









业务背景
我在一家打车公司上班,运营大佬们认为不同用户在不同场景下有不同打车需求,设计出来很多子品类。于是我们组会承接这样一类需求:计算用户不同品类的各种实时单量,如:快车呼单量、拼车完单量。
这样的需求,一般处理流程是这样的:
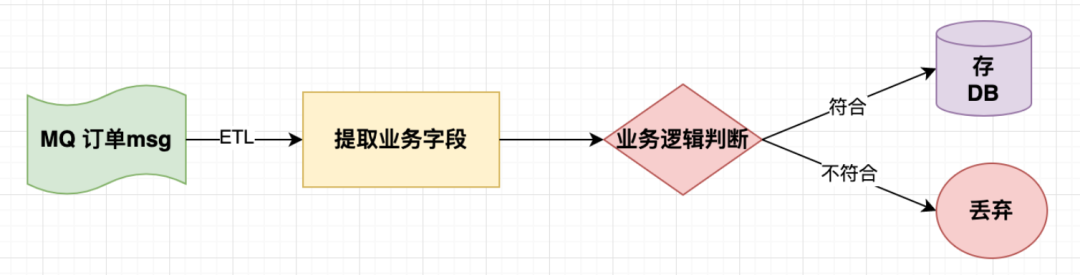
描述一下这个图:用户在订单流转状态关键节点发生动作时,系统会发一个MQ消息让供其他系统消费。其他系统通过一个明确的据口径判断这条msg是否符合当前业务逻辑,进而存db或是丢弃。比如一个需求要计算:拼车完单量,一个靠谱的拼车rd告诉你口径是:
If aa.bb.cc == 1 // 说明是多车型发单
Unmarshal(bb.cc.ee)
看type是否为 4
else // 单车型发单
Unmarshal(bb.cc.ff)
看type是否为 4
(type = 4 的是拼车)
你对着这个口径,订阅mq,写数据提取和订单判断的逻辑,整个流程写代码1小时,自测一小时,由于你们机器太多,上线花了1整天,整体研发效率还行。
第二天,产品又给你提了个需求,想计算拼车的发单量,你又去找对应业务线的开发同学寻求一个取数口径,然后重复上面的过程。
第三天,产品上线了,效果不错,数据涨了3个点,老板非常开心,在周会上让PM讲两句他的心路历程,PM同学重点感谢了老板的栽培,然后轻描淡写的说了产品的底层逻辑和关键抓手。而他的几个精明的同事都get到了抓手是你,于是连夜赶PRD,要求你这个抓手把他们负责品类的各种实时单量全给抓出来。
第四天,你崩溃了,因为你收到4个PM并行的8个单量需求,正当你奋笔疾书再次准备重复上述流程时,你睿智的老板告诉你这样做有不妥之处:来一个坑填一个萝卜是小农时代的做法,现在都21世纪了,时代变了,让你想一种通用解决方案,让系统走向工业时代!
你似懂非懂点了点头,查了各种CSDN、博客园、知乎、github,又在技术交流群各种@群里大佬有没有遇到这种场景。一番折腾后终于有了头绪,于是你高兴的向老板汇报:老板,我懂了,这个场景可以用JPATH + Expression Eval来解决!这样一来,再来新的需求只需要写在db里插入俩表达式就可以了,20个需求提过来也不用怕。
你的老板微笑着点了点头,看了一眼自己手上的劳力士,有意无意的晃了晃,说:小伙子很上道,自己也琢磨出解法了,赶紧设计方案,争取本周上线,尽快拿到业务结果,到时候升职加薪少不了你的!
实现方案
这个系统的核心需求有两点:
-
数据提取
-
规则判断
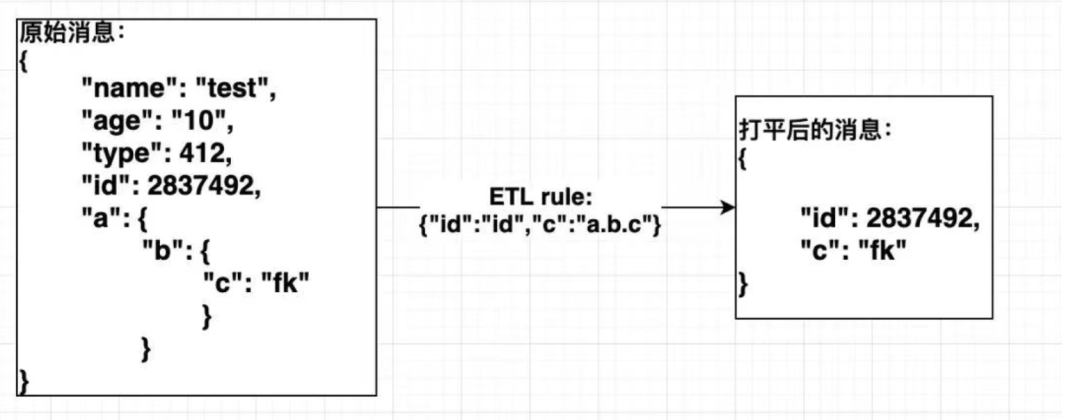
数据提取即ETL,把mq的msg中关键信息提取出来,提取之后可能还需要简单处理一下(比如msg中事件时间是timestamp,你想转化为RFC3339格式) ,这里可以用JPATH 做数据提取 (如果你写过爬虫,一定知道用xpath去提取HTML中的node消息,jpath就是json数据的提取规则)。配置一个ETL rule,如图所示:
然后是数据规则判断,即题目中提到的规则引擎,我们这里使用 开源库govaluate,比如上面拼车完单的例子,我们可以配置这样的规则:
cc == 1 ? ( in(4, ee)? 1:0 ) : ( ff ==4 ? 1:0)
govaluate会把这个表达式构建出一颗ast,然后输入参数进行求值(是不是回忆起来了编译原理?)。接下来让我们研究一下这个库~
govaluate介绍与使用注意
govaluate支持对C风格的算数/字符串的表达式进行求值。比如这些例子(例子来源于evaluation_test.go):
1. 100 ^ (23 * (2 | 5))
2. 5 < 10 && 1 < 5
3. (foo == true) || (bar == true) // foo、bar为变量
4. theft && period == 24 ? 60 // theft、period为变量
这个库几乎支持你能想象到的任何表达式,有兴趣可以去这个test文件。除此之外它支持拓展UDF, 你可以自己写一些函数支持你的定制业务逻辑,它还支持执行类方法,更多信息可以看README。
当我们需要使用它时,只需要这几行代码:
expression, err := govaluate.NewEvaluableExpression("foo > 0");
parameters := make(map[string]interface{}, 8)
parameters["foo"] = -1;
result, err := expression.Evaluate(parameters);
// result is now set to "false", the bool value.
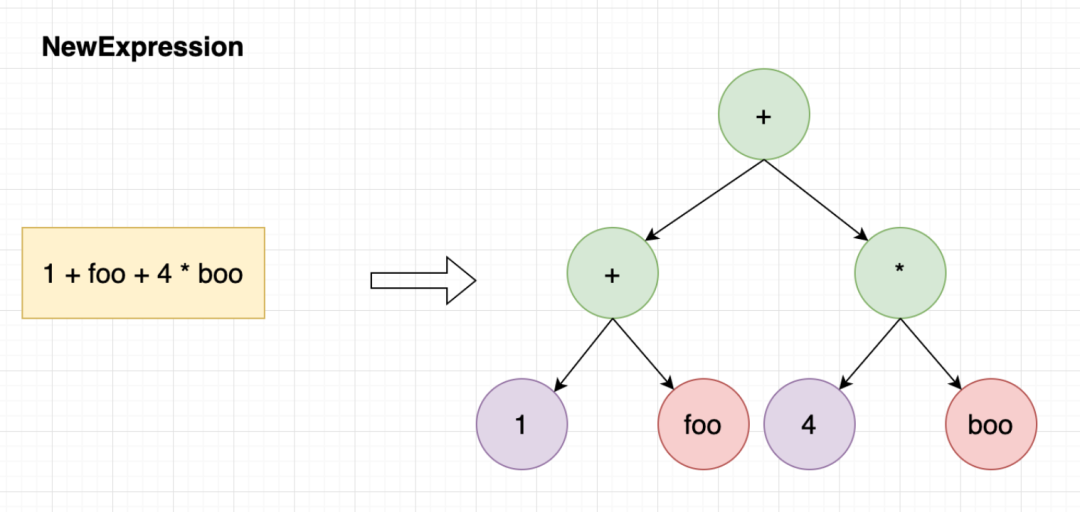
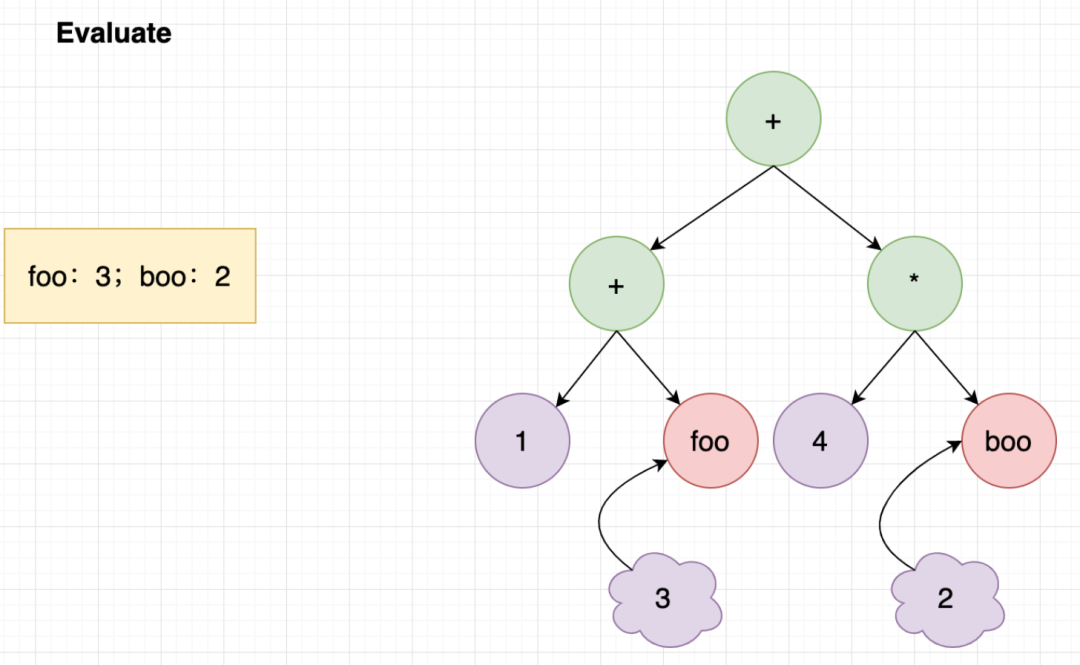
通过这个demo我们可以看到它的api被设计成了两步, 第一步NewEvaluableExpression的功能主要是把表达式拓展为一颗AST,Evaluate的主要功能是把用户参数填入ast求值。。举个例子:比如1 + foo + 4 * boo这个表达式,在两个阶段分别做的事情是这样:
那么生产项目代码中直接把这两步抄进去就可以了吗?显然不是。通过观察就可以发现, 第一步构造ast依赖的表达式其实是可以预先确定的,且表达式一般不会变化,没有必要用户每次传一个api就构造一颗ast然后求值。可以把表达式存入db,在项目启动or更新配置时加载到内存中, 比如搞一个map[string]*EvaluableExpression, 把不同表达式的ast进行cache,这样用户每次请求时只需遍历ast进行求值。
预编译所带来的收益很显著,尤其是在你表达式比较复杂的情况下。我对foo > 2? 1:0这个表达式分别做了现编译和预编译的benchmark,结果如下:
现编译
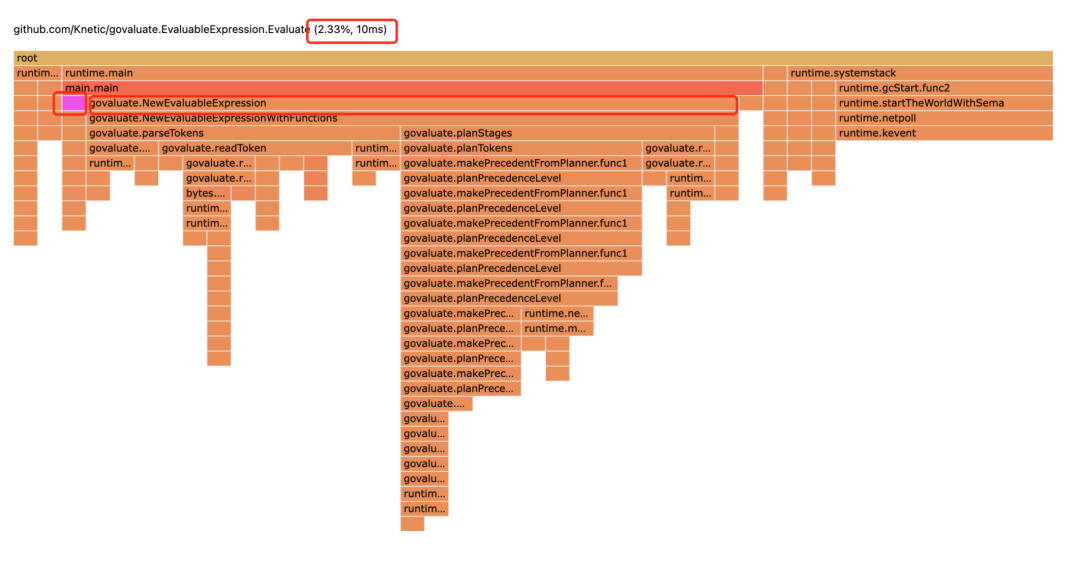
(现编译 构建ast占用62.3%的cpu开销,而eval只占2%)
预编译

(预编译省掉了构建ast的成本,节约了大量cpu资源) 建议大家如果使用这个库,有条件要用预编译版本。
govaluate 原理
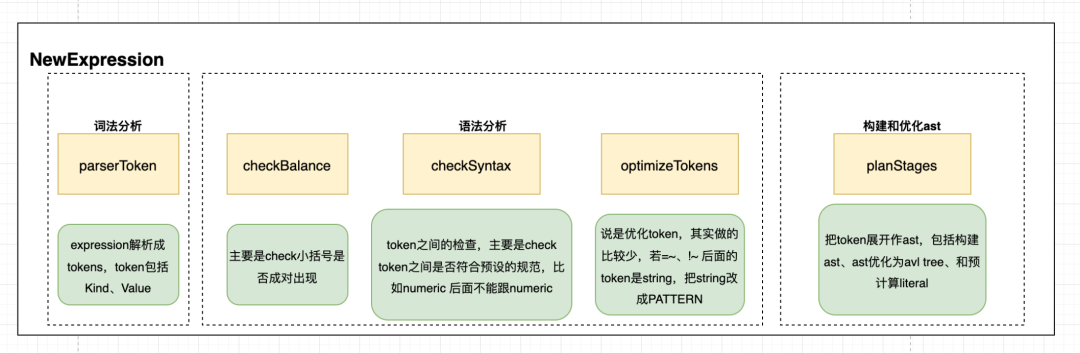
看起来govaluate很有意思, 接下来让我们挖一下它的源码。首先来看第一阶段,把表达式拓展为AST时的逻辑,我简单画了一张图:
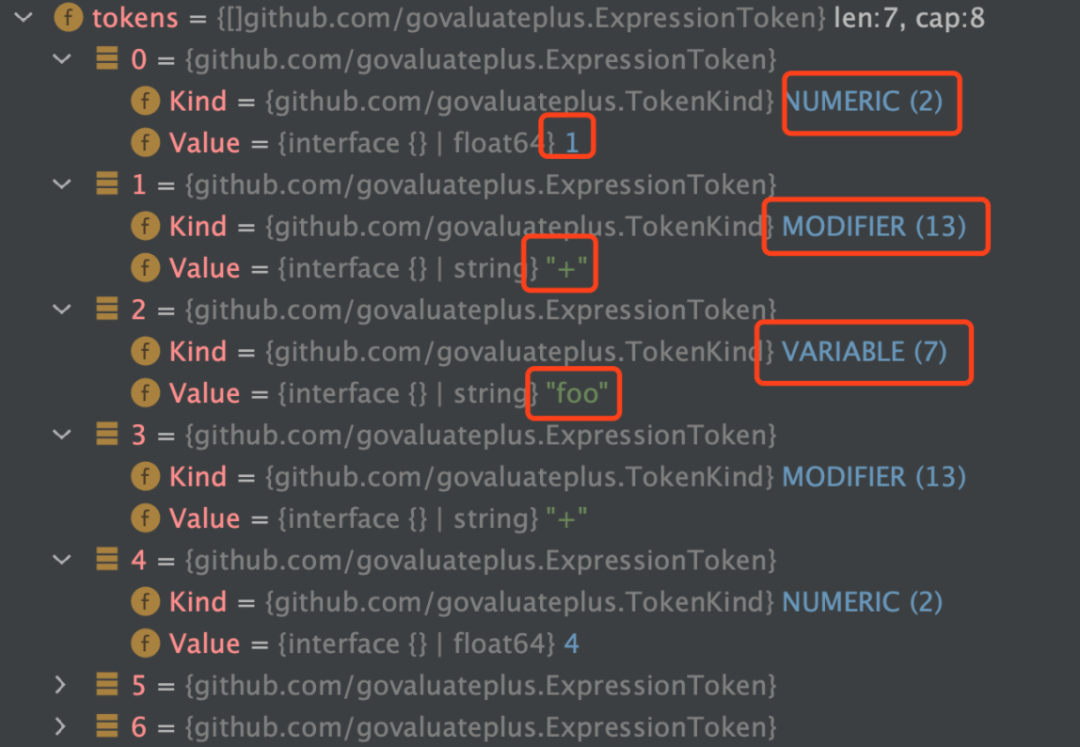
下面以1 + foo + 4 * boo为例,parserToken后,我们可以得到一堆token:
checkBalance没啥好说的,核心功能就看小括号是否成对出现:
![]()
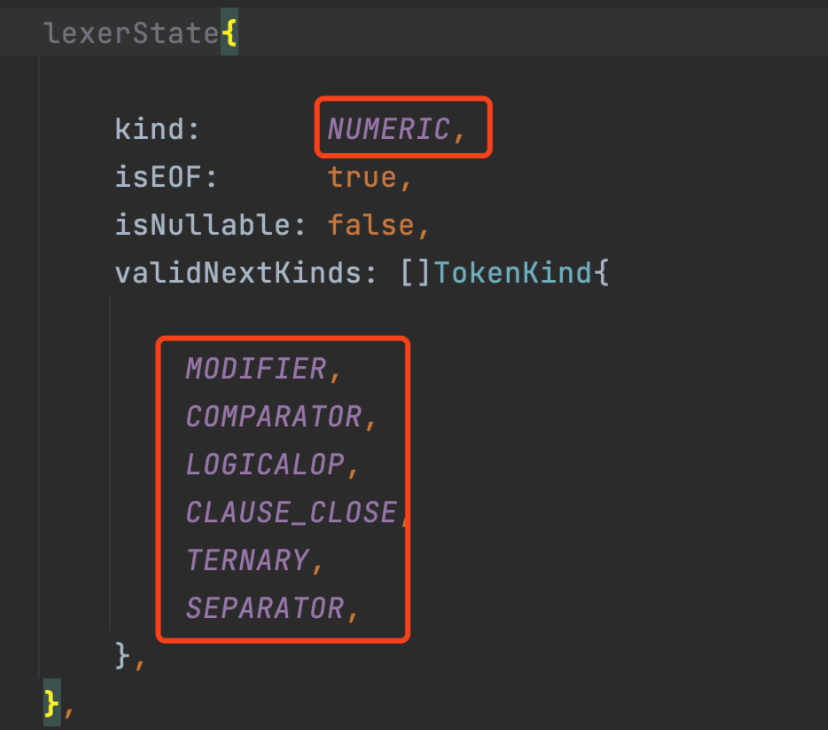
而checkExpressionSyntax阶段主要是check token之间是否符合预设规则,核心是这个函数:

这个函数会check当前的token是否是上一个token的合法值,合法值是预设的,比如NUMERIC的合法值是后面这些:
接下来的 optimizeTokens 函数没啥好说的,主要就是编译一下正则。
比较有意思的是planStages这个步骤。planStages这个大步骤内部大概分成了planTokens、reorderStages、elideLiterals这三个小步骤,下面来一一介绍:
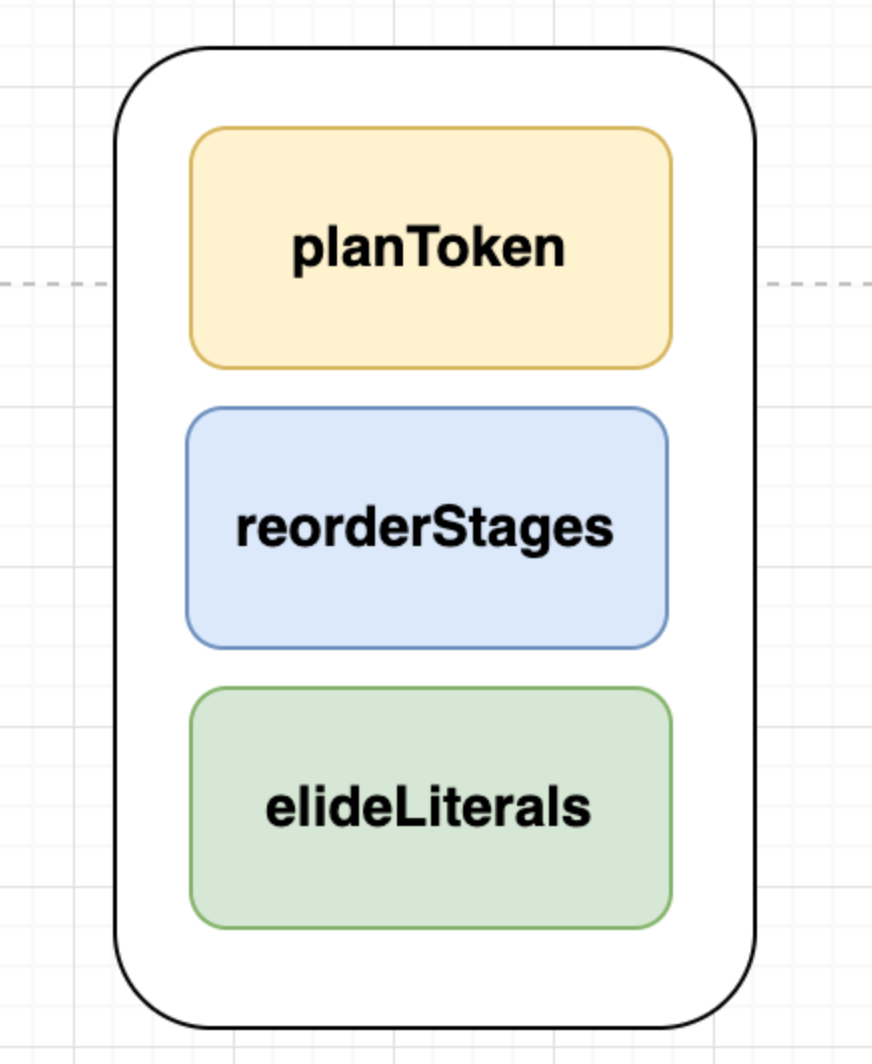
planTokens
这个函数写的让我大开眼界,首先它用func做不同运算符的优先级计算,原理是func接收struct作为参数,而参数中的next为这个函数连接的下一个优先级的func。
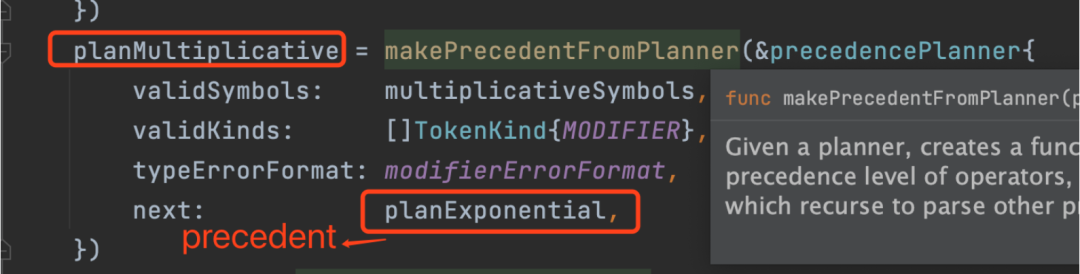
这个func优先级打印出来是这样的:
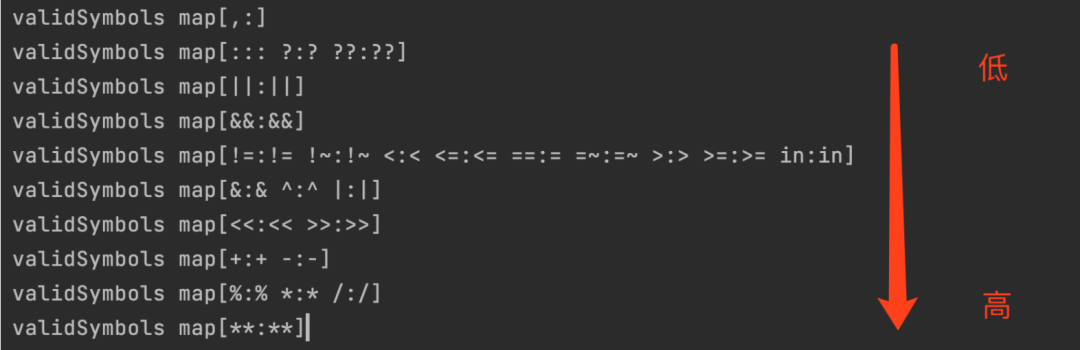
有了运算符优先级之后,对于具体的节点,会继续看节点类型,比如是func,accesser还是valueType,valueType的节点对于不同的详细类型也有不同策略,比如数字节点会构建一个Node,而小括号节点会直接parser下一个token来构建优先级更高的树。
对于不同的运算符,在这个函数链上会下沉构建出优先级比较高的节点,保证符合数学计算的规律。
reorderStages
这里主要把ast重排序,让ast由普通tree变成avl tree,树旋转的代码写的特别骚气,比如1 + foo + 4 * boo 这个表达式,planToken执行完后,会变成这样一颗树:
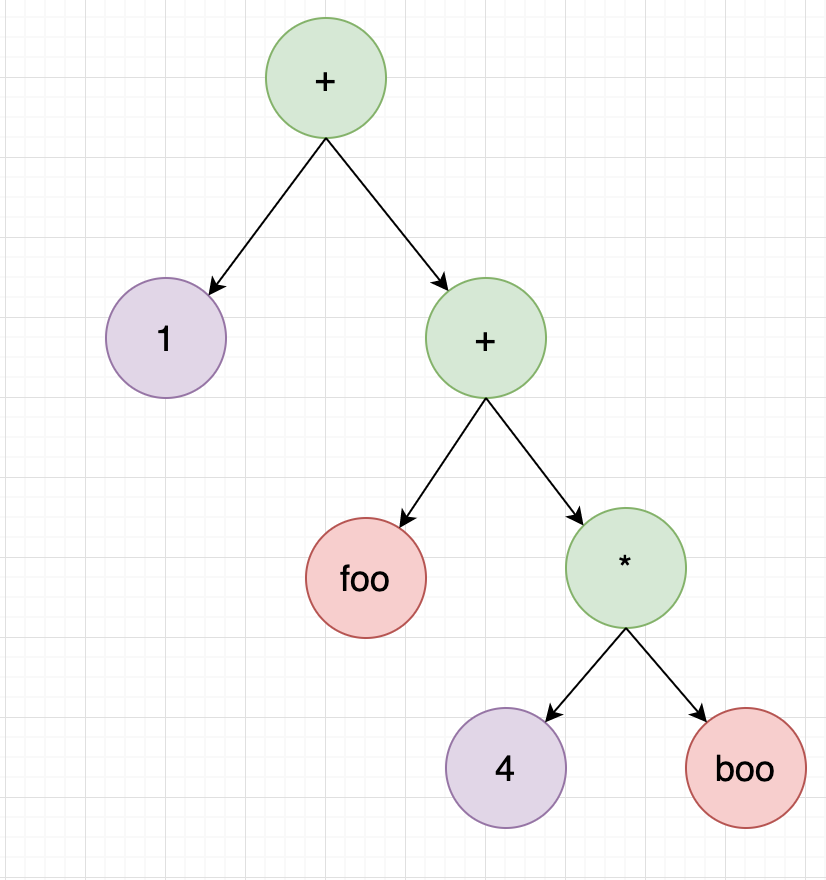
重排序的过程是把相同优先级的节点进行旋转,第一步是交换左右节点:
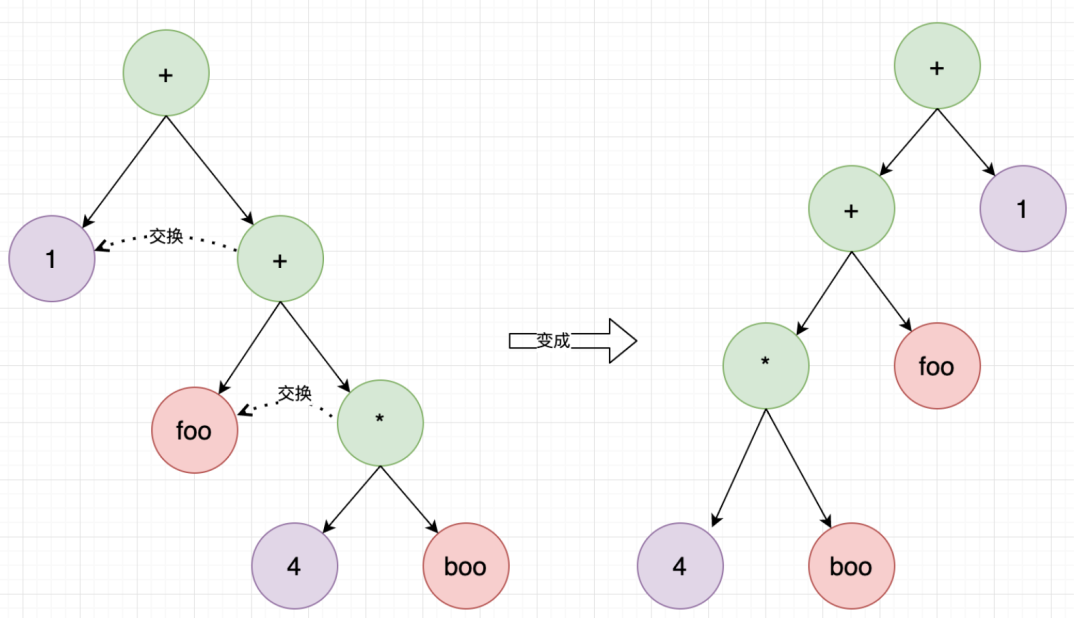
第二步是LL左旋:
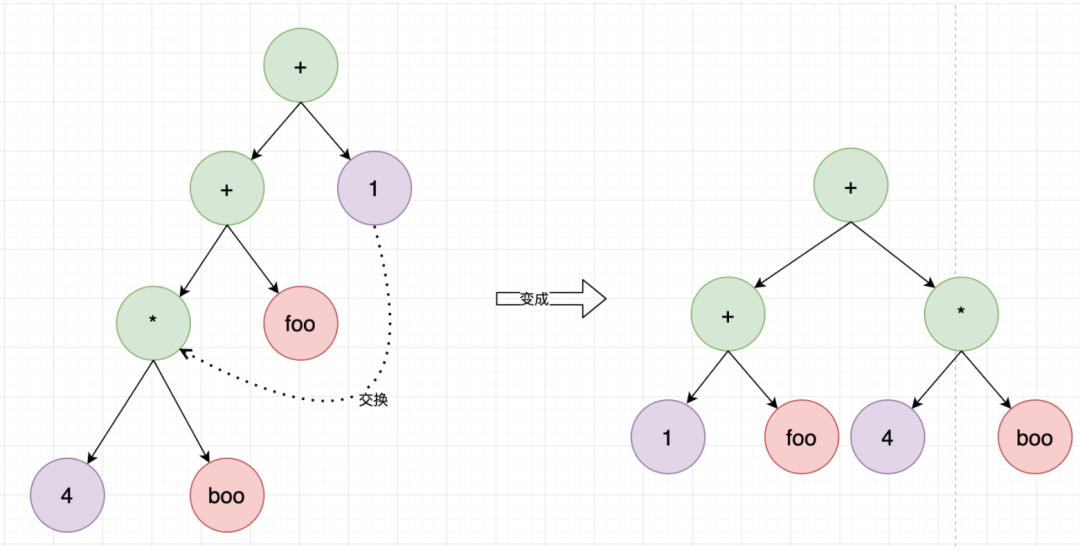
这样就平衡了,一个非常骚气的算法。
elideLiterals
这个步骤是看叶子节点是否为LITERAL,比如这棵树:
![]()
在这个阶段,各个子节点会进行dfs计算直接变成:
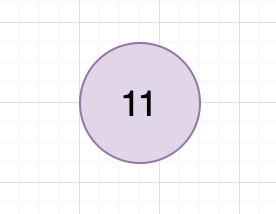
至此第一阶段的逻辑梳理完毕。而第二个阶段Evaluate的主要功能是把用户参数填入ast,进行求值。这个过程比较简单,本文不在赘述。
govaluate 不足
govaluate 看起来很美好,真的是这样吗?其实不然,这个项目最后一次commit是2017年,距今已经6年了。我们在使用期间也发现了很多小bug和代码优美度欠缺的地方。下面来简单列举几个:
弱类型
govaluate所有数字类型都是被解析为float64进行计算的,这么玩写代码爽了,但是当你用1+2+9做表达式时,可能会得到一个类型为fload64的interface{}结果。

函数限制
govaluate的函数有的返回值无法继续做运算。比如这个case:
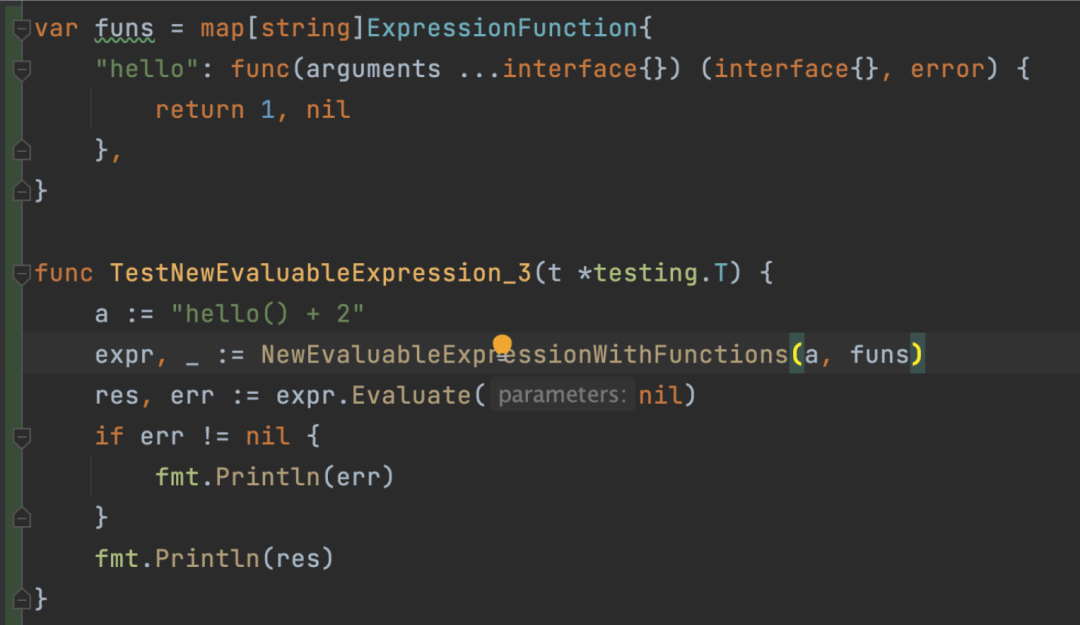
看起来没有任何问题,但是执行会报错:

参数会去除转义符
比如这段代码:
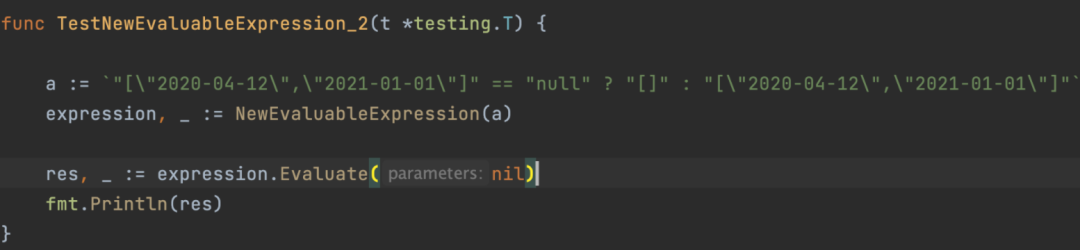
理论上结果应该含有转义符,实际上结果是:

实际上是这段代码搞的鬼,代码比较简单,就不解释了。

奇奇怪怪的代码
-
this关键字:这个就不举例子了,这个库里所有方法的接收者都是this,被官方建议熏陶过的我,看的我着实蛋疼...
-
双重否定表肯定:token解析阶段有这样的代码,不知道作者为啥要搞个双重否定,我的话,会用一个
isQuote代替。 -

govaluate改进
作为一个17年后就没更新过的项目, 也不知道作者还会不会维护。业务发展是不等人,govaluate对于我们服务来说并不能满足需求,很多时候用起来比较别扭,所以我基于我们的场景对于govaluate做了一些定制改造。我个人还是非常喜欢这个库的,于是把代码fork了一份,加了个eplus后缀,改造了上面那几个匪夷所思的问题。并加了个比较定制化的feature:type promotion。
这个听起来比较唬人, 其实就是支持更弱类型的表达式运算,比如我的库支持:'2' -1, '4' * 3,要支持这种功能,核心需要改两种地方:
-
第一种地方是typeCheck。比如subStage会check两个字节点必须是float64类型, 我们要支持string operator num, 可以把typeCheck扩大为可以是chek node是否为 floatOrStr。
-
第二种地方是OpeatorOperate。前面我们把String类型也放进来让它支持计算了,但是在go里str和float终究是无法计算的, 所以到了计算阶段需要做一个type promotion,即把string类型转化为数字类型之后再计算。
总结与反思
总结
govaluate在我心中还是有一些不完美的地方,我们这里用它也是因为项目初期就引入了这个库,在大量的线上用例使用后要迁移这个库成本巨大, 对于用的不爽的地方只能改了。如果读者朋友有需求, 可以看一下市面上其他的表达式开源库, 比如gval。当然,如果你的场景比较复杂, 需要很多if else 或者for循环,那简单的规则引擎可能满足不了你的需求,此时可以考虑内嵌个更完整的脚本库或者嵌入lua, 不过这样就更复杂了, 慎重考虑把这样的东西直接放在db里面, 后期不好维护。
反思
govaluate这个库对我有很多启发,最主要就是表达式的预编译可以节省大量CPU开销,组内某个项目目前的运行方式是随着请求现编译,构建执行计划dag图,理论上如果能预编译,请求到来只是对于对应param访问存储,可以节省大量CPU开销。
跳脱出govaluate本身,我们系统选择JPATH + Expr做数据提取和条件描述做需求,本质上是因为这边的mq数据是JSON格式,JSON有一定的局限性,描述数据没啥问题,但是描述条件就比较困难了,理论上如果用XML这种技能描述条件,又能描述数据的交互形式,那我们可能会构建一个完全不同的系统。














 1600
1600











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









