







Hadoop伪分布式配置
参考:http://www.powerxing.com/install-hadoop/
step1. 下载Hadoop2.6.0版本,解压到/usr/local/hadoop
step2. 修改配置文件(配置文件地址:/usr/local/hadoop/etc/hadoop)
1).core-site.xml
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>2). hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/data</value>
</property>
</configuration>3). hadoop-env.sh
export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_71
step3. 格式化NameNode
$/usr/local/hadoop/bin/hdfs namenode -format
#$./bin/hdfs namenode -format
step4. 开启守护进程
$/usr/local/hadoop/sbin/start -format
#$./bin/hdfs namenode -format
$jps #查看是否启动成功成功时启动的进程: NameNode, DataNode, SecondaryNameNode
访问http://localhost:50070 可查看NameNode和DataNode信息
Hadoop伪分布实例
1). 单机测试
# ./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.0.jar grep ./input ./output/* 'dfs[a-z.]+'
#cat ./output/*
hadoop默认不覆盖结果文件,再次运行前先将./output删除
2).分布式实例测试,数据需从HDFS读取
$./bin/hdfs dfs -mkdir -p /user/hadoop #在HDFS中创建用户目录
$./bin/hdfs dfs -mkdir /user/hadoop/input #创建input,此处使用绝对路径,相对路径input需要使用hadoop用户
$./bin/hdfs dfs -put ./etc/hadoop/*.xml input
$./bin/hdfs dfs -ls input #查看文件列表
$./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.0.jar grep /user/hadoop/input /user/hadoop/output 'dfs[a-z.]+'
HDFS命令:
//创建目录
$./bin/hdfs dfs -mkdir -p /user/hadoop
//复制文件
$./bin/hdfs dfs -put ./etc/hadoop/*.xml /user/hadoop/input
//查看文件列表
$./bin/hdfs dfs -ls /user/hadoop/input
//查看文件
$./bin/hdfs dfs -cat output/*
//HDFS文件拷贝到本机 hdfs目录 本地目录
$./bin/hdfs dfs -get output ./output
//删除目录
$./bin/hdfs dfs -rm -r output关闭hadoop $./sbin/stop-dfs.sh
启动hadoop $./sbin/start-dfs.sh
//该命令启动Hadoop,仅仅启动了MapReduce环境,并没有启动YARN,因此没有JobTracker和TaskTracker。
配置YARN
修改配置文件mapred-site.xml
$mv ./etc/hadoop/mapred-site.xml.template ./etc/hadoop/mapred-site.xml编辑$vi /usr/local/hadoop/etc/hadoop/mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration> 编辑$vi /usr/local/hadoop/etc/hadoop/yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>启动yarn
$./sbin/stop-dfs.sh //关闭mp
$./sbin/start-dfs.sh //打开mp
$./sbin/start-yarn.sh //打开yarn
$./sbin/mr-jobhistory-daemon.sh start historyserver //打开历史服务器,才能在web中查看任务运行情况$jps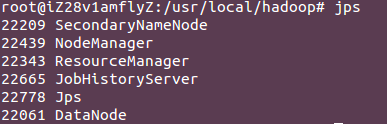
开启yarn之后,多了NodeManager和ResourceManager两个后台进程















 110
110

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









