









想看看自己写的素数生成代码与专业coder的差别。一开始只是想验证自己的一个想法,任何整数都可以分解为素因子的乘积,那么只用素数来测试是否会快一些呢?
这是我写的。用@primes来保存找到的素数。
测试:
结果出乎意料:
当产生500个素数时,我的要慢一些。伤心了!
user system total real
0.453000 0.000000 0.453000 ( 0.453000)
0.360000 0.000000 0.360000 ( 0.359000)
当产生5000个素数时,我的竟然快了近三倍!!!
user system total real
11.141000 0.000000 11.141000 ( 11.312000)
33.390000 0.000000 33.390000 ( 33.688000)
忍不住测了一下不同数值下的结果。拷了半天机,得出下面这张图(生成10到2000以内的素数):(横坐标单位为10,纵坐标单位为秒)
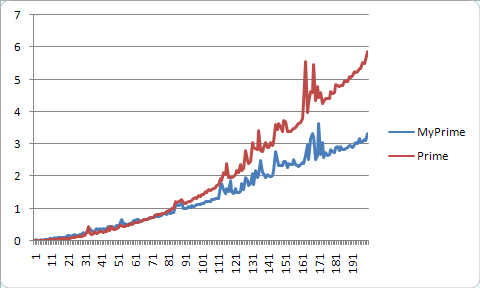
狂笑不止……

由于自己的Prime类在渐进性能上远远超过mathn库的Prime,于是很想看看人家是怎么写的(居然可以写得这么慢:))。但翻出来花了好长时间才看懂,他居然只用了加法,amazing!!!
其实总的思路都是只用素数作为测试的因子。他维护了两个数组@primes和@counts(这名字取得太烂俗了)和已经找到的最大素数@seed(也就是@primes[-1])。显然,@primes存在已经找到的全部素数,而@counts中的第i个元素存的是@seed与第i个素数的最小公倍数。比如,@primse是[2,3,5,7],@seed是7,那么@counts就是[8,9,10,14](暂不考虑最后一个),即[2×4,3×3,5×2,7×2]。
我照这个思路验证了一下。只是为了验证,性能完全不行,生成前100个素数时,性能差了130倍。
据说Ruby 1.8 的mathn库是业余人士写的,1.9 的就快一点了(嗯,很有兴趣)
可见,同一思路的不同实现间的差别还是可以很大的。另外,再次见证了算法的提高比其他一切的优化更经济。
P.S.: 去搜了搜有关素数生成方面的资料,发现了Atkin 筛法 (Atkin 的论文 )和据说更快的Zakiya 筛法 。
还可以看看Bob大叔写的性能调优——永远超乎想象(不愧是大神,随手写的都能这么快。当然生成素数的方式不一样)。















 1988
1988

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









