







统计学习方法笔记–第二章感知机perceptron
感知机是二类分类的线性分类算法模型
1.模型
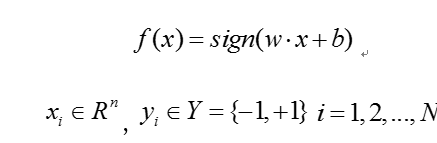
其中w为权值,b为偏置。 为向量内积, 对应于超平面,w是法向量,b是截距
如果输入数据集X是线性可分的,那么感知机的任务就是寻找超平面。
2.学习策略
数据集的线性可分性
损失函数的两个选择是误分类点到超平面的总数,另一个选择是误分类点到超平面的总距离。
距离是
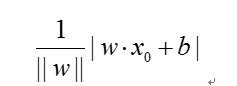
损失函数
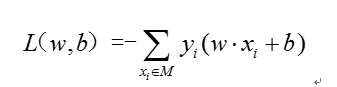
M为误分类点的集合。在假设空间里选择是损失函数最小的模型参数 。
3、算法
感知机学习问题转化为求解损失函数最优化问题。最优化方法是下降梯度法,并证明算法的收敛性。
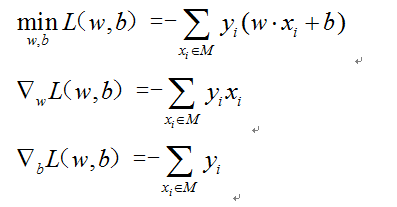
随机梯度下降,每次迭代时随机选取一个误分类点使其梯度下降
当数据集线性可分时,可以证明算法收敛,即可以通过有限次迭代找到完全正确分离的超平面
如果要从众多解中得到最优解,就引出后面的支持向量机
两种形式:
原始形式和对偶形式
原始形式算法:
• 几何解释:当一个实例点被误分类时,调整参数w,b 使得分离平面向该误分类点的一侧移动,以减少该误分类点与超平面间的距离,直至超平面越过所有的误分类点以正确分类。
• 感知机学习算法由于采用不同的初值或者误分类点选取顺序的不同,最终解可以不同
• 训练集线性可分时,算法收敛,但是算法存在许多解,既依赖于初值,又依赖于误分类点的选择顺序。 当训练集线性不可分时,感知机学习算法不收敛。迭代结果会发生震荡。
对偶形式算法:
• 与原始形式一样,感知机学习算法的对偶形式也是收敛的,且存在多个解。
如何理解对偶形式
每一个线性规划问题,我们称之为原始问题,都有一个与之对应的线性规划问题我们称之为对偶问题。原始问题与对偶问题的解是对应的
很多凸优化问题都是通过解对偶问题来求解的,线性规划只是其中一个特例而已。
function [ w,b ] = originalStyle( trainingSet,studyRate )
%trainingSet是一个m*n维的矩阵,
%选取的初始值w0,b0
w=0;
b=0;
count=0; %每一次正确分类个数
iterationCount=0; %迭代次数
fprintf('迭代次数\t\t误分类点\t\t权值w\t\t偏置b\t\n');%输出结果标题
while count~=size(trainingSet,2)
count=0;
for i=1:size(trainingSet,2)
count=count+1;
%如果yi*(w*x+b)<=0,则对w和b进行更新
if trainingSet(1,i)*(w'*trainingSet(2:size(trainingSet,1),i)+b)<=0
w=w+studyRate*trainingSet(1,i)*trainingSet(2:size(trainingSet,1),i);
b=b+studyRate*trainingSet(1,i);
iterationCount=iterationCount+1;
count=count-1;
fprintf('\t%u\t',iterationCount);
fprintf('\t\t%u\t',i);
fprintf('\t(%2.1g,%2.1g)',w);
fprintf('\t\t%4.1g\n',b);
end
end
end
end















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









