






关于Spring框架
● Spring框架主要解决了创建对象、管理对象的问题。
● 在开发实践中,Spring框架的核心价值在于:开发者可以通过Spring框架提供的机制,将创建对象、管理对象的任务交给Spring来完成,以至于开发者不必再关心这些过程,当需要某个对象时,只需要通过Spring获取 对象即可。 – Spring框架也经常被称之为:Spring容器
● Spring框架还很好的支持了AOP,此部分将在后续课程中再介绍。
● 在开发实践中,有许多类型的对象、配置值都需要常驻内存、需要有唯一 性,或都需要多处使用,自行维护这些对象或值是非常繁琐的,通过 Spring框架可以极大的简化这些操作
在Maven工程中使用Spring
● 当某个项目需要使用Spring框架时,推荐使用Maven工程。
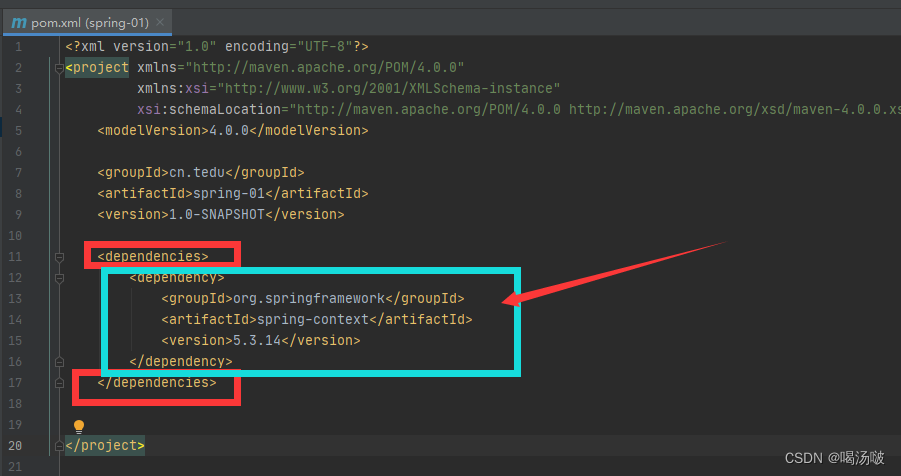
● 使用Spring框架所需的依赖项是 spring-context,依赖代码为:
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-context</artifactId>
<version>5.3.14</version>
</dependency>
– 以上代码中版本号可按需调整
查询依赖步骤:
可以从 https://www.mvnrepository.com 上找到正确的依赖项代码
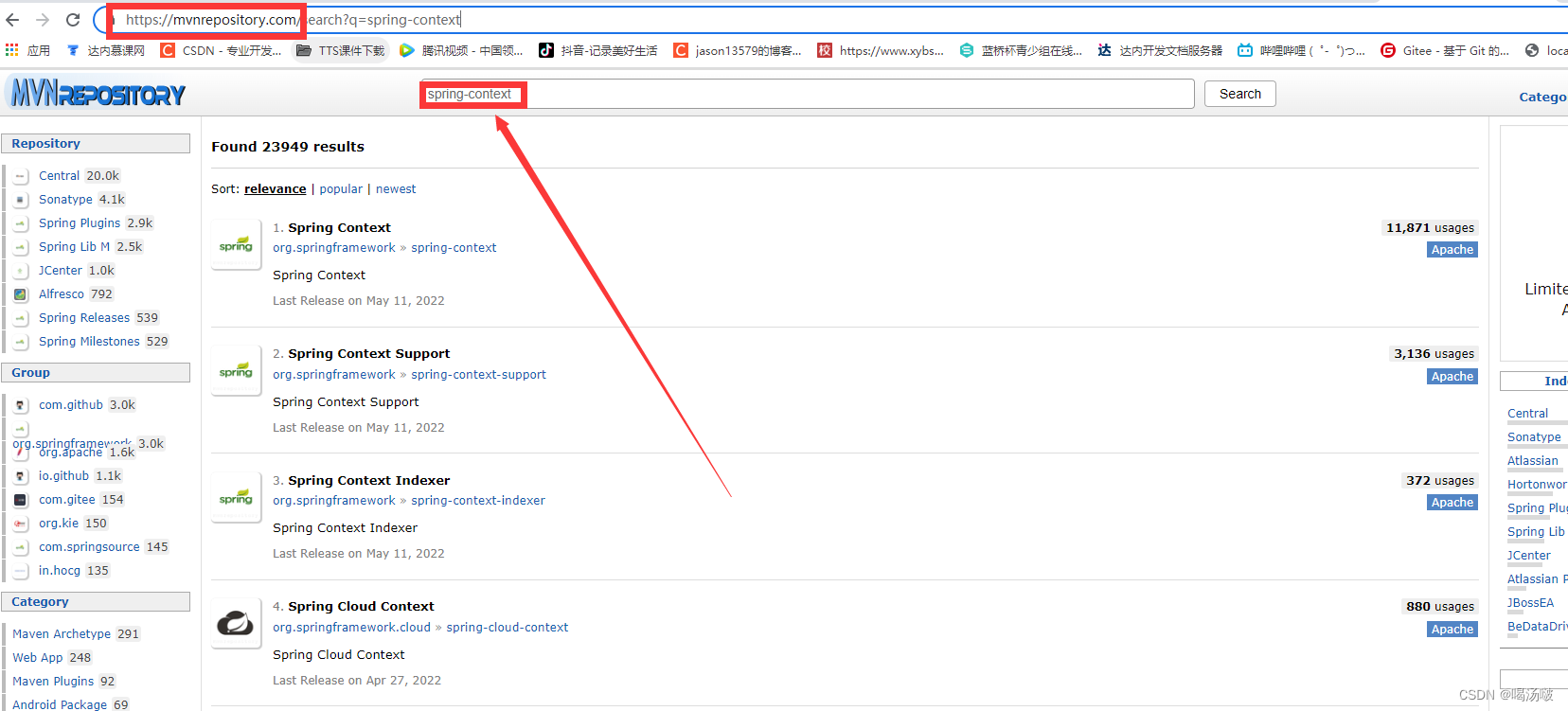
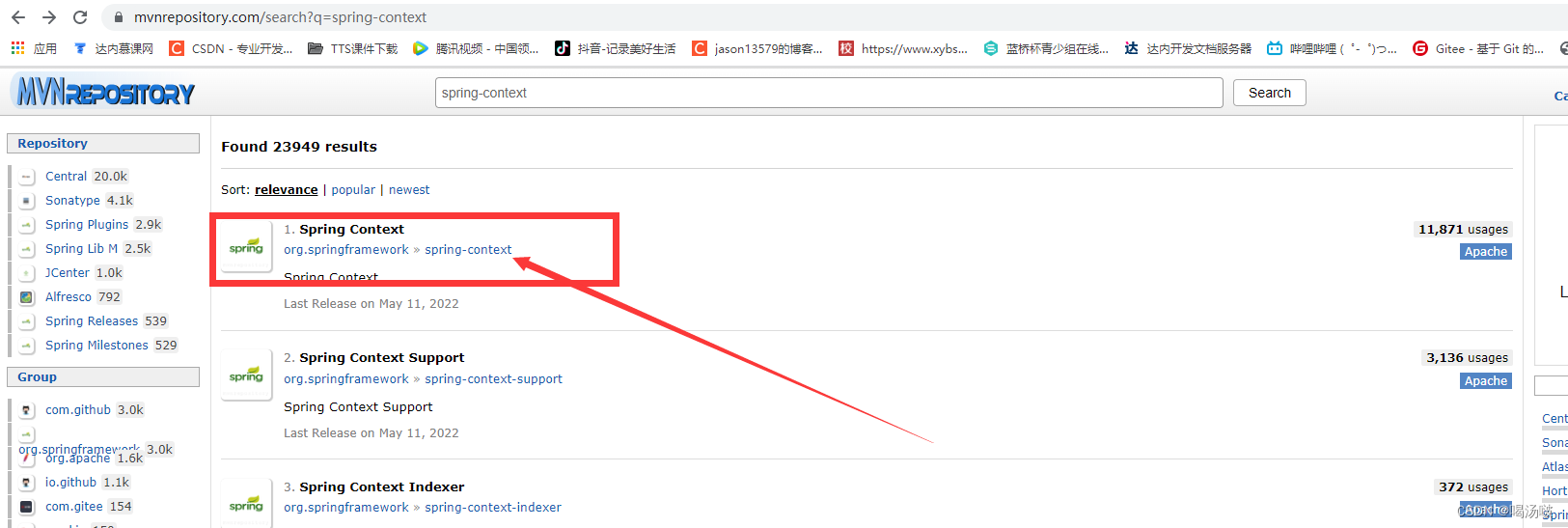
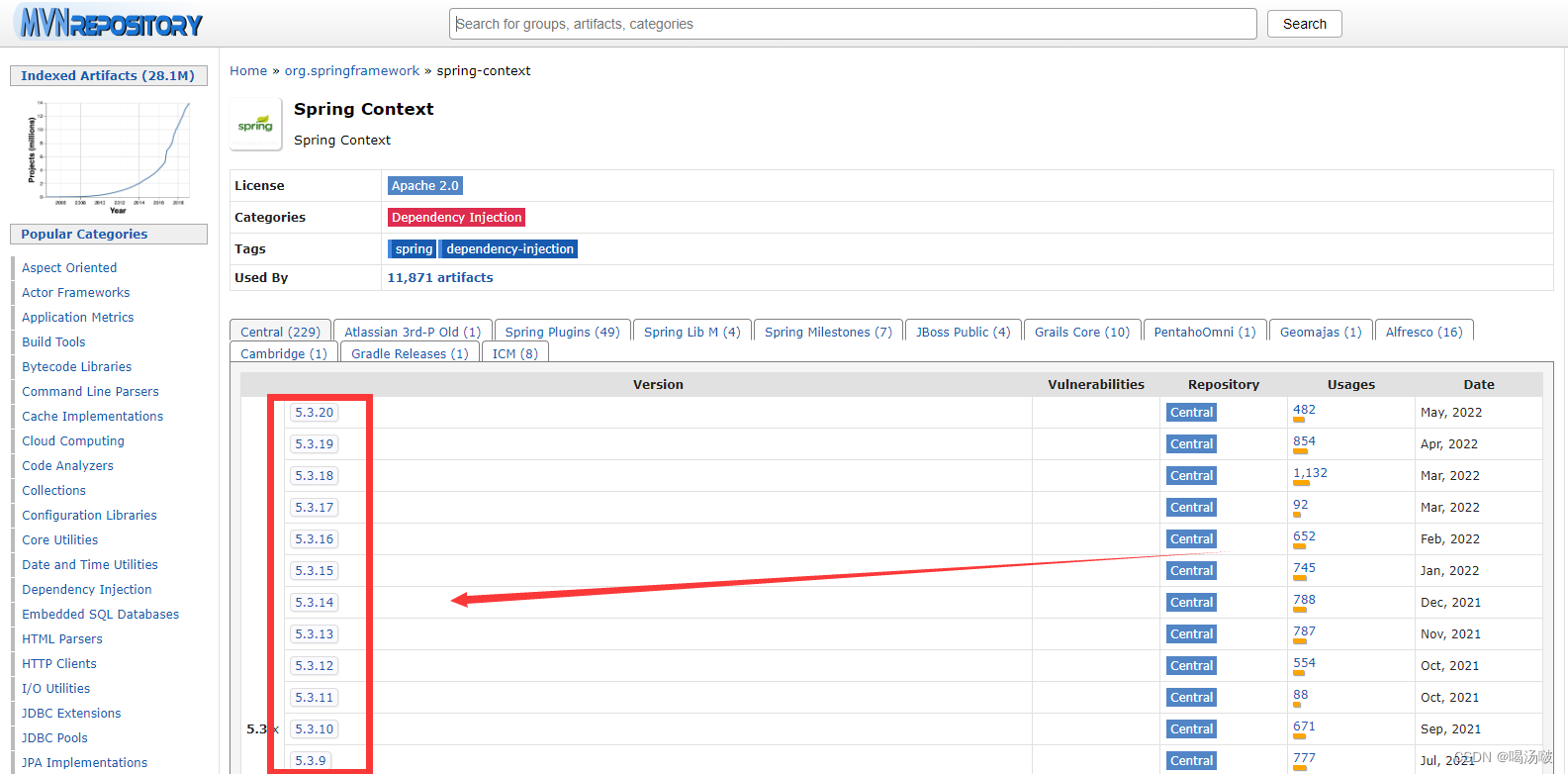
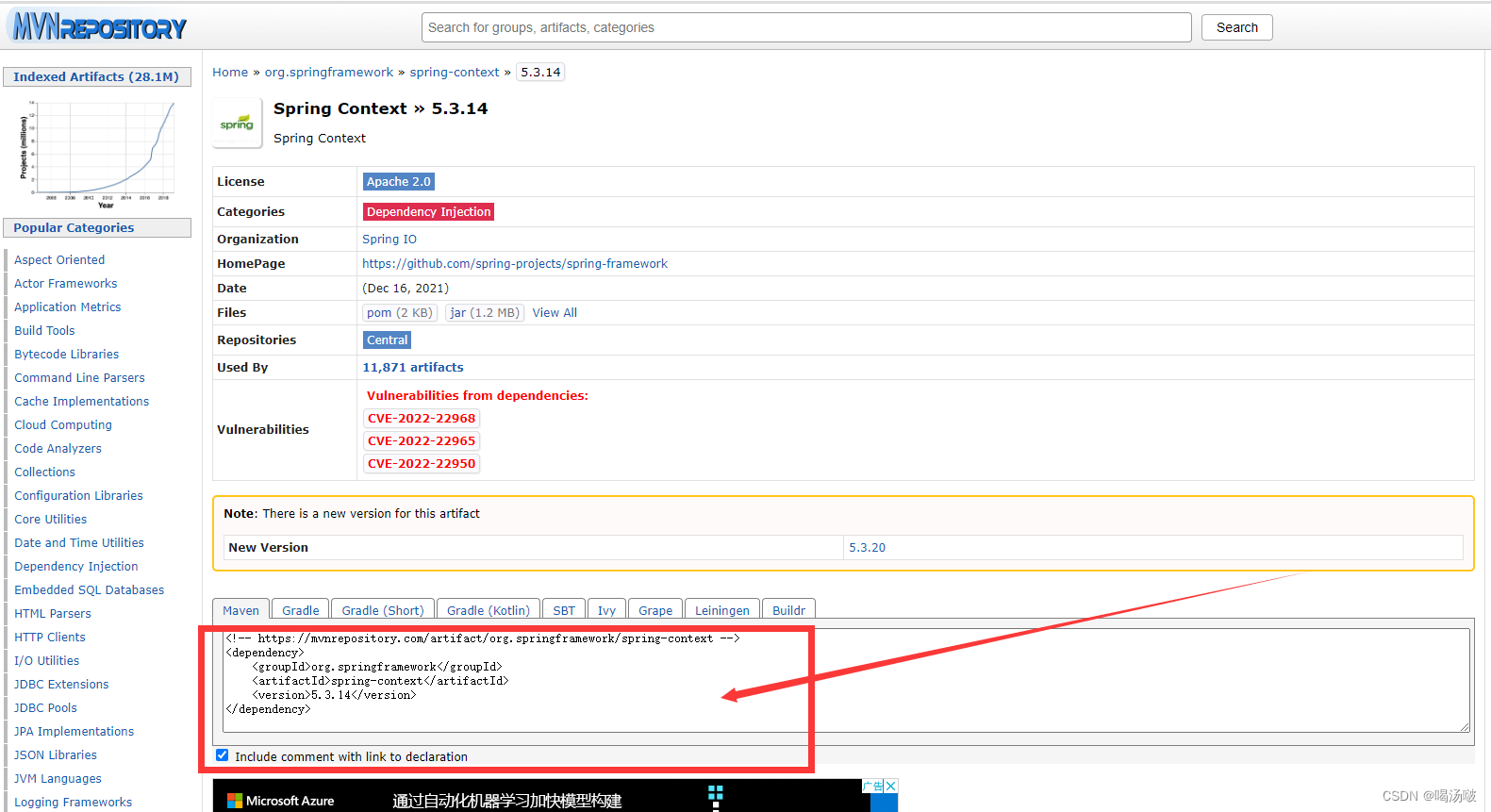
创建Maven工程,在pom.xml配置文件中添加依赖,然后刷新:
Spring Bean的作用域
● 在默认情况下,由Spring Bean的作用域是单例的
● 单例的表现为:实例唯一,即在任意时刻每个类的对象最多只有1个,并且,当对象创建出来之后,将常驻内存,直至Spring将其销毁(通常是 ApplicationContext调用了销毁方法,或程序运行结束)
● 注意:这与设计模式中的单例模式无关,只是作用域的表现完全相同
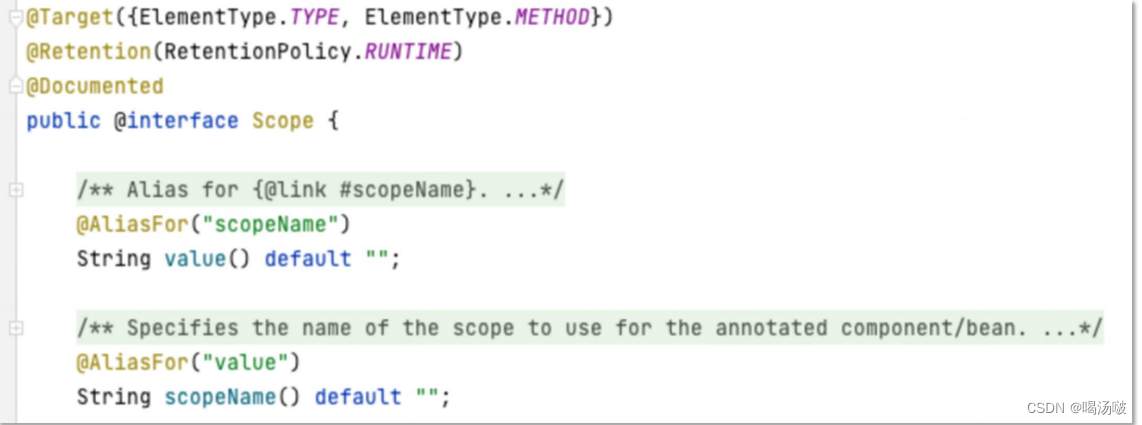
● 可以通过@Scope注解修改作用域
– 当通过@Bean方法创建对象时,在方法的声明之前添加@Scope注解
– 当通过组件扫描创建对象时,在组件类的声明之前添加@Scope注解

● @Scope注解的scopeName属性决定了作用域,此属性与value是互相等 效的,所以,通常配置为value属性即可
● @Scope注解的scopeName属性的常见取值有:
– singleton:单例的
– 事实上这是默认值,在scopeName属性的源码上明确的说明了:Defaults to an empty string “” which implies ConfigurableBeanFactory.SCOPE_SINGLETON,且以上常量的值就是singleton
– prototype:原型,是非单例的
– 还有其它取值,都是不常用取值,暂不关心
● 当需要将Spring Bean的作用域改为“非单例的”,可以:

● 你可以反复通过getBean()获取对象,会发现各对象的hashCode()返回的结果都不相同
– 如果hashCode()没有被恶意重写,不同对象的hashCode()必然不同
● 由于不配置@Scope,与配置为@Scope(“singleton”)是等效的,所以, 仅当需要将Spring Bean的作用域改为“非单例的”,才会添加配置为 @Scope(“prototype”)
● 在默认情况下,单例的Spring Bean是预加载的,必要的话,也可以将其配置为懒加载的
– 如果某个对象本身不是单例的,则不在此讨论范围之内
● 预加载的表现为:加载Spring环境时就会创建对象,即加载Spring配置的环节,会创建对象
● 懒加载的表现为:加载Spring环境时并不会创建对象,而是在第1次获取对象的那一刻再创建对象
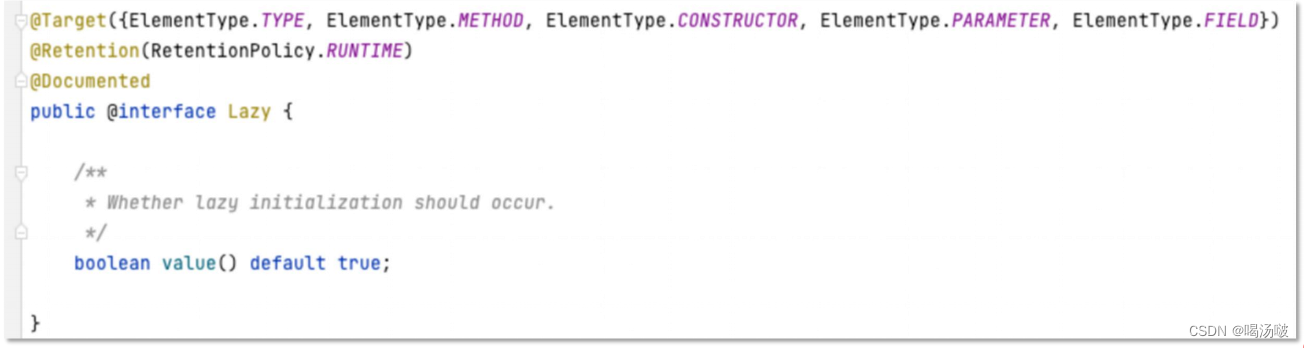
● 可以通过@Lazy注解来配置懒加载
– 当通过@Bean方法创建对象时,在方法的声明之前添加@Lazy注解
– 当通过组件扫描创建对象时,在组件类的声明之前添加@Lazy注解

● @Lazy注解的value属性是boolean类型的,表示“是否懒加载”
● @Lazy注解的参数是不需要关心的,因为:
– 单例的Spring Bean默认就是预加载的,不是懒加载的,所以,保持默认状态时,不使用@Lazy注解即可,并不需要配置为@Lazy(false) – @Lazy注解的value属性默认为true,所以,当需要将单例的Spring Bean配置为懒 加载时,只需要添加@Lazy注解即可,并不需要配置为@Lazy(true)
● 预加载的优点在于:事先创建好对象,无论何时需要获取对象,都可以直接获取,缺点在于:相当于启动程序时就会创建对象,这样的对象越多, 启动过程就越慢,并且,如果某个对象创建出来以后,在接下来的很长一段时间都不需要使用,而此对象却一直存在于内存中,则是一种浪费
● 懒加载的优点在于:仅当需要对象时才会创建对象,不会形成浪费,缺点在于:如果当前系统已经负荷较重,需要的对象仍未加载,则会增加系统负担
● 相比而言,在开发实践中,通常认为预加载是更合理的配置
Spring中创建对象和管理对象
● [★★★★★] Spring可以将创建出来的对象管理起来,对于开发者而言, 当需要某个类的对象时,只需要从Spring容器中获取即可
● [★★★★★] 创建对象的方式有2种:
– 通过@Bean方法:在配置类中自定义方法,返回需要Spring管理的对象,此方法必须添加@Bean注解
– 通过组件扫描:在配置类中使用@ComponentScan指定需要扫描的包,并确保需要Spring管理对象的类都在此包或其子孙包下,且这些类必须添加@Component、 @Repository、@Service、@Controller中的其中某1个注解
– 如果需要Spring管理的是自定义的类的对象,应该使用组件扫描的做法,如果需要 Spring管理的对象的类型不是自定义的,只能使用@Bean方法的做法
● [★★★★★] 使用组件扫描时,在@ComponentScan中指定的包是扫描的根包,其子孙包中的类都会被扫描,通常,指定的包不需要特别精准, 但也不宜过于粗糙,你应该事先规划出项目的根包并配置在组件扫描中, 且保证自定义的每个组件类都在此包或其子孙包中
● [★★★★★] 在Spring框架的解释范围内,@Component、 @Repository、@Service、@Controller的作用是完全相同的,但语义不同,应该根据类的定位进行选取
● [★★★★★] @Configuration是特殊的组件注解,Spring会通过代理模式来处理,此注解应该仅用于配置类
● [★★★☆☆] 使用@Bean方法时,beanName默认是方法名,也可以在@Bean注解中配置参数来指定beanName
● [★★★☆☆] 使用组件扫描时,beanName默认是将类名首字母改为小 写的名称(除非类名不符合首字母大写、第2字母小写的规律,也可以在@Component或其它组件注解中配置参数来指定beanName
● [★★★☆☆] Spring Bean的作用域默认是预加载的单例的,可以通过@Scope(“prototype”)配置为“非单例的”,在单例的前提下,可以通过 @Lazy配置为“懒加载的”,通常,保持为默认即可
● [★★★★★] 关于配置注解参数:
– 如果你需要配置的只是注解的value这1个属性,不需要显式的写出属性名称
– 如果你需要配置注解中的多个属性,每个属性都必须显式写出属性名称,包括value 属性
– 如果你需要配置的注解属性的值是数组类型,当只指定1个值时,可以不使用大括号将值框住,当指定多个值时,多个值必须使用大括号框住,且各值之间使用逗号分隔
– 你可以通过查看注解的源代码来了解注解可以配置哪些属性、属性的值类型、默认值
– 在注解的源代码中,@AliasFor可理解为“等效于”
自动装配机制
● Spring的自动装配机制表现为:当某个量需要被赋值时,可以使用特定的语法,使得Spring尝试从容器找到合适的值,并自动完成赋值
● 最典型的表现就是在类的属性上添加@Autowired注解,Spring就会尝试从容器中找到合适的值为这个属性赋值
● 示例代码(1/4):

● 示例代码(2/4):
● 示例代码(3/4):
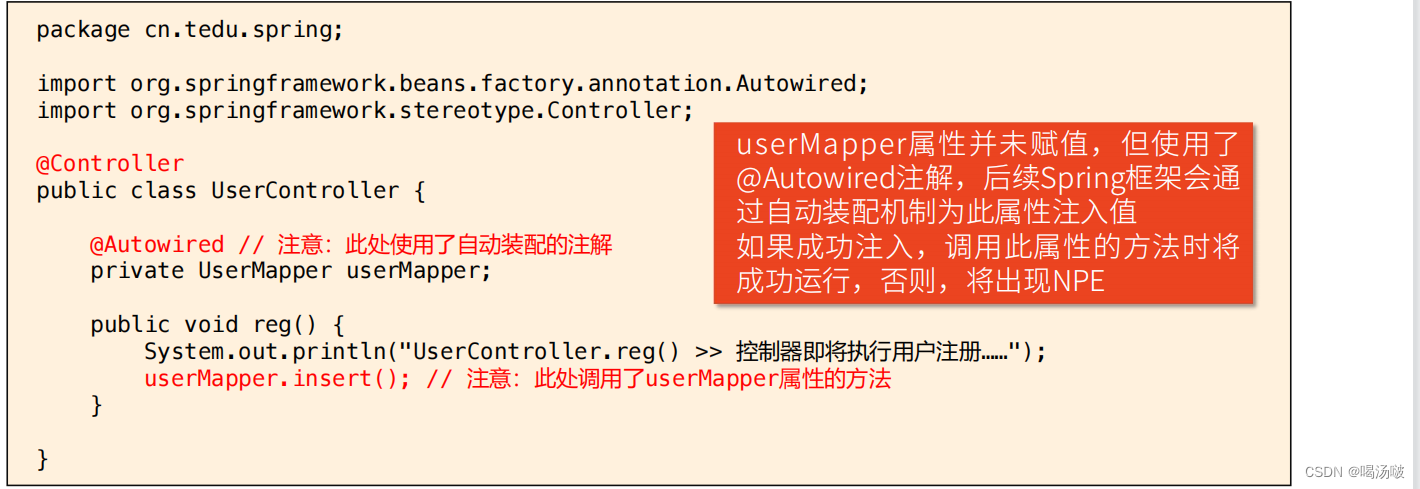
● 示例代码(4/4):
● 代码解析:
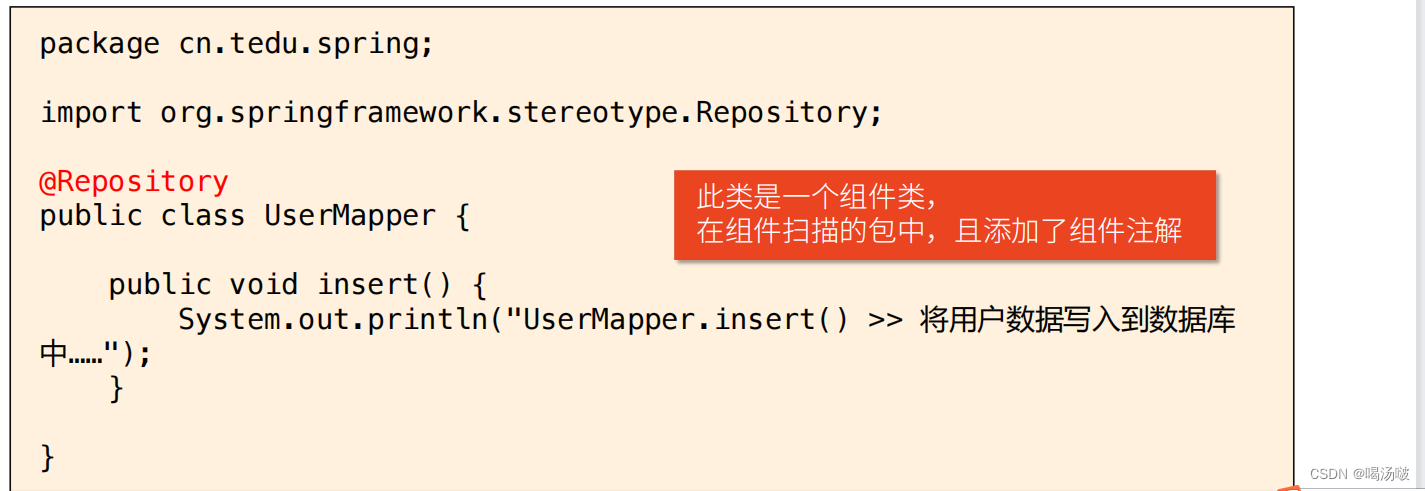
– 在main()方法中,由于加载了SpringConfig类,根据SpringConfig上配置的@ComponentScan,将执行组件扫描
– 由于UserMapper和UserController都在组件扫描的包范围内,所以Spring框架会自动调用它们的构造方法以创建对象,并把对象保管在Spring容器中
– 由于UserController中的userMapper属性添加了@Autowired注解,所以Spring框架会尝试为此属性注入值,且由于在Spring容器中存在UserMapper对象,则可以成功注入,使得userMapper属性是有值的
– 最终userController调用reg()方法时,实现过程中还通过userMapper调用了insert()方法,整个执行过程中不会出错,在控制台可以看到对应的输出文本
● 除了对属性装配以外,Spring的自动装配机制还可以表现为:如果某个方法是由Spring框架自动调用的(通常是构造方法,或@Bean方法),当 这个方法被声明了参数时,Spring框架也会自动的尝试从容器找到匹配的对象,用于调用此方法
● 对方法的参数自动装配时,如果方法有多个参数,各参数的先后顺序是不重要的
@Autowired的装配机制
● 关于@Autowired的装配机制,首先,会根据需要装配的数据的类型在 Spring容器中统计匹配的Bean(对象)的数量
● 当匹配的Bean数量为0个时,判断@Autowired注解的required属性值 – true(默认):装配失败,启动项目时即抛出NoSuchBeanDefinitionException – false:放弃自动装配,不会报告异常,后续直接使用此属性时,会出现NPE
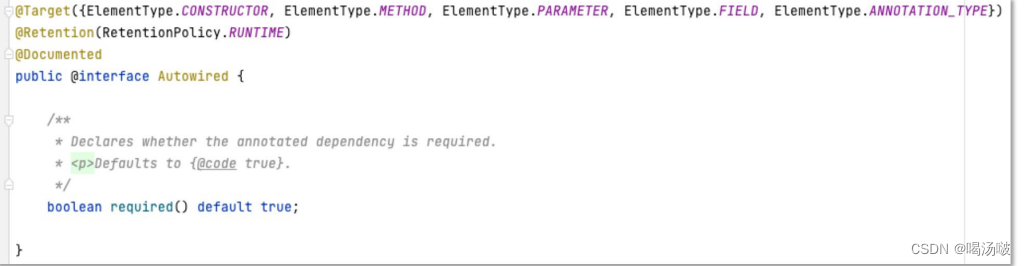
● 当匹配的Bean数量为1个时,将直接装配,且装配成功
● 当匹配的Bean数量为多个时:自动尝试按照名称实现装配(即:要求属性名称与beanName相同)
– 存在与属性名称匹配的Spring Bean:装配成功
– 不存在与属性名称匹配的Spring Bean:装配失败,启动项目时即抛出 NoUniqueBeanDefinitionException
自动装配的小结
● [★★★★★] 当某个属性需要被注入值,且你肯定此值存在于Spring容器中,你可以在属性上添加@Autowired注解,则Spring框架会自动为此属性注入值
● [★★★★★] 如果某个方法是由Spring调用的,当方法体中需要某个值, 且你肯定此值存在于Spring容器中,你可以将其声明为方法的参数,则Spring框架会自动从容器中找到此值并且于调用此方法,如果声明了多个这样的参数,各参数的先后顺序是不重要的
● [★★★★★] 自动装配的前提是Spring会自动创建此类的对象,否则,Spring不可能为属性赋值,也不可能调用类中的方法
● [★★★★★] @Autowired的装配机制的表现是可以根据类型实现装配, 并且,当匹配类型的Bean有多个时,还可以根据名称进行匹配,从而实现装配,你需要熟记具体装配机制(由于篇幅较长,请参见前序说明)
关于Spring MVC框架
关于Spring MVC框架
● Spring MVC是基于Spring框架基础之上的,主要解决了后端服务器接收客户端提交的请求,并给予响应的相关问题
● MVC = Model + View + Controller,它们分别是:
– Model:数据模型,通常由业务逻辑层(Service Layer)和数据访问层(Data Access Object Layer)共同构成
– View:视图
– Controller:控制器
– MVC为项目中代码的职责划分提供了参考
● 需要注意:Spring MVC框架只关心V-C之间的交互,与M其实没有任何关系。
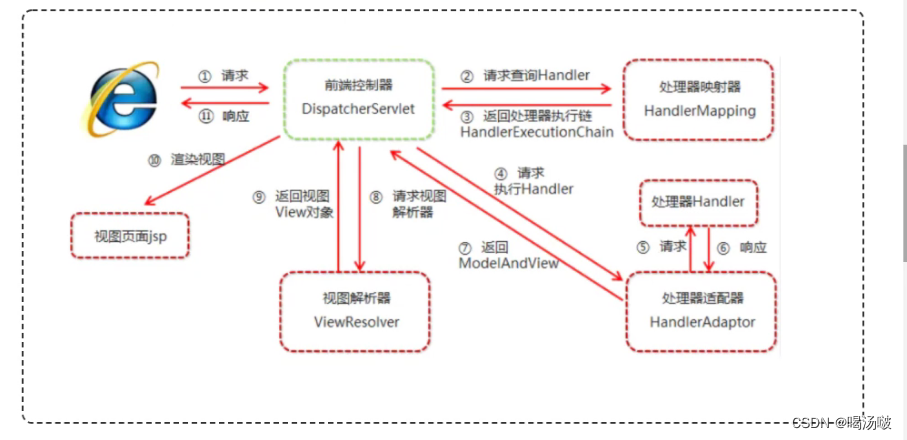
● Spring MVC的核心执行流程图如下所示:
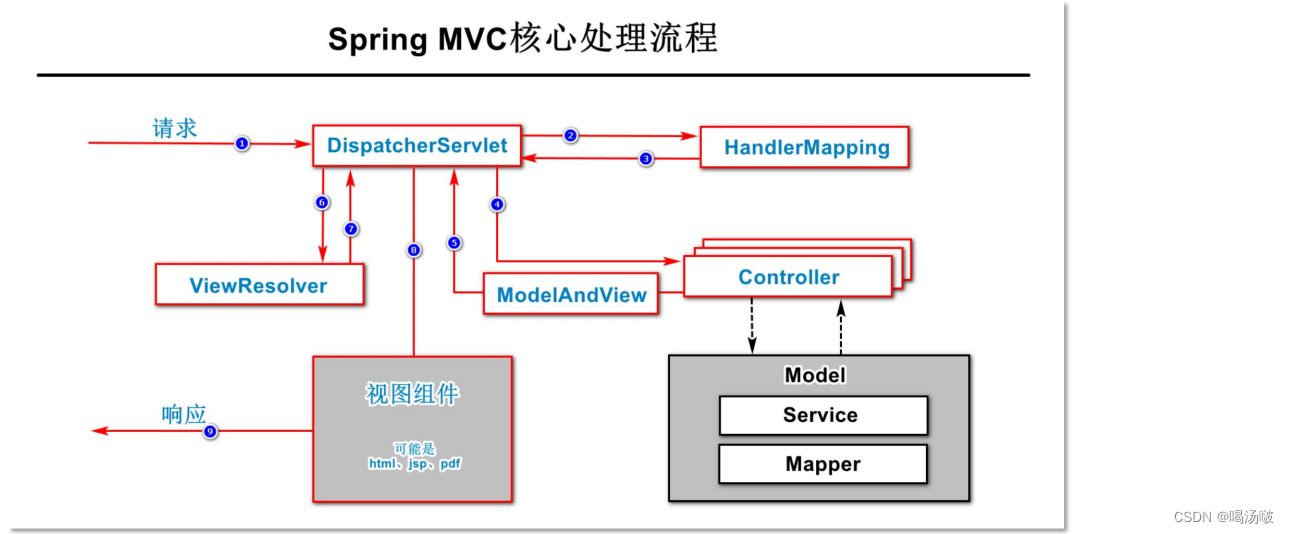
SpringMVC运行流程
创建Spring MVC工程:
● 请参考 http://doc.canglaoshi.org/doc/idea_tomcat/index.html 创建项目。
● 【案例目标】开发使用Spring MVC框架的项目,将其部署到Tomcat,最终,部署此项目启动Tomcat,用户在浏览器中输入指定的URL提交请求后,项目可以对此进行简单的响应
● 在pom.xml中添加spring-webmvc依赖项:
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-webmvc</artifactId>
<version>5.3.14</version>
</dependency>

● 提示:如果后续运行时提示不可识别Servlet相关类,则补充添加以下依赖项:
<dependency>
<groupId>javax.servlet</groupId>
<artifactId>javax.servlet-api</artifactId>
<version>3.1.0</version>
<scope>provided</scope>
</dependency>

● 以上代码中的provided表示此依赖不会参与测试或部 署,因为当Web项目部署到Tomcat中后,Tomcat环境会包含此依赖项
响应JSON格式的正文
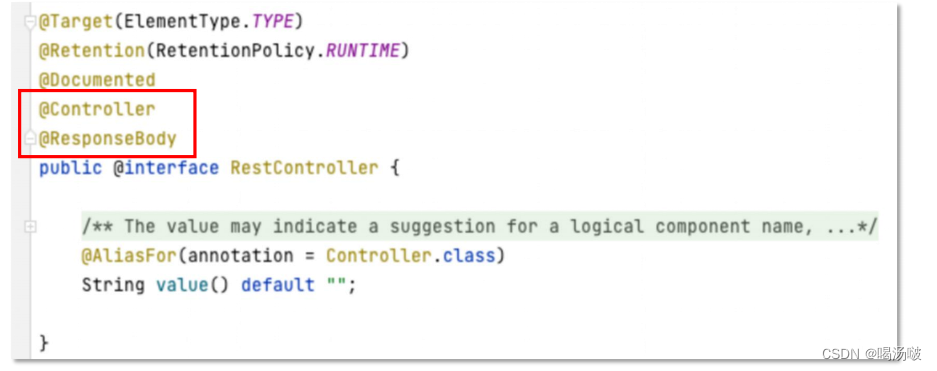
● 在Spring MVC框架中,还提供了@RestController注解,它同时具有 @Controller和@ResponseBody注解的效果,所以,在响应正文的控制器上,只需要使用@RestController即可,不必再添加@Controller和 @ResponseBody注解。
● Spring MVC内置了一系列的转换器(Converter),用于将方法的返回值转换为响应到客户端的数据(并补充其它必要数据),并且,Spring MVC会根据方法的返回值不同,自动选取某个转换器,例如,当方法的返回值是String时,会自动使用StringHttpMessageConverter,这个转换器的特点就是直接将方法返回的字符串作为响应的正文,并且,在许多版本的Spring MVC框架中,其默认的响应文档的字符集是ISO-8859-1,所以在在许多版本的Spring MVC中响应String正文时默认不支持非ASCII字 符(例如中文)
● 在开发实践中,不会使用String作为处理请求的方法的返回值类型,主要是因为普通的字符串不足以清楚的表现多项数据,通常建议使用XML或JSON语法来组织数据
● 主流的做法是向客户端响应JSON格式的字符串,需要在项目中添加jackson-databind的依赖项:
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
<version>2.12.3</version>
</dependency>

● 以上jackson-databind依赖项中也有一个转换器,当Spring MVC调用的处理请求的方法的返回值是Spring MVC没有匹配的默认转换器时,会自动使用jackson-databind的转换器,而jackson-databind转换器就会解析方法的返回值,并将其处理为JSON格式的字符串,在响应头中将Content-Type设置为application/json
● 注意:在Spring MVC项目中,还需要在Spring MVC的配置类上添加@EnableWebMvc注解,否则响应时将导致出现HTTP的406错误。
响应正文的小结
● [★★★★★] 响应正文的定义:将处理请求的方法的返回值作为响应到客户端的正文数据
● [★★★★★] 响应正文的做法:
– 在方法上添加@ResponseBody
– 或,在类上添加@ResponseBody
– 或,在类上使用@RestController取代@Controller
● [★★★★★] 响应正文的格式:响应的结果通常需要包含多项数据,响应 1个字符串并不便于表示这些数据,通常响应JSON格式的字符串
● [★★★☆☆] 响应正文的原理:Spring MVC内置了一系列的转换器 (Converter),根据处理请求的方法的返回值不同,自动选取某个转换 器,将方法的返回值转换为响应到客户端的数据,当方法的返回值没有匹配的默认转换器时,会自动使用jackson-databind的转换器
● [★★★★★] 当需要响应JSON格式的正文时,你需要:
– 添加jackson-databind依赖
– 在Spring MVC配置类上添加@EnableWebMvc注解
– 自定义类,作为处理请求的方法的返回值类型
– 类的属性必须添加Setter & Getter
– 使得处理请求的方法是响应正文的
响应正文的结果类型
● 当响应正文时,只要方法的返回值是自定义的数据类型,则Spring MVC 框架就一定会调用jackson-databind中的转换器,就可以将结果转换为 JSON格式的字符串
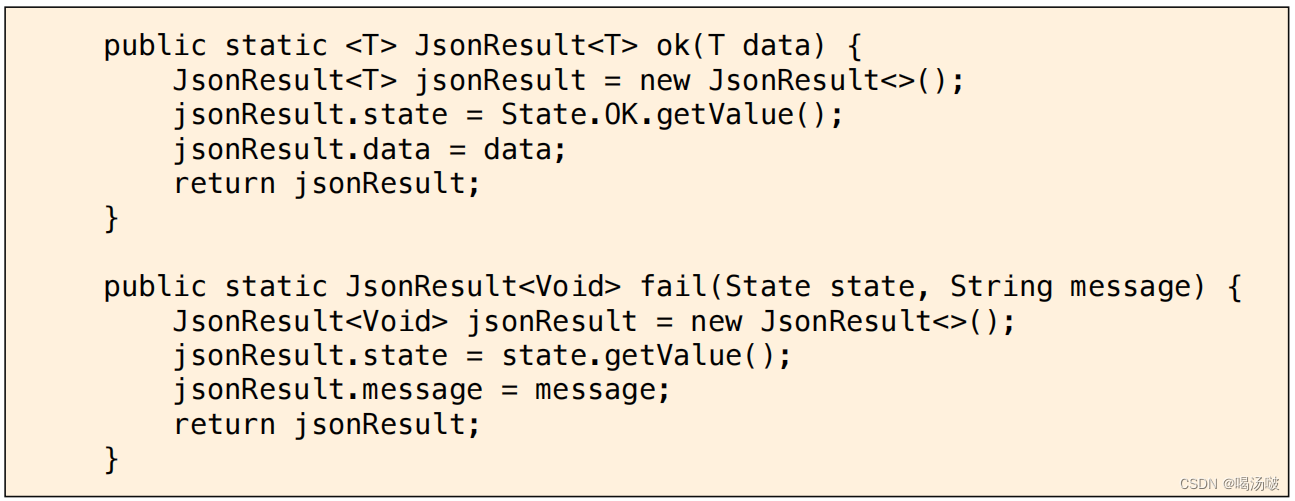
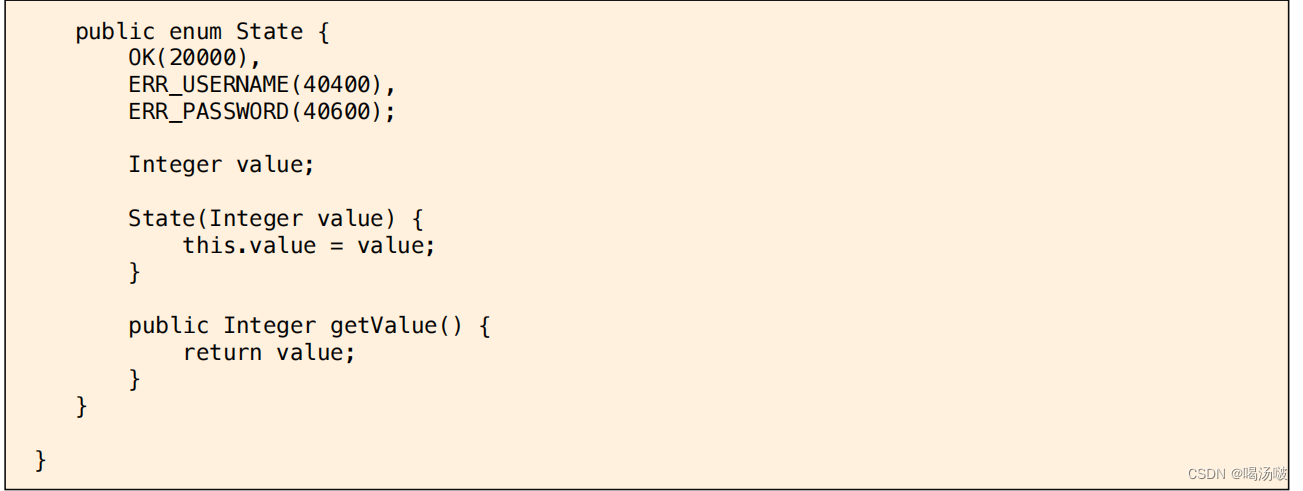
● 通常,在项目开发中,会定义一个“通用”的数据类型,无论是哪个控制 器的哪个处理请求的方法,最终都将返回此类型
● 显示的通用返回类型如下:

统一处理异常
● Spring MVC框架提供了统一处理异常的机制,使得特定种类的异常对应一段特定的代码,后续,当编写代码时,无论在任何位置,都可以将异常直接抛出,由统一处理异常的代码进行处理即可
– 无论哪种异常(包括RuntimeException及其子孙类异常),只要没有显式的使用 try…catch语法进行捕获并处理,均视为抛出
● 关于统一处理异常,需要自定义方法对异常进行处理,关于此方法:
– 注解:必须添加@ExceptionHandler注解
– 访问权限:应该是公有的
– 返回值类型:可参考处理请求的方法的返回值类型
– 方法名称:自定义
– 参数列表:必须包含1个异常类型的参数,并且可按需添加HttpServletRequest、 HttpServletResponse等少量特定的类型的参数,不可以随意添加参数
● 例如:

● 注意:以上处理异常的代码,只能作用于当前控制器类中各个处理请求的 方法,对其它控制器类的中代码并不产生任何影响,也就无法处理其它控制类中处理请求时出现的异常!
● 为保证更合理的处理异常,应该:
– 将处理异常的代码放在专门的类中
– 在此类上添加@ControllerAdvice注解
– 由于目前主流的响应方式都是“响应正文”的,则可以将@ControllerAdvice替换为 @RestControllerAdvice
● 例如,创建GlobalExceptionHandler类,代码如下:

● 处理的方法的参数中的异常类型,就是Spring MVC框架将统一处理的异常类型,例如将参数声明为Throwable类型时,所有异常都可被此方法进行处理!但是,在处理过程中,应该判断当前异常对象所归属的类型,以 针对不同类型的异常进行不同的处理
● Spring MVC允许存在多个统一处理异常的方法,这些方法可以在不同的 类中,只要处理的异常的类型不冲突即可(允许继承) – 例如:如果有2个或多个方法都处理NullPointerException,是错误的一例如:如果同时存在2个方法,分别处理NullPointerException和 RuntimeException,是允许的
● 例如:
● 在开发实践中,通常都会有handleThrowable()方法(方法名是自定义 的),以避免某个异常没有被处理而导致500错误! – 此方法中应该输出异常的相关信息,甚至跟踪信息,否则,当程序运行此至处时,可能不便于观察、分析、记录出现异常
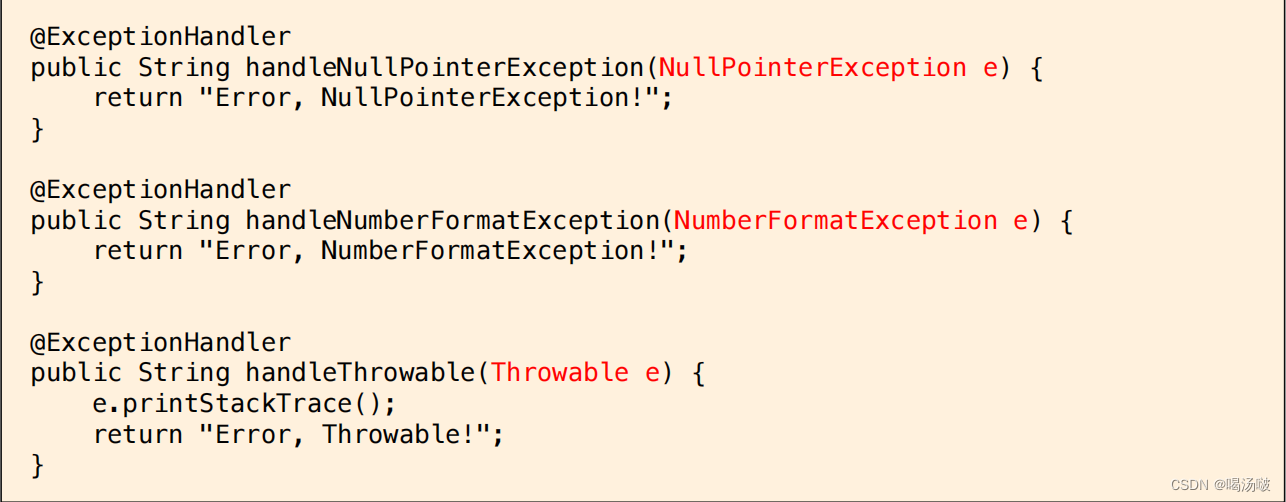
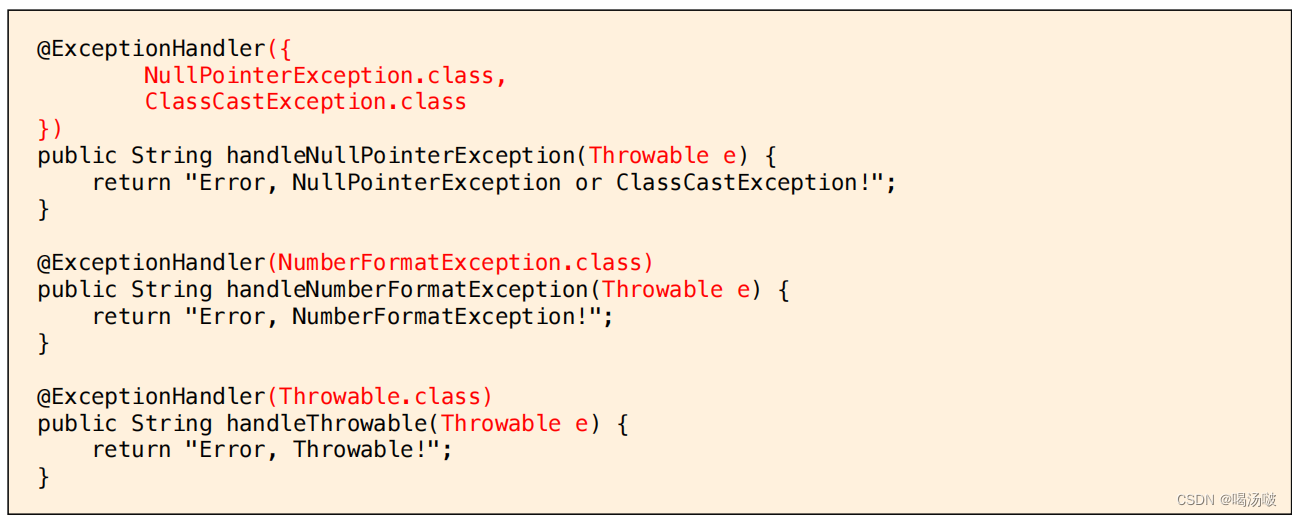
● @ExceptionHandler注解还可用于配置被注解的方法能够处理的异常的类型,其效力的优先级高于在方法的参数上指定异常类型
● 在开发实践中,建议为每一个@ExceptionHandler配置注解参数,在注解参数中指定需要处理异常的类型,而处理异常的方法的参数类型只需要 包含@ExceptionHandler配置的类型即可,甚至可以是Throwable
● 例如:
拦截器(Interceptor)
● 在Spring MVC框架中,拦截器是可以运行在所有控制器处理请求之前和之后的一种组件,并且,如果拦截器运行在控制器处理请求之前,还可以选择对当前请求进行阻止或放行。
● 注意:拦截器的目的并不是“拦截下来后阻止运行”,更多的是“拦截下 来后执行某些代码”,其优势在于可作用于若干种不同请求的处理过程, 即写一个拦截器,就可以在很多种请求的处理过程中被执行。
● 只要是若干种不同的请求过程中都需要执行同样的或高度相似的代码,都 可以使用拦截器解决,典型的例如验证用户是否已经登录等等。
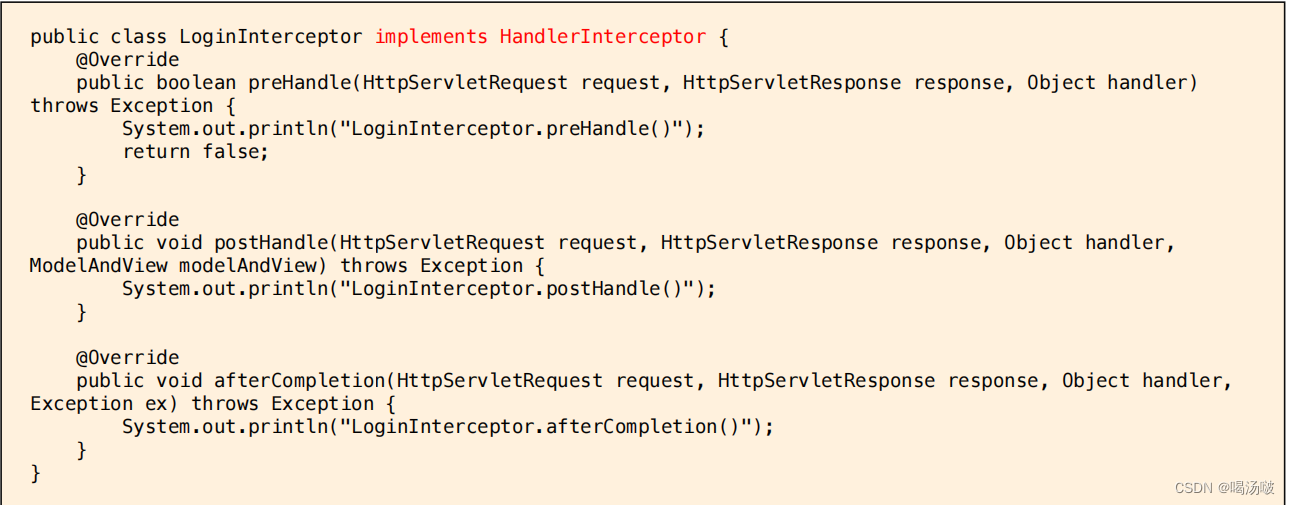
● 需要使用拦截器时,需要自定义类,实现HandlerInterceptor接口,例如:
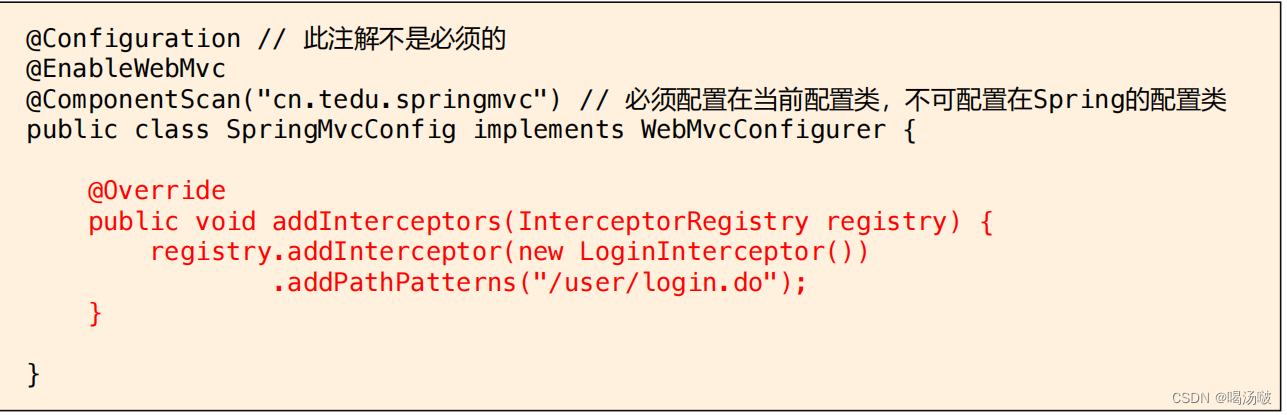
● 每个拦截器都必须注册才会被启用,注册过程通过重写 WebMvcConfigure接口中的addInterceptors()方法即可,例如:
● 当进行访问时,在浏览器窗口中将看到一片空白,在Tomcat控制台可以看到preHandle()方法已经执行
● 当把拦截器中preHandle()方法的返回值改为true时,在Tomcat控制台可以看到依次执行了preHandle() -> 控制器中处理请求的方法 -> postHandle() -> afterCompletion()
● preHandle()方法的返回值为true时,表示“放行”,为false时,表示 “阻止
● 关于注册拦截器时的配置,使用链式语法可以先调用addInterceptor()方 法添加拦截器,然后调用addPathPatter()方法添加哪些路径需要被拦截, 此方法的参数可以是String…,也可以是List,在编写路径值时, 可以使用作为通配符,例如配置为/user/,则可以匹配/user/login.do、 /user/reg.do等所有直接在/user下的路径,但不能匹配/user/1/info.do, 如果需要匹配若干层级,必须使用2个连续的星号,例如配置为/user/**
● 一旦使用通配符,就有可能导致匹配的范围过大,例如配置为/user/**时, 还可以匹配到/user/reg.do(注册)和/user/login.do(登录),如果此拦截器是用于“验证用户是否登录”的,则不应该对这2个路径进行处理, 那么,配置拦截器时,还可以在链式语法中调用excludePathPattern()方 法,以添加“排除路径”(例外)
● 配置示例:

Slf4j日志框架
在开发实践中,不允许使用System.out.println()或类似的输出语句来输出显示关键数据(核心数据、敏感数据等),因为,如果是这样使用,无论是在开发环境,还是测试环境,还是生产环境中,这些输出语句都将输出相关信息,而删除或添加这些输出语句的操作成本比较高,操作可行性低。
推荐的做法是使用日志框架来输出相关信息!
当添加了Lombok依赖后,可以在需要使用日志的类上添加@Slf4j注解,然后,在类的任意中,均可使用名为log的变量,且调用其方法来输出日志(名为log的变量也是Lombok框架在编译期自动补充的声明并创建对象)!
在Slf4j日志框架中,将日志的可显示级别根据其重要程度(严重程度)由低到高分为:
- trace:跟踪信息
- debug:调试信息
- info:一般信息,通常不涉及关键流程和敏感数据
- warn:警告信息,通常代码可以运行,但不够完美,或不规范
- error:错误信息
- 在配置文件中,可以通过
logging.level.包名.类名来设置当前类的日志显示级别,例如:
logging.level.cn.tedu.boot.demo.service.impl.AdminServiceImpl: info
- 当设置了显示的日志级别后,仅显示设置级别和更重要的级别的日志,例如,设置为
info时,只显示info、warn、error,不会显示debug、trace级别的日志!
当输出日志时,通过log变量调用trace()方法输出的日志就是trace级别的,调用debug()方法输出的日志就是debug()级别的,以此类推,可调用的方法还有info()、warn()、error()。
在开发实践中,关键数据和敏感数据都应该通过trace()或debug()进行输出,在开发环境中,可以将日志的显示级别设置为trace,则会显示所有日志,当需要交付到生产环境中时,只需要将日志的显示级别调整为info即可!
默认情况下,日志的显示级别是info,所以,即使没有在配置文件中进行正确的配置,所有info、warn、error级别的日志都会输出显示。
在配置时,属性名称中的logging.level部分是必须的,在其后,必须写至少1级包名,例如:
logging.level.cn: trace
以上配置表示cn包及其子孙包下的所有类中的日志都按照trace级别进行显示!
在开发实践中,属性名称通常配置为logging.level.项目根包,例如:
logging.level.cn.tedu.boot.demo: trace
在使用Slf4j时,通过log调用的每种级别的方法都被重载了多次(各级别对应除了方法名称不同,重载的次数和参数列表均相同),推荐使用的方法是参数列表为(String format, Object... arguments)的,例如:
public void trace(String format, Object... arguments);
public void debug(String format, Object... arguments);
public void info(String format, Object... arguments);
public void warn(String format, Object... arguments);
public void error(String format, Object... arguments);
以上方法中,第1个参数是将要输出的字符串的模式(模版),在此字符串中,如果需要包含某个变量值,则使用{}表示,如果有多个变量值,均是如此,然后,再通过第2个参数(是可变参数)依次表示各{}对应的值,例如:
log.debug("加密前的密码:{},加密后的密码:{}", password, encodedPassword);
使用这种做法,可以避免多变量时频繁的拼接字符串,另外,日志框架会将第1个参数进行缓存,以此提高后续每一次的执行效率。
其实,Slf4j日志框架只是日志的一种标准,并不是具体的实现(感觉上与Java中的接口有点相似),常见有具体实现了日志功能的框架有log4j、logback等,为了统一标准,所以才出现了Slf4j,同时,由于log4j、logback等框架实现功能并不统一,所以,Slf4j提供了对主流日志框架的兼容,在Spring Boot工程中,spring-boot-starter就已经依赖了spring-boot-starter-logging,而在此依赖下,通常包括Slf4j、具体的日志框架、Slf4j对具体日志框架的兼容。
密码加密
对密码进行加密,可以有效的保障密码安全,即使出现数据库泄密,密码安全也不会受到影响!为了实现此目标,需要在对密码进行加密时,使用不可逆的算法进行处理!
通常,不可以使用加密算法对密码进行加密码处理,从严格定义上来看,所有的加密算法都是可以逆向运算的,即同时存在加密和解密这2种操作,加密算法只能用于保证传输过程的安全,并不应该用于保证需要存储下来的密码的安全!
哈希算法都是不可逆的,通常,用于处理密码加密的算法中,典型的是一些消息摘要算法,例如MD5、SHA256或以上位数的算法。
消息摘要算法的主要特征有:
- 消息相同时,摘要一定相同
- 某种算法,无论消息长度多少,摘要的长度是固定的
- 消息不同时,摘要几乎不会相同
在消息摘要算法中,以MD5为例,其运算结果是一个128位长度的二进制数,通常会转换成十六进制数显示,所以是32位长度的十六进制数,MD5也被称之为128位算法。理论上,会存在2的128次方种类的摘要结果,且对应2的128次方种不同的消息,如果在未超过2的128次方种消息中,存在2个或多个不同的消息对应了相同的摘要,则称之为:发生了碰撞。一个消息摘要算法是否安全,取决其实际的碰撞概率,关于消息摘要算法的破解,也是研究其碰撞概率。
存在穷举消息和摘要的对应关系,并利用摘要在此对应关系进行查询,从而得知消息的做法,但是,由于MD5是128位算法,全部穷举是不可能实现的,所以,只要原始密码(消息)足够复杂,就不会被收录到所记录的对应关系中去!
为了进一步提高密码的安全性,在使用消息摘要算法进行处理时,通常还会加盐!盐值可以是任意的字符串,用于与密码一起作为被消息摘要算法运算的数据即可,例如:
@Test
public void md5Test() {
String rawPassword = "123456";
String salt = "kjfcsddkjfdsajfdiusf8743urf";
String encodedPassword = DigestUtils.md5DigestAsHex(
(salt + salt + rawPassword + salt + salt).getBytes());
System.out.println("原密码:" + rawPassword);
System.out.println("加密后的密码:" + encodedPassword);
}
加盐的目的是使得被运算数据变得更加复杂,盐值本身和用法并没有明确要求!
甚至,在某些用法或算法中,还会使用随机的盐值,则可以使用完全相同的原消息对应的摘要却不同!
推荐了解:预计算的哈希链、彩虹表、雪花算法。
为了进一步保证密码安全,还可以使用多重加密,即反复调用消息摘要算法。
除此以外,还可以使用安全系数更高的算法,例如SHA-256是256位算法,SHA-384是384位算法,SHA-512是512位算法。
一般的应用方式可以是:
public class PasswordEncoder {
public String encode(String rawPassword) {
// 加密过程
// 1. 使用MD5算法
// 2. 使用随机的盐值
// 3. 循环5次
// 4. 盐的处理方式为:盐 + 原密码 + 盐 + 原密码 + 盐
// 注意:因为使用了随机盐,盐值必须被记录下来,本次的返回结果使用$分隔盐与密文
String salt = UUID.randomUUID().toString().replace("-", "");
String encodedPassword = rawPassword;
for (int i = 0; i < 5; i++) {
encodedPassword = DigestUtils.md5DigestAsHex(
(salt + encodedPassword + salt + encodedPassword + salt).getBytes());
}
return salt + encodedPassword;
}
public boolean matches(String rawPassword, String encodedPassword) {
String salt = encodedPassword.substring(0, 32);
String newPassword = rawPassword;
for (int i = 0; i < 5; i++) {
newPassword = DigestUtils.md5DigestAsHex(
(salt + newPassword + salt + newPassword + salt).getBytes());
}
newPassword = salt + newPassword;
return newPassword.equals(encodedPassword);
}
}
Validation框架
当客户端向服务器提交请求时,如果请求数据出现明显的问题(例如关键数据为null、字符串的长度不在可接受范围内、其它格式错误),应该直接响应错误,而不是将明显错误的请求参数传递到Service!
关于判断错误,只有涉及数据库中的数据才能判断出结果的,都由Service进行判断,而基本的格式判断,都由Controller进行判断。
Validation框架是专门用于解决检查数据基本格式有效性的,最早并不是Spring系列的框架,目前,Spring Boot提供了更好的支持,所以,通常结合在一起使用。
在Spring Boot项目中,需要添加spring-boot-starter-validation依赖项,例如:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-validation</artifactId>
</dependency>
在控制器中,首先,对需要检查数据格式的请求参数添加@Valid或@Validated注解(这2个注解没有区别),例如:
@RequestMapping("/add-new")
public JsonResult<Void> addNew(@Validated AdminAddNewDTO adminAddNewDTO) {
adminService.addNew(adminAddNewDTO);
return JsonResult.ok();
}
真正需要检查的是AdminAddNewDTO中各属性的值,所以,接下来需要在此类的各属性上通过注解来配置检查的规则,例如:
@Data
public class AdminAddNewDTO implements Serializable {
@NotNull // 验证规则为:不允许为null
private String username;
// ===== 原有其它代码 =====
}
重启项目,通过不提交用户名的URL(例如:http://localhost:8080/admins/add-new)进行访问,在浏览器上会出现400错误页面,并且,在IntelliJ IDEA的控制台会出现以下警告:
2022-06-07 11:37:53.424 WARN 6404 — [nio-8080-exec-8] .w.s.m.s.DefaultHandlerExceptionResolver : Resolved [
org.springframework.validation.BindException:
org.springframework.validation.BeanPropertyBindingResult: 1 errorsField error in object ‘adminAddNewDTO’ on field ‘username’: rejected value [null]; codes [NotNull.adminAddNewDTO.username,NotNull.username,NotNull.java.lang.String,NotNull]; arguments [org.springframework.context.support.DefaultMessageSourceResolvable: codes [adminAddNewDTO.username,username]; arguments []; default message [username]]; default message [不能为null]]
从警告信息中可以看到,当验证失败时(不符合所使用的注解对应的规则时),会出现org.springframework.validation.BindException异常,则自行处理此异常即可!
如果有多个属性需要验证,则多个属性都需要添加注解,例如:
@Data
public class AdminAddNewDTO implements Serializable {
@NotNull
private String username;
@NotNull
private String password;
// ===== 原有其它代码 =====
}
首先,在State中添加新的枚举:
public enum State {
OK(200),
ERR_USERNAME(201),
ERR_PASSWORD(202),
ERR_BAD_REQUEST(400), // 新增
ERR_INSERT(500);
// ===== 原有其它代码 =====
}
然后,在GlobalExceptionHandler中添加新的处理异常的方法:
@ExceptionHandler(BindException.class)
public JsonResult<Void> handleBindException(BindException e) {
return JsonResult.fail(State.ERR_BAD_REQUEST, e.getMessage());
}
完成后,再次重启项目,继续使用为null的用户名提交请求时,可以看到异常已经被处理,此时,响应的JSON数据例如:
{
“state”:400,
“message”:“org.springframework.validation.BeanPropertyBindingResult: 2 errors\nField error in object ‘adminAddNewDTO’ on field ‘username’: rejected value [null]; codes [NotNull.adminAddNewDTO.username,NotNull.username,NotNull.java.lang.String,NotNull]; arguments [org.springframework.context.support.DefaultMessageSourceResolvable: codes [adminAddNewDTO.username,username]; arguments []; default message [username]]; default message [不能为null]\nField error in object ‘adminAddNewDTO’ on field ‘password’: rejected value [null]; codes [NotNull.adminAddNewDTO.password,NotNull.password,NotNull.java.lang.String,NotNull]; arguments [org.springframework.context.support.DefaultMessageSourceResolvable: codes [adminAddNewDTO.password,password]; arguments []; default message [password]]; default message [不能为null]”
}
关于错误提示信息,以上内容中出现了不能为null的字样,是默认的提示文本,可以通过@NotNull注解的message属性进行配置,例如:
@Data
public class AdminAddNewDTO implements Serializable {
@NotNull(message = "添加管理员失败,请提交用户名!")
private String username;
@NotNull(message = "添加管理员失败,请提交密码!")
private String password;
// ===== 原有其它代码 =====
}
然后,在处理异常时,通过异常信息获取自定义的提示文本:
@ExceptionHandler(BindException.class)
public JsonResult<Void> handleBindException(BindException e) {
BindingResult bindingResult = e.getBindingResult();
String defaultMessage = bindingResult.getFieldError().getDefaultMessage();
return JsonResult.fail(State.ERR_BAD_REQUEST, defaultMessage);
}
在Validation框架中,还有其它许多注解,用于进行不同格式的验证,例如:
@NotEmpty:只能添加在String类型上,不许为空字符串,例如""即视为空字符串@NotBlank:只能添加在String类型上,不允许为空白,例如普通的空格可视为空白,使用TAB键输入的内容也是空白,(虽然不太可能在此处出现)换行产生的空白区域也是空白@Size:限制大小@Min:限制最小值@Max:限制最大值@Range:可以配置min和max属性,同时限制最小值和最大值@Pattern:只能添加在String类型上,自行指定正则表达式进行验证- 其它
以上注解,包括@NotNull是允许叠加使用的,即允许在同一个参数属性上添加多个注解!
以上注解均可以配置message属性,用于指定验证失败的提示文本。
通常:
- 对于必须提交的属性,都会添加
@NotNull - 对于数值类型的,需要考虑是否添加
@Range(则不需要使用@Min和@Max) - 对于字符串类型,都添加
@Pattern注解进行验证
关于注解
@Configuration 添加在类的声明之前,表示此类是配置类,会自动执行配置类中的@Bean方法,并解读配置类上的其它注解
@Bean 使得Spring框架自动调用此方法,并管理此方法返回的结果,@Bean方法必须存在于@Configuration类中
@Component 组件注解,添加在类的声明之前,表示此类是组件类,是通用注解,应该添加在不是控制器类,也不是业务逻辑类,也不是数据访问类的类上
@ComponentScan 组件扫描,当加载到此注解时,Spring会扫描此注解配置的根包下是否存在组件类,如果存在,会自动创建组件类的对象,如果某些类不是组件,会被跳过(无视)
@Controller 组件注解,添加在类的声明之前,表示此类是组件类,应该添加在控制器类上
@Service 组件注解,添加在类的声明之前,表示此类是组件类,应该添加在业务逻辑类上
@Repository 组件注解,添加在类的声明之前,表示此类是组件类,应该添加在数据访问类上
@Scope 配置Spring Bean的作用域,当配置为@Scope("prototype")时,Spring Bean将是“非单例的”,如果使用@Bean方法创建对象,则此注解添加在@Bean方法之前,如果使用组件扫描创建对象,则此注解添加在组件类之前
@Lazy 配置单例的Spring Bean是否是“懒加载”的,当在@Bean方法之前,或在组件类的声明之前添加此注解,则会使得此Spring Bean是懒加载的,如果使用@Bean方法创建对象,则此注解添加在@Bean方法之前,如果使用组件扫描创建对象,则此注解添加在组件类之前
@Autowired 自动装配的注解,当某个属性需要被Spring装配值时,在属性之前添加此注解,另外,此注解可以添加在Setter方法、构造方法之前,通常不需要这样处理
@EnableWebMvc 添加在Spring MVC配置类上的注解,当响应正文,且响应的是JSON格式的结果时,必须添加此注解,否则将导致406错误,另外,在Spring Boot项目中不需要手动添加
@ResponseBody 响应正文,可添加在处理请求/处理异常的方法之前,将作用于对应的方法,或添加在类之前,将作用于类中所有处理请求/处理异常的方法
@RestController 等效于@Controller + @ResponseBody
@RequestMapping 通常添加在类上,用于配置请求路径的前缀部分,也使用produces属性配置此控制器类中所有处理请求的方法响应时的文档类型,例如在类上配置为@RequestMapping(value=“user”, produces=“application/json; charset=utf-8”)
@GetMapping 是将请求类型限制为GET的@RequestMapping,通常添加在处理请求的方法上,用于配置此方法映射的请求路径
@PostMapping 参考@GetMapping
@RequestParam 添加在处理请求的方法的参数之前,可用于:指定请求参数名称、配置是否必须提交此请求参数、配置请求参数的默认值
@PathVariable 添加在处理请求的方法的参数之前,仅当在请求路径中使用占位符匹配变量值时使用,如果占位符中的名称与方法参数名称不同,还可以配置此注解的参数,以指定占位符中的名称
@ExceptionHandler 添加在处理异常的方法之前,可通过注解参数配置需要处理的异常类型
@ControllerAdvice 添加在类之前,此类中的代码在处理任何请求时都会生效
@RestControllerAdvice 等效于@ControllerAdvice + @ResponseBody
@Mapper 添加在使用Mybatis时访问数据的(每一个)接口上,使得Mybatis明确这是一个用于访问数据的接口,从而Mybatis会生成此接口的代理对象,实现最终的数据访问功能,但此方式不推荐,另见@MapperScan注解
@MapperScan 添加在配置类上,用于扫描使用Mybatis时的访问数据的接口所在的根包,使用此注解后,各接口不再需要使@Mapper注解,在配置根包时,应保证此包下只有访问数据的接口,切不可存在其它接口,因为Mybatis并不会解析接口的内部代码,只要是接口都会创建代理对象,如果你自行创建类实现了此接口还被Spring创建了对象,会出现错误
@Param 添加在使用Mybatis时访问数据的接口中的抽象方法的参数上,用于指定参数名称,在配置SQL语句时使用占位符时,占位符内的名称就是此注解的参数值,当抽象方法的参数超过1个时,必须使用此注解配置参数名称
关于异常
NoSuchBeanDefinitionException 在Spring容器中无此Bean,但又尝试获取(可能是Spring自动获取)/使用此Bean
NoUniqueBeanDefinitionException 尝试根据类型获取Bean时,由于Spring容器中有多个此类型的Bean,则出现错误
SQLIntegrityConstraintViolationException SQL约束异常,通常是尝试写的数据违背了创建数据表时的约束
BindingException 如果异常的提示信息显示Invalid bound statement (not found),则是因为使用Mybatis时,抽象方法没有找到对应的SQL配置导致的,在异常提示信息中也会显示哪个方法没有对应的SQL配置,应该检查XML中对应此抽象方法的配置,甚至检查mapperLocations的相关配置
BuilderException 如果异常的提示信息显示Parse xml error,则是某个XML文件出现语法错误,同时,通过提示信息中还可以找到是哪个XML语法错误,检查对应的XML文件并排查错误即可
SQLSyntaxErrorException SQL语法错误,在提示信息中会包含near字样,会提示SQL语句的哪个片段附近出错
TooManyResultsException 在使用Mybatis时,查询的结果可能超过1条,但是抽象方法声明的返回值类型却不是List集合类型的
解决跨域问题
在使用前后端分离的开发模式下,前端项目和后端项目可能是2个完全不同的项目,并且,各自己独立开发,独立部署,在这种做法中,如果前端直接向后端发送异步请求,默认情况下,在前端会出现类似以下错误:
Access to XMLHttpRequest at ‘http://localhost:8080/admins/add-new’ from origin ‘http://localhost:8081’ has been blocked by CORS policy: No ‘Access-Control-Allow-Origin’ header is present on the requested resource.
以上错误信息的关键字是CORS,通常称之为“跨域问题”。
通过mvc配置类允许跨域访问
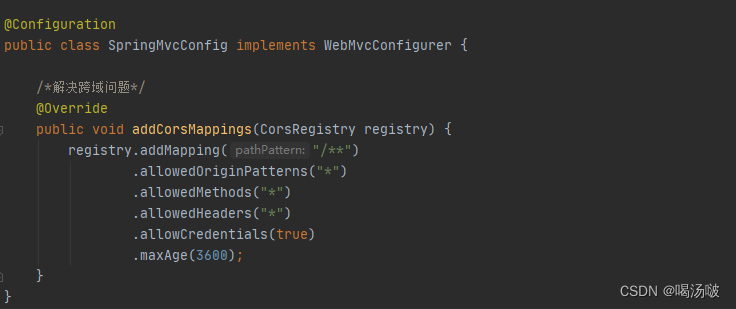
在基于Spring MVC框架的项目中,当需要解决跨域问题时,需要一个Spring MVC的配置类(实现了WebMvcConfigurer接口的类),并重写其中的方法,以允许指定条件的跨域访问,例如:
在配置类实现WebMvcConfigurer接口,重写addCorsMappings方法:
registry.addMapping("/**")
.allowedOriginPatterns("*")
.allowedMethods("*")
.allowedHeaders("*")
.allowCredentials(true)
.maxAge(3600);
通过CorsFilter过滤器允许跨域访问
@Configuration
public class CorsConfig {
@Bean
public CorsFilter corsFilter() {
CorsConfiguration corsConfiguration = new CorsConfiguration();
//1,允许任何来源
corsConfiguration.setAllowedOriginPatterns(Collections.singletonList("*"));
//2.4.x
//2,允许任何请求头
corsConfiguration.addAllowedHeader(CorsConfiguration.ALL);
//3,允许任何方法
corsConfiguration.addAllowedMethod(CorsConfiguration.ALL);
//4,允许凭证
corsConfiguration.setAllowCredentials(true);
UrlBasedCorsConfigurationSource source = new UrlBasedCorsConfigurationSource();
source.registerCorsConfiguration("/**", corsConfiguration);
return new CorsFilter(source);
}
}
关于客户端提交请求参数的格式
通常,客户端向服务器端发送请求时,请求参数可以有2种形式,第1种是直接通过&拼接各参数与值,例如:
// username=root&password=123456&nickname=jackson&phone=13800138001&email=jackson@baidu.com&description=none
let data = 'username=' + this.ruleForm.username
+ '&password=' + this.ruleForm.password
+ '&nickname=' + this.ruleForm.nickname
+ '&phone=' + this.ruleForm.phone
+ '&email=' + this.ruleForm.email
+ '&description=' + this.ruleForm.description;
第2种方式是使用JSON语法来组织各参数与值,例如:
let data = {
'username': this.ruleForm.username, // 'root'
'password': this.ruleForm.password, // '123456'
'nickname': this.ruleForm.nickname, // 'jackson'
'phone': this.ruleForm.phone, // '13800138001'
'email': this.ruleForm.email, // 'jackson@baidu.com'
'description': this.ruleForm.description // 'none'
};
具体使用哪种做法,取决于服务器端的设计:
- 如果服务器端处理请求的方法中,在参数前添加了
@RequestBody,则允许使用以上第2种做法(JSON数据)提交请求参数,不允许使用以上第1种做法(使用&拼接) - 如果没有使用
@RequestBody,则只能使用以上第1种做法















 902
902











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









