









Paper link: https://arxiv.org/abs/2402.03300
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Pre-training base model
Collect large-scale high-quality domain-related dataset
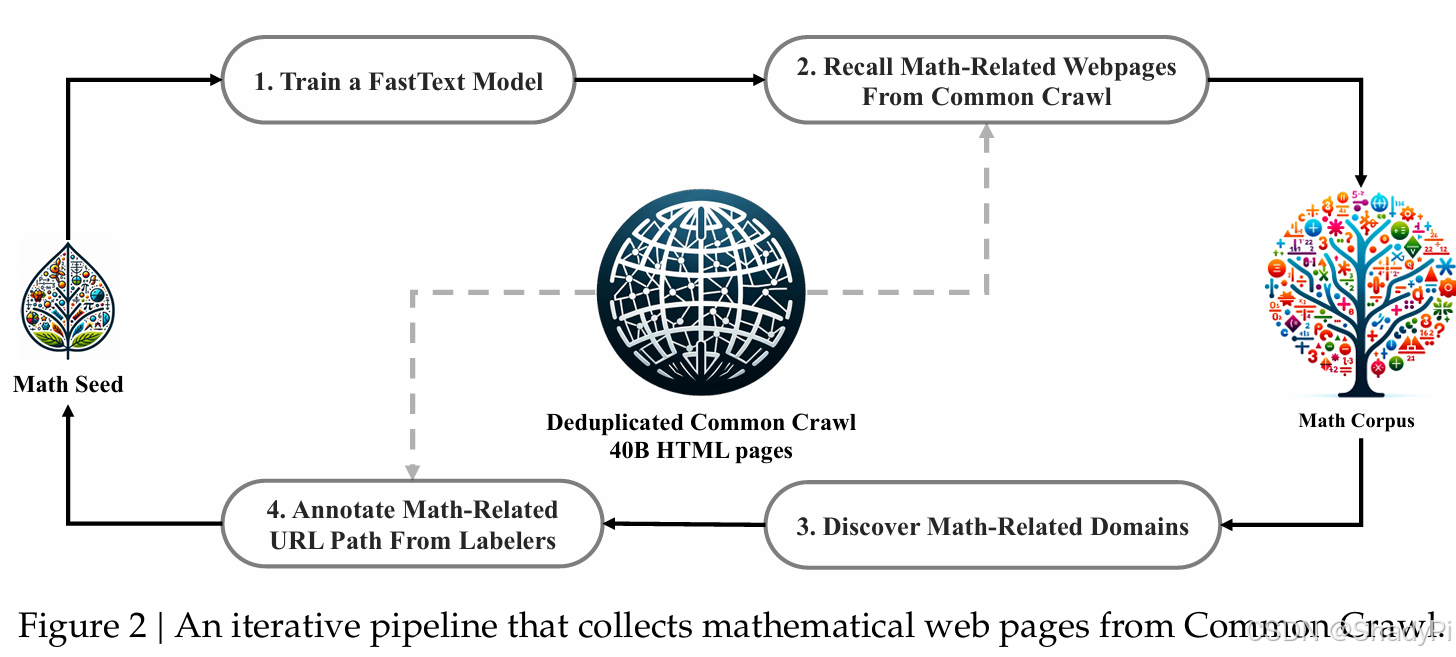
- First Iteration
Seed corpus: a small but high-quality collection of domain-related dataset
Train a simple embedding model (fastText) based on the seed corpus (OpenWebMath, 500K positive samples). In the first iteration, use the trained embedding model to recall samples similar to seed corpus from a much larger dataset (Common Crawl, 40B HTML web pages). All collected samples are ranked according fastText score, then only keep the top 40B tokens data. - Manual annotation, Embedding model optimization and Collection iteration
Because Common Crawl is a web page dataset, where each sample is corresponded to a URL, the authors organize the data into several groups based on base URL (e.g., mathoverflow.net), then manually annotate the URLs associated with mathematical content (e.g., mathoverflow.net/questions) within groups that more than 10% of content is collected in the first iteration.
This way, more sample is recalled and added into the high-quality dataset. Then, using the enhanced dataset, an improved fastText embedding model is trained to do better recall in the next iteration.
After four iterations of data collection, the authors end up with 35.5M mathematical web pages, totaling 120B tokens. - Decontamination
Any text segment containing a 10-gram string that matches exactly with any sub-string from the evaluation benchmarks is removed from our training corpus.
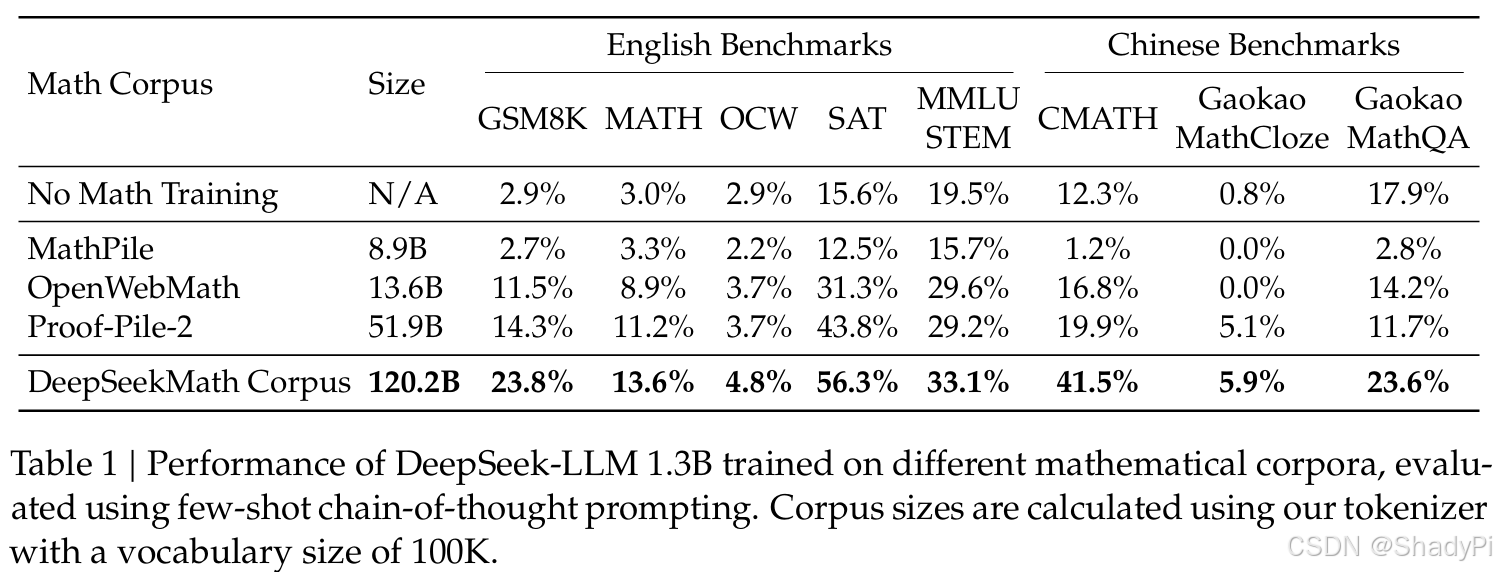
To evaluate the quality of collected data, the authors trained a 1.3B LLM on different corpus and compared the LLM’s performance. It turns out that DeepSeekMath Corpus gains a significant improvement compared with its seed corpus OpenWebMath, involving a lot of high-quality and multilingual data from Common Crawl.
Train base model
DeepSeekMath-Base 7B is initialized with DeepSeek-Coder-Base-v1.5 7B, as it is noticed that starting from a code training model is a better choice compared to a general LLM.
The distribution of the data is as follows: 56% is from the DeepSeekMath Corpus, 4% from AlgebraicStack, 10% from arXiv, 20% is Github
code, and the remaining 10% is natural language data from Common Crawl in both English and Chinese.
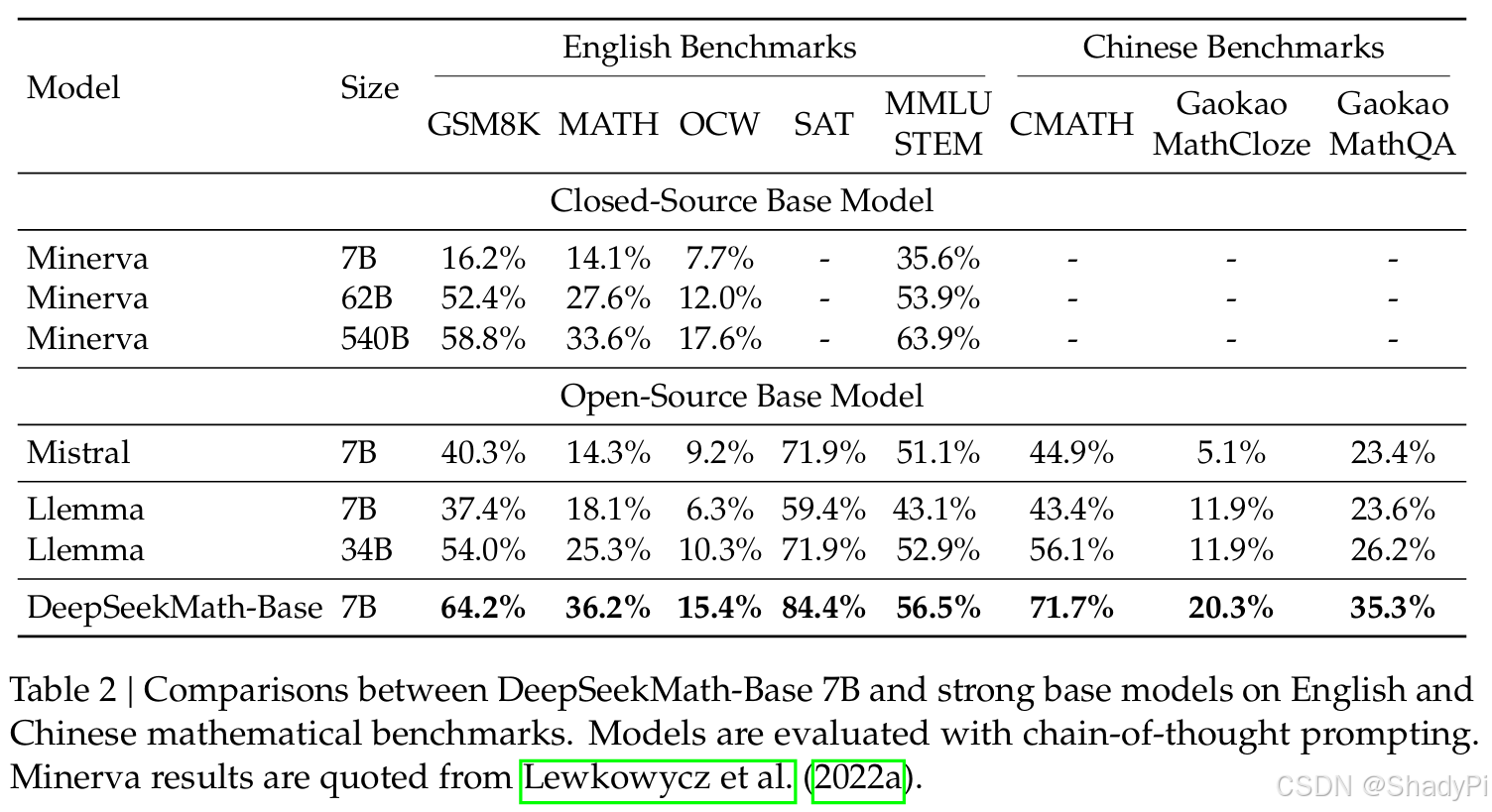
The DeepSeekMath-Base 7B shows outstanding mathematic performance and outperforms Llemma 34B on mathematic problem solving with step-by-step reasoning/tool use and formal mathematics.

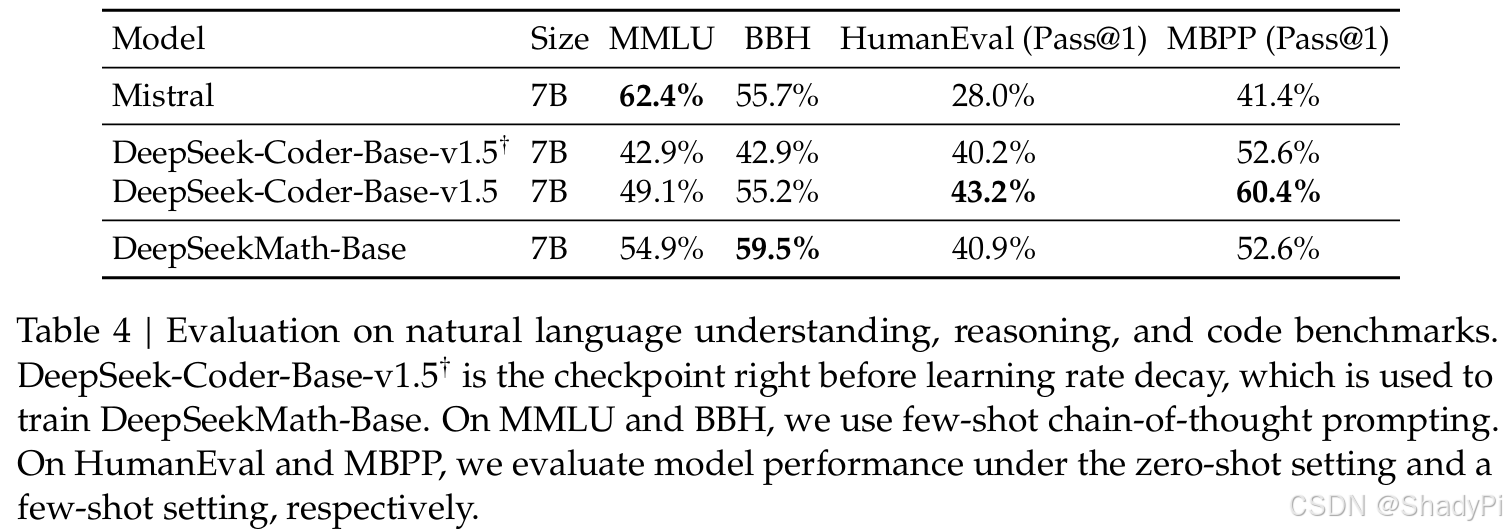
For other general natural language tasks, DeepSeekMath-Base 7B maintains comparable performance to initial DeepSeek-Coder-Base-v1.5. And it outperforms Mistral 7B on natural language reasoning and coding.
Supervised fine-tuning instruct model
Data collection
Manually annotated mathematical instruction-tuning dataset covering English and Chinese problems, where problems are paired with
solutions in chain-of-thought (CoT), program-of-thought (PoT), and tool-integrated reasoning format. The total number of training examples is 776K.
Fine-tune instruct model
Based on DeepSeekMath-Base 7B, DeepSeekMath-Instruct 7B is fine-tuned with the data collected above. Training examples are randomly concatenated until reaching a maximum context length of 4K tokens.
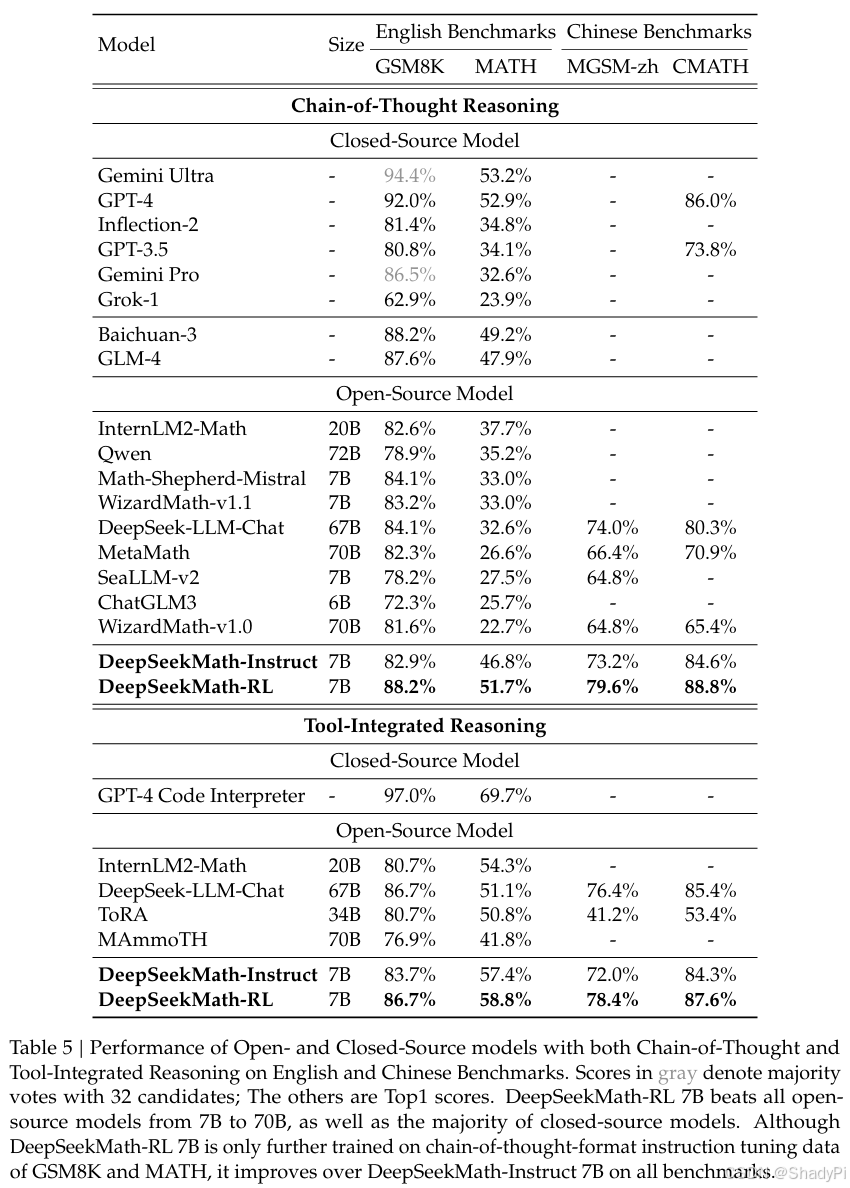
Under the evaluation setting where tool use is disallowed, DeepSeekMath-Instruct 7B demonstrates strong performance of step-by-step reasoning. Under the evaluation setting where models are allowed to integrate natural language reasoning and program-based tool use for problem solving, DeepSeekMath-Instruct 7B approaches an accuracy of 60% on MATH, surpassing all existing open-source models.
Reinforcement Learning
GRPO
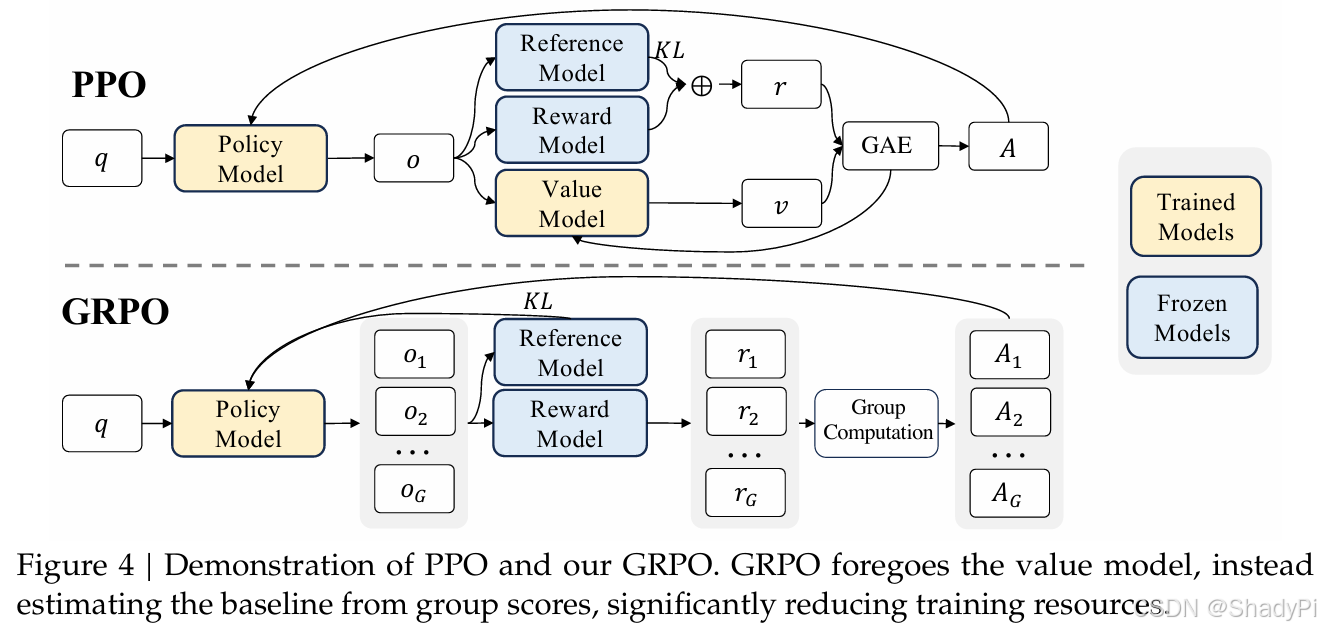
In PPO, there are 2 trainable models, Policy Model and Value Model, where Value Model is usually of the similar size to Policy Model. So, it would be very expensive to train these 2 models together.
Another challenge is that the Reward Model, which is trained in RLHF, is only able to give reward based entire response. It differs from the idea of PPO that give reward and value estimation based each token, resulting in difficulty to train the Value Model.
To know more about PPO, see https://blog.csdn.net/ShadyPi/article/details/145379220.
To overcome the challenge above, GRPO is proposed. GRPO does not need a Value Model to estimate future rewards. In contrast, it computes advantage based on reward of multiple sampled outputs
J
G
R
P
O
(
θ
)
=
E
q
∼
P
(
Q
)
,
{
o
i
}
i
=
1
G
∼
π
θ
o
l
d
(
O
∣
q
)
[
1
G
∑
i
=
1
G
1
∣
o
i
∣
∑
t
=
1
∣
o
i
∣
{
min
[
π
θ
(
o
i
,
t
∣
q
,
o
i
,
<
t
)
π
θ
o
l
d
(
o
i
,
t
∣
q
,
o
i
,
<
t
)
A
^
i
,
t
,
clip
(
π
θ
(
o
i
,
t
∣
q
,
o
t
,
<
t
)
π
θ
o
l
d
(
o
i
,
t
∣
q
,
o
i
,
<
t
)
,
1
−
ϵ
,
1
+
ϵ
)
A
^
i
,
t
]
−
β
D
K
L
[
π
θ
∥
π
r
e
f
]
}
]
\mathcal{J}_{GRPO}(\theta) = \mathbb{E}_{q\sim P(Q),\{o_i\}_{i=1}^G\sim\pi_{\theta_{old}}(O|q)}\\ \left[ \frac{1}{G}\sum_{i=1}^G\frac{1}{|o_i|}\sum_{t=1}^{|o_i|} \left\{ \min \left[ \frac{\pi_\theta(o_{i,t}|q,o_{i,<t})}{\pi_{\theta_{old}}(o_{i,t}|q,o_{i,<t})}\hat{A}_{i,t}, \text{clip}\left( \frac{\pi_\theta(o_{i,t}|q,o_{t,<t})}{\pi_{\theta_{old}}(o_{i,t}|q,o_{i,<t})}, 1-\epsilon, 1+\epsilon \right)\hat{A}_{i,t} \right] - \beta\mathbb{D}_{KL}[\pi_\theta\Vert\pi_{ref}] \right\} \right]
JGRPO(θ)=Eq∼P(Q),{oi}i=1G∼πθold(O∣q)
G1i=1∑G∣oi∣1t=1∑∣oi∣{min[πθold(oi,t∣q,oi,<t)πθ(oi,t∣q,oi,<t)A^i,t,clip(πθold(oi,t∣q,oi,<t)πθ(oi,t∣q,ot,<t),1−ϵ,1+ϵ)A^i,t]−βDKL[πθ∥πref]}
It looks very complicated! However, there are few things new compared to PPO. Actually, the main part
min
(
⋯
)
\min(\cdots)
min(⋯) keeps the same as PPO, only changing the method to compute advantage
A
^
i
,
t
\hat{A}_{i,t}
A^i,t. For each sample
o
i
o_i
oi in sampled group, a KL divergence is added. (In PPO, a KL penalty is implicitly added into the rewards). Then the overall objective is the average objective of each sample in group.
KL divergency
D
K
L
[
π
θ
∥
π
r
e
f
]
\mathbb{D}_{KL}[\pi_\theta\Vert\pi_{ref}]
DKL[πθ∥πref] is defined as
D
K
L
[
π
θ
∥
π
r
e
f
]
=
π
r
e
f
(
o
i
,
t
∣
q
,
o
i
,
<
t
)
π
θ
(
o
i
,
t
∣
q
,
o
i
,
<
t
)
−
log
π
r
e
f
(
o
i
,
t
∣
q
,
o
i
,
<
t
)
π
θ
(
o
i
,
t
∣
q
,
o
i
,
<
t
)
−
1
\mathbb{D}_{KL}[\pi_\theta\Vert\pi_{ref}] = \frac{\pi_{ref}(o_{i,t}|q,o_{i,<t})}{\pi_\theta(o_{i,t}|q,o_{i,<t})}-\log\frac{\pi_{ref}(o_{i,t}|q,o_{i,<t})}{\pi_\theta(o_{i,t}|q,o_{i,<t})}-1
DKL[πθ∥πref]=πθ(oi,t∣q,oi,<t)πref(oi,t∣q,oi,<t)−logπθ(oi,t∣q,oi,<t)πref(oi,t∣q,oi,<t)−1
which is guaranteed to be positive.
The advantage
A
^
i
,
t
\hat{A}_{i,t}
A^i,t is the normalized reward, which is defined as
A
^
i
,
t
=
r
i
,
t
−
mean
(
{
r
1
,
t
,
r
2
,
t
,
⋯
,
r
G
,
t
}
)
std
(
{
r
1
,
t
,
r
2
,
t
,
⋯
,
r
G
,
t
}
)
\hat{A}_{i,t}=\frac{r_{i,t}-\text{mean}(\{r_{1,t},r_{2,t},\cdots,r_{G,t}\})}{\text{std}(\{r_{1,t},r_{2,t},\cdots,r_{G,t}\})}
A^i,t=std({r1,t,r2,t,⋯,rG,t})ri,t−mean({r1,t,r2,t,⋯,rG,t})
In the paper, the author defines another 2 variants of GRPO. However, in DeepSeek-R1, it turns out that this “Outcome Supervision RL with GRPO” works best.
Train & Test
The training data of RL are chain-of-thought-format questions related to GSM8K and MATH from the SFT data, which consists
of around 144K questions. The authors exclude other SFT questions to investigate the impact of RL on benchmarks that lack data throughout the RL phase.
The performance surpasses that of all open-source models in the 7B to 70B range, as well as the majority of closed-source models.
Despite the constrained scope of its training data, it outperforms DeepSeekMath-Instruct 7B across all evaluation metrics, showcasing the effectiveness of reinforcement learning



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











