









文章出处:
http://blog.csdn.net/gane_cheng/article/details/53219332
http://www.ganecheng.tech/blog/53219332.html (浏览效果更好)
在学习,工作,生活中,我们经常会遇到各种分类问题。
让你猜测一个身高2.16的人的职业,你一般会猜测他是篮球运动员。
收到一条含有“中奖”词语的短信,会怀疑是一条垃圾短信。
新闻编辑,收到一封含有“马云”词语的稿子,会倾向于将这个新闻放在科技板块,而不是财经,娱乐,体育板块。
去找一家餐馆吃饭,我们倾向于找人多的一家。
贝叶斯将生活中的概率问题,用数学方式表示了出来。下面,让我们看看朴素贝叶斯模型如何识别垃圾邮件这个问题。
1. 概念简介
贝叶斯(约1701-1761) Thomas Bayes,英国数学家。约1701年出生于伦敦,做过神甫。1742年成为英国皇家学会会员。1761年4月7日逝世。贝叶斯在数学方面主要研究概率论。他首先将归纳推理法用于概率论基础理论,并创立了贝叶斯统计理论,对于统计决策函数、统计推断、统计的估算等做出了贡献。

贝叶斯定理也称贝叶斯推理,早在18世纪,英国学者贝叶斯(1702~1763)曾提出计算条件概率的公式用来解决如下一类问题:假设H[1],H[2]…,H[n]互斥且构成一个完全事件,已知它们的概率P(H[i]),i=1,2,…,n,现观察到某事件A与H[,1],H[,2]…,H[,n]相伴随机出现,且已知条件概率P(A/H[,i]),求P(H[,i]/A)。
贝叶斯公式(发表于1763年)为:
P(H[i]|A)=P(H[i])P(A│H[i])/{P(H[1])P(A│H[1]) +P(H[2])P(A│H[2])+…+P(H[n])P(A│H[n])}
对其进行重新表示。
其中 Ai,…,AnAi,…,An 为完备事件组,即 ⋃ni=1Ai=Ω,Ai⋂Aj=ϕ,P(Ai)>0⋃i=1nAi=Ω,Ai⋂Aj=ϕ,P(Ai)>0 。
推导过程:
对于两个关联事件A和B,同时发生的概率为:P(AB)=P(A|B)P(B)=P(B|A)P(A)P(AB)=P(A|B)P(B)=P(B|A)P(A) 。因此可以得到:
其中,P(B)=P(B|A)P(A)+P(B|A¯¯¯¯)P(A¯¯¯¯)P(B)=P(B|A)P(A)+P(B|A¯)P(A¯) 。因此可以得到。
公式1如果A只有两种情况,则为公式2。
朴素贝叶斯:假设给定目标值时属性之间相互条件独立。根据公式1,在给定事件B的值的情况下,Ai,…,AnAi,…,An 是相互独立的。
朴素贝叶斯模型:根据贝叶斯定理和朴素贝叶斯假设条件,从训练集中训练出来的模型。
2. 原理分析
现在的情况是这样的。有一个邮箱服务,里面有成千上万的人发送和接收邮件。可以使用黑名单来屏蔽垃圾邮件,但是对于一封新邮箱地址发送的邮件,却不能识别。现在需要对邮件进行分析,判断其是垃圾邮件的概率,来帮助管理员分担一部分工作。
转换成数学问题,就是。现在有一个邮件的数据集,数据集可以从这个网址下载。
http://archive.ics.uci.edu/ml/datasets/SMS+Spam+Collection
数据集中每一行代表一封邮件。以spam开头代表是垃圾邮件,以ham开头代表是正常邮件。现在使用这个数据集训练出一个朴素贝叶斯模型。
再来任意一封邮件,由模型判断出这封邮件是垃圾邮件的概率。
如果这封邮件为垃圾邮件,则识别成功,如果为正常邮件,则识别错误。
有两个标准来评价模型的价值。召回率(Recall Rate)和准确率(Precision Rate)
| - | 实际为垃圾邮件 | 实际为正常邮件 |
|---|---|---|
| 识别为垃圾邮件 | A | B |
| 识别为正常邮件 | C | D |
A,B,C,D为对应的数量。
则召回率为:
准确率为:
注意:准确率和召回率是互相影响的,理想情况下肯定是做到两者都高,但是一般情况下准确率高、召回率就低,召回率低、准确率高,当然如果两者都低,那是什么地方出问题了。
如果是做搜索,那就是保证召回的情况下提升准确率;如果做疾病监测、反垃圾,则是保准确率的条件下,提升召回。
所以,在两者都要求高的情况下,可以用F1来衡量。
3. 识别的过程
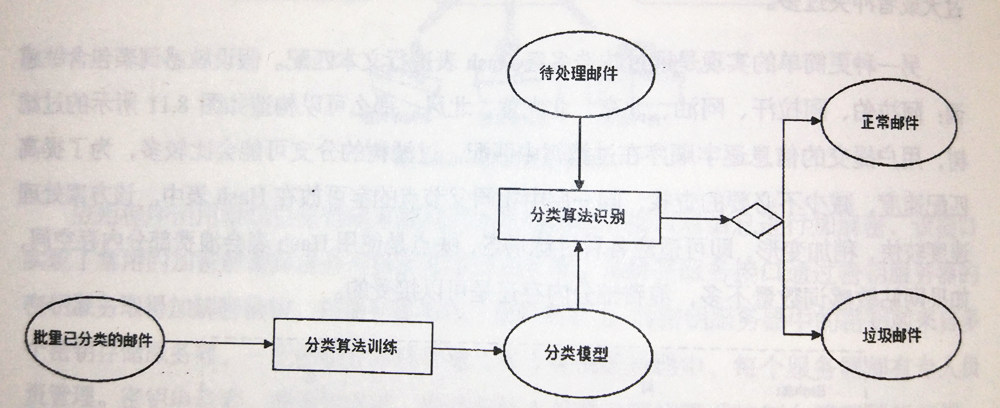
1.输入所有邮件,然后得到邮件中每个单词出现在垃圾邮件中的次数,出现在正常邮件中的次数,垃圾邮件有多少封,正常邮件有多少封。模型就训练出来了。
2.然后输入一封待处理邮件,找到里面所有出现的关键词。求出P(A|T1,…Tn)P(A|T1,…Tn),A为一封邮件是垃圾邮件的事件,T为关键词出现在一封邮件中的事件。T1,…TnT1,…Tn是多个关键词。A和T是关联的事件。T1,…TnT1,…Tn每个关键词根据朴素贝叶斯的假设,是相互独立的。P(A|T1,…Tn)P(A|T1,…Tn) 为 T1,…TnT1,…Tn 这些关键词同时出现的情况下A是垃圾邮件的概率。
P(A|T1,…Tn)P(A|T1,…Tn)求出之后,就得到一个概率,我们可以自己设置一个阈值,比如说概率大于95%时,认为此邮件为垃圾邮件。
3.一封邮件可以确定之后,我们可以从数据集中随机选取一部分邮件作为测试集,测试这些邮件的效果,得到测试的召回率和准确率,然后评价算法的效果。
4. JAVA实现
4.1. 定义模型。
本例中,是用关键词是否出现,以及出现的频率来判断邮件是否为垃圾邮件的。
class KeywordCount
{
// 关键词
public String keyword;
// 此关键词在垃圾邮件中出现的次数
public int spam;
// 垃圾邮件总数量
public int spamAll;
// 此关键词在正常邮件中出现的次数
public int legit;
// 正常邮件总数量
public int legitAll;
// 这个关键词存在的情况下,是垃圾邮件的概率
public double combiningProbabilities;
}
4.2. 将邮件中所有单词预设为关键字
// 得到所有单词
String[] banword = getAllWordsFromFile("TrainingSet/SMSSpamCollection");
// 预热数据,将所有关键字放在一个Map中
Map<String, KeywordCount> keywordMap = new HashMap<String, KeywordCount>();
for (String s : banword)
{
keywordMap.put(s, new KeywordCount(s, 0, 0, 0, 0));
}
4.3. 统计每个单词在所有邮件中出现的情况
// 得到所有训练邮件列表
List<String> mailList = getContentFromFile("TrainingSet/SMSSpamCollection");
// 统计垃圾邮件出现的次数
int spamNumber = 0;
// 统计正常邮件出现的次数
int legitNumber = 0;
// 统计每个关键字在正常邮件和垃圾邮件中出现的次数
for (int i = 0; i < mailList.size(); i++)
{
String mailContent = mailList.get(i);
// 看真实情况是否是垃圾邮件
if (mailContent.startsWith("spam"))
{
for (Map.Entry<String, KeywordCount> entry : keywordMap.entrySet())
{
boolean containFlag = FilterKeyWord(mailContent, entry.getKey());
KeywordCount keywordCount = entry.getValue();
if (containFlag == true)
{
keywordCount.spam += 1;
}
keywordCount.spamAll += 1;
}
spamNumber++;
}
else
{
for (Map.Entry<String, KeywordCount> entry : keywordMap.entrySet())
{
boolean containFlag = FilterKeyWord(mailContent, entry.getKey());
KeywordCount keywordCount = entry.getValue();
if (containFlag == true)
{
keywordCount.legit += 1;
}
keywordCount.legitAll += 1;
}
legitNumber++;
}
}
4.4. 过滤关键词
得到单个单词出现的情况下邮件是否为垃圾邮件的概率,并设定一个阈值,是否留下这个关键字。
List<String> needRemoveKey = new ArrayList<String>();
// 得到每一个关键字出现的情况下是垃圾邮件的概率的概率
for (Map.Entry<String, KeywordCount> entry : keywordMap.entrySet())
{
KeywordCount kcTemp = entry.getValue();
if (kcTemp.spam + kcTemp.legit == 0)
{
needRemoveKey.add(entry.getKey());
continue;
}
double Spam = 1.0 * kcTemp.spam / kcTemp.spamAll;
double SpamAll = 1.0 * kcTemp.spamAll / (kcTemp.spamAll + kcTemp.legitAll);
double Legit = 1.0 * kcTemp.legit / kcTemp.legitAll;
double LegitAll = 1.0 * kcTemp.legitAll / (kcTemp.spamAll + kcTemp.legitAll);
kcTemp.combiningProbabilities = (Spam * SpamAll) / (Spam * SpamAll + Legit * LegitAll); // 根据(公式2)
if (kcTemp.combiningProbabilities < 0.90)
{
needRemoveKey.add(entry.getKey());
}
}
// 过滤得到所有符合要求的对垃圾邮件有较高识别度的关键词
for (String s : needRemoveKey)
{
keywordMap.remove(s);
}
4.5. 分类算法识别测试集中的邮件
// 得到所有测试邮件列表
List<String> testMailList = getContentFromFile("TestSet/TestFile.txt");
// 成功识别的数量
int rightCount = 0;
//识别错误的数量
int wrongCount = 0;
// 总共垃圾邮件数量
int spamCount = 0;
for (String mail : testMailList)
{
// 找到这封邮件含有的关键字
String thisMail = mail;
// 总共垃圾邮件数量
if (thisMail.startsWith("spam"))
{
spamCount++;
}
List<String> oneMailKeywordList = new ArrayList<String>();
for (Map.Entry<String, KeywordCount> entry : keywordMap.entrySet())
{
boolean containFlag = FilterKeyWord(thisMail, entry.getKey());
if (containFlag == true)
{
oneMailKeywordList.add(entry.getKey());
}
}
if (oneMailKeywordList.size() <= 0)
{
// System.out.println("没有含有关键字,应该是正常邮件");
continue;
}
// 得到这封邮件所有关键词的联合概率,根据(公式3)
double Pup = 1.0 * spamNumber / (spamNumber + legitNumber);
double Pdown = 1.0f;
for (String kw : oneMailKeywordList)
{
Pup = Pup * keywordMap.get(kw).spam / keywordMap.get(kw).spamAll;
Pdown = Pdown * (keywordMap.get(kw).spam + keywordMap.get(kw).legit) / (spamNumber + legitNumber);
}
double Pmail = Pup / (Pup + Pdown);
System.out.println("该封邮件是垃圾邮件的概率为:" + Pmail + ",实际是否为垃圾邮件:" + thisMail.startsWith("spam"));
// 成功识别
if (Pmail > 0.999 && thisMail.startsWith("spam"))
{
rightCount++;
}
// 识别错误
if (Pmail > 0.999 && thisMail.startsWith("ham"))
{
wrongCount++;
}
}
System.out.println("垃圾邮件总数为" + spamCount + ",正确识别了" + rightCount + "封垃圾邮件,召回率" + rightCount * 1.0 / spamCount + ",准确率:" + rightCount * 1.0
/ (rightCount + wrongCount));
}
4.6. 测试数据
邮箱服务非常重要,规定邮件是垃圾邮件的概率大于99.9%以上才能定为垃圾邮件进行拦截。在这个前提下,过滤关键词时的阈值进行变动时,召回率和准确率的变动如下图所示。
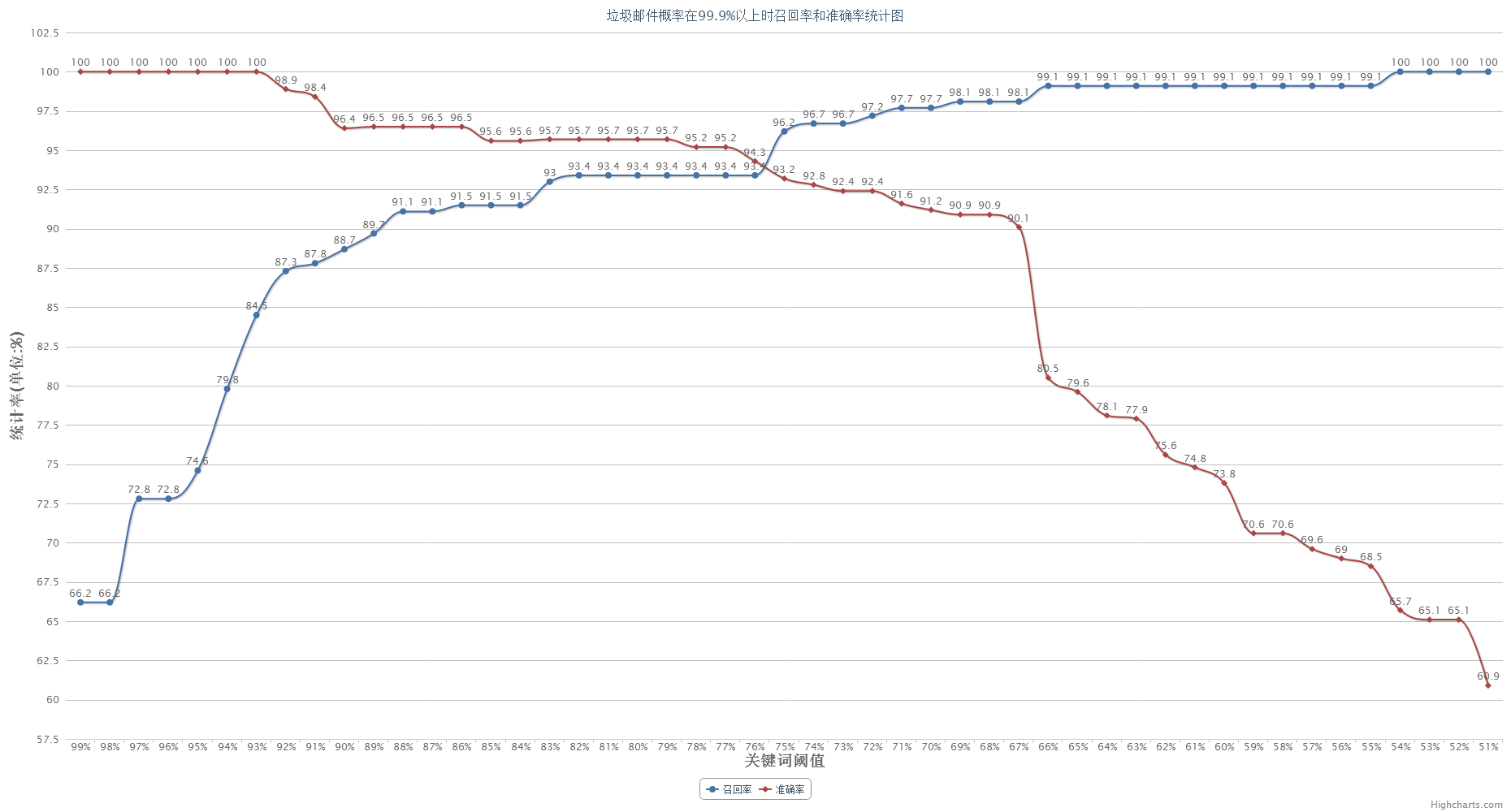
前面已经说过了,拦截垃圾邮件要在保证准确率的前提下,提高召回率。从此次实验,可以知道,过滤关键词时阈值设为93%,可以得到准确率100%,召回率84.5%。也就是说每100封垃圾邮件,只有84.5封被识别出来了。但是没有出现正常邮件识别为垃圾邮件的情况。
4.7. 源码下载
本文实现代码可以从这里下载。
http://download.csdn.net/detail/gane_cheng/9687258
GitHub地址在这儿。
https://github.com/ganecheng/SpamFilter
5. 后续改进
5.1. 改进点1:增大训练集的数据量,提高算法有效性。
理论上,把所有邮件都作为训练集,最能接近真实情况。但是数据量越大,计算花费的时间就越长。
5.2. 改进点2:增加特征向量,提高算法有效性。
实际情况,可能不只是关键词这种因素在影响着结果。也有可能是邮件的长度,关键词出现的频率,邮件发件人所在的地区,等等。增加更多维度,来提高算法有效性。
5.3. 改进点3:对有关联的关键词先聚类,提高算法有效性。
上面的实验基于一个假设,就是每个关键词是否出现都是独立发生的,事实上,关键词之间的出现是有一定关联的,如果将关联比较高的关键词先聚类,再运用朴素贝叶斯模型计算,结果会更合理一些。
6. 朴素贝叶斯的优缺点
6.1. 优点:
一、朴素贝叶斯模型发源于古典数学理论,有着坚实的数学基础,以及稳定的分类效率。
二、NBC模型所需估计的参数很少,对缺失数据不太敏感,算法也比较简单。
6.2. 缺点:
一、理论上,NBC模型与其他分类方法相比具有最小的误差率。但是实际上并非总是如此,这是因为NBC模型假设属性之间相互独立,这个假设在实际应用中往往是不成立的(可以考虑用聚类算法先将相关性较大的属性聚类),这给NBC模型的正确分类带来了一定影响。在属性个数比较多或者属性之间相关性较大时,NBC模型的分类效率比不上决策树模型。而在属性相关性较小时,NBC模型的性能最为良好。
二、需要知道先验概率。
三、分类决策存在错误率
7. 参考文献
贝叶斯定理 http://baike.baidu.com/item/%E8%B4%9D%E5%8F%B6%E6%96%AF%E5%AE%9A%E7%90%86
数学之美番外篇:平凡而又神奇的贝叶斯方法 http://mindhacks.cn/2008/09/21/the-magical-bayesian-method/
Naive Bayes算法 http://blog.sina.com.cn/s/blog_626896c10101ikla.html
准确率与召回率 http://blog.csdn.net/wangzhiqing3/article/details/9058523
各种分类算法的优缺点 http://bbs.pinggu.org/thread-2604496-1-1.html
机器学习实战1:朴素贝叶斯模型:文本分类+垃圾邮件分类 http://www.cnblogs.com/rongyux/p/5602037.html















 617
617

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









