
plt.title("3-Class classification (k = %i, weights = '%s')"
% (n_neighbors, weights))
plt.show()
七、代码演示
#coding=utf-8
from sklearn import cross_validation,neighbors,datasets
import matplotlib.pyplot as plt
def chooseK():
digits = datasets.load_digits() #导入手写体数据集
X_train,X_test,Y_train,Y_test = cross_validation.train_test_split(digits.data,digits.target, random_state=33,test_size=0.25)
#对数据进行随机划分,其中测试集的比例为25%
ks = range(1,100) #k的取值范围,1到训练数据集的大小
trainScore = [] #存储训练集的得分
testScore = [] #存储测试集的得分,得分越高越好
for k in ks:
clf = neighbors.KNeighborsClassifier(n_neighbors=k)#调用KNN分类,把KNN中的k设为K
clf.fit(X_train,Y_train)#训练KNN
trainScore.append(clf.score(X_train,Y_train))#不同k值的分类器在训练数据集的得分
testScore.append(clf.score(X_test,Y_test))#不同k值的分类器在测试数据集的得分
fig = plt.figure()#下面主要是画图,把k值与训练数据与测试数据的得分的关系表示出来
ax = fig.add_subplot(111)
ax.plot(ks,trainScore,label='train score')
ax.plot(ks,testScore,label='test score')
ax.set_xlabel('ks')
ax.set_ylabel('score')
ax.set_ylim(0,1)
ax.legend()
plt.show()
>>>chooseK()#运行程序七、参数优化
交叉验证的方法寻找K值
经验值k=sqrt(n)/2,n 是训练样本数
距离的选择
K近邻的投票加权方法
平均权重:每一个邻居的的权重是一样的
距离权重:按照距离倒数(1/d)加权,距离越近的邻居重要性越大














 3030
3030











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









