







面试题25:二叉树中和为某一值的路径
题目:输入一棵二叉树和一个整数,打印出二叉树中结点值的和为输入整数的所有路径。从树的根结点开始往下一直到叶结点所经过的结点形成一条路径。二叉树结点的定义如下:
struct BinaryTreeNode
{
int m_nValue;
BinaryTreeNode* m_pLeft;
BinaryTreeNode* m_pRight;
};解题思路:当用前序遍历的方式访问到某一结点时,我们把该结点添加到路径上,并累加该结点的值。如果该结点为叶结点并且路径中结点值的和刚好等于输入的整数,则当前的路径符合要求,我们把它打印出来。如果当前结点不是叶结点,则继续访问它的子结点。当前结点访问结束后,递归函数将自动回到它的父结点。因此我们在函数退出之前要在路径上删除当前结点并减去当前结点的值,以确保返回父结点时路径刚好是从根结点到父结点的路径。我们不难看出保存路径的数据结构实际上是一个栈,因为路径要与递归调用状态一致,而递归调用的本质就是一个压栈和出栈的过程。
参考代码:
void FindPath(BinaryTreeNode* pRoot,int expectedSum)
{
if(pRoot == NULL)
return;
std::vector<int> path;
int currentSum = 0;
FindPath(pRoot,expectedSum,path,currentSum);
}
void FindPath
(
BinaryTreeNode* pRoot,
int expectedSum,
std::vector<int>& path,
int currentSum
)
{
currentSum += pRoot->m_nValue;
path.push_back(pRoot->m_nValue)
//如果是叶结点,并且路径上结点的和等于输入的值
//打印出这条路径
bool isLeaf = pRoot->m_pLeft == NULL && pRoot->m_pRight == NULL;
if(currentSum == expectedSum && isLeaf)
{
printf("A path is found: ");
std::vector<int>::iterator iter = path.begin();
for(;iter != path.end(); ++iter)
printf("%d\t",*iter);
printf("\n");
}
//如果不是叶结点,则遍历它的子结点
if(pRoot->m_pLeft != NULL)
FindPath(pRoot->m_pLeft,expectedSum,path,currentSum);
if(pRoot->m_pRight != NULL)
FindPath(pRoot->m_pRight,expectedSum,path,currentSum);
//在返回到父结点之前,在路径上删除当前结点
path.pop_back();
}面试题26:复杂链表的复制
题目:请实现函数ComplexListNode* Clone(ComplexListNode* pHead),复制一个复杂链表。在复杂链表中,每个结点除了有一个m_pNext指针指向下一个结点外,还有一个m_pSibling指向链表中的任意结点或者NULL。结点的表示如下:
struct ComplexListNode
{
int m_nValue;
ComplexListNode* m_pNext;
ComplexListNode* m_pSibling;
};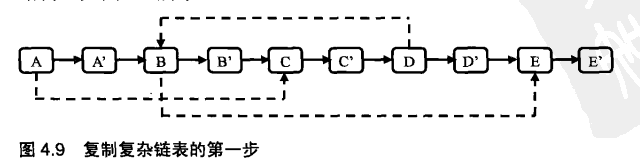
注:复制原始链表的任意结点N并创建新结点N’,再把N’链接到N的后面。其代码如下:
void CloneNodes(ComplexListNode* pHead)
{
ComplexListNode* pNode = pHead;
while(pNode != NULL)
{
ComplexListNode* pCloned = new ComplexListNode();
pCloned->m_nValue = pNode->m_nValue;
pCloned->m_pNext = pNode->m_pNext;
pCloned->m_pSibling =NULL;
pNode->m_pNext = pCloned;
pNode=pCloned->m_pNext;
}
}第二步设置复制出来的结点的m_pSibling。假设原始链表上的N的m_pSibling指向结点S,那么其对应复制出来的N’是N的m_pNext指向的结点,同样S’也是S的m_pNext指向的结点。设置m_pSibling之后的链表如图4.10所示。
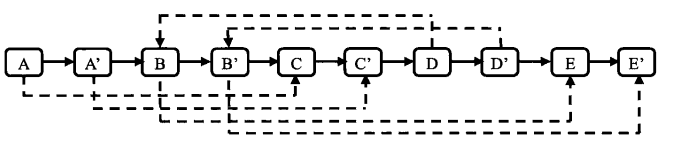
注:如果原始链表上的结点N的m_pSibling指向S,则它对应的复制结点N’的m_pSibling指向S的下一结点S’。
下面是完成第二步的参考代码:
void ConnectSiblingNodes(ComplexListNode* pHead)
{
ComplexListNode* pNode = pHead;
while(pNode != NULL)
{
ComplexListNode* pCloned = pNode->m_pNext;
if(pNode->m_pSibling != NULL)
{
pCloned->m_pSibling = pNode->m_pSibling->m_pNext;
}
pNode = pCloned->m_pNext;
}
}第三步把这个长链表拆分成两个链表:把奇数位置的结点用m_pNext链接起来就是原始链表,把偶数位置的结点用m_pNext链接起来就是复制出来的链表。图4.10中的链表拆分之后的两个链表如图4.11所示。
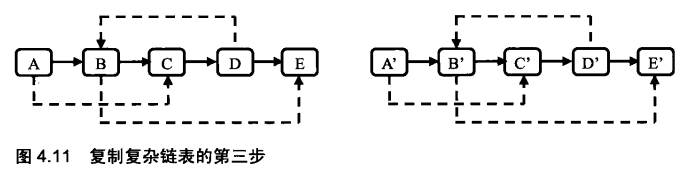
注:把第二步得到的链表拆分成两个链表,奇数位置上的结点组成原始链表,偶数位置上的结点组成复制出来的链表。
参考代码:
ComplexListNode* ReconnectNodes(ComplexListNode* pHead)
{
ComplexListNode* pNode = pHead;
ComplexListNode* pClonedHead = NULL;
ComplexListNode* pClonedNode = NULL;
if(pNode != NULL)
{
pClonedHead = pClonedNode =pNode->m_pNext;
pNode->m_pNext = pClonedNode->m_pNext;
pNode->m_pNext = pClonedNode->m_pNext;
pNode = pNode->m_pNext;
}
return pClonedHead;
}我们把上面三步合起来,就是复制链表的完整过程:
ComplexListNode* Clone(ComplexListNode* pHead)
{
CloneNodes(pHead);
ConnectSiblingNodes(pHead);
return ReconnectNodes(pHead);
}参考资料《剑指Offer》















 4083
4083

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









