






规则引擎是什么
规则引擎,规则引擎是企业数字化转型升级过程中非常必要的软件工具,是一种能够自动执行一定条件下的预设逻辑的技术,可以帮助企业在收到数据或事件时自动触发相关业务规则,其主要优势如下:
- 易于维护与更新:规则引擎可以使业务规则与系统代码分离,从而降低维护和更新的难度。通过更新规则库或配置文件中的规则,可以快速地修改业务逻辑和规则变化。
- 增强应用程序的准确性和效率:规则引擎能够处理复杂和动态的规则,可以有效地提高应用程序的准确性和效率。通过使用规则引擎,可以帮助用户快速解决复杂的业务问题和数据分析。
- 支持可视化和可管理性:规则引擎可以通过图形用户界面和数据可替代性,可以更好地管理规则库和规则的版本控制。
- 加快应用程序的开发和部署:规则引擎可以提高开发效率和开发质量,降低测试和维护成本,从而提高企业效率和效益。
规则引擎常见的使用场景
- 金融行业:可以用于金融机构的反欺诈、风险评估、交易监控等场景,在金融风险管控和管理中发挥重要作用。
- 电子商务:可以应用于电商平台的个性化推荐、营销策略、订单分配等方面,提高运营效率和用户体验。
- 物流领域:可以应用于物流配送中的运输路径规划、优先级分配、异常处理等场景,使物流运营更加高效和准确。
- 制造业:可以应用于制造业中的产品配置、交互品质控制、工艺优化等方面,提高生产效率和产品质量。
- 保险行业:可以用于保险理赔案件的处理和调度,自动判断和审批理赔,提高理赔效率和客户满意度。
综上所述,规则引擎具有众多的好处和优点,并且可以应用的领域广泛。通过对复杂的业务逻辑和流程进行自动化处理,提高了业务处理效率和准确性,减少了人工处理的时间和成本。同时,规则引擎的灵活性和可扩展性也能够满足不同领域和场景的业务需求。我们以一款在大金融行业中非常活跃的规则引擎(JVS-Rules)为例,看看其相关介绍吧。
JVS-Rules基础介绍
规则引擎是基于JVS逻辑引擎构建的规则引擎,将JVS低代码开发平台的逻辑引擎简化,交互优化,从而形成侧重于金融风控、场景规则计算、在线决策的JVS-Rules。规则引擎侧重于规则判断,主要用于风控决策、规则过滤、行为评分等场景,项目采用spring cloud+vue构建,支持在线的变量加工、界面拖拽、在线测试等多种功能。包含完整的前后端。规则引擎主要用于金融风控、营销、计息等各种场景。
项目特点
- 纯java开发,采用微服务作为基础脚手架,稳定性与通用性有保障
- 易用性,有良好的界面交互体验,采用类excel函数的使用方式,对变量加工非常简单高效
- 扩展性,基于JVS基础底座开发,可以通过低代码扩展各种信贷进件系统、信贷审批系统等等
- 持续性,后续还将增加风控报告的功能,对不同产品、不同场景,提供多种评估报告
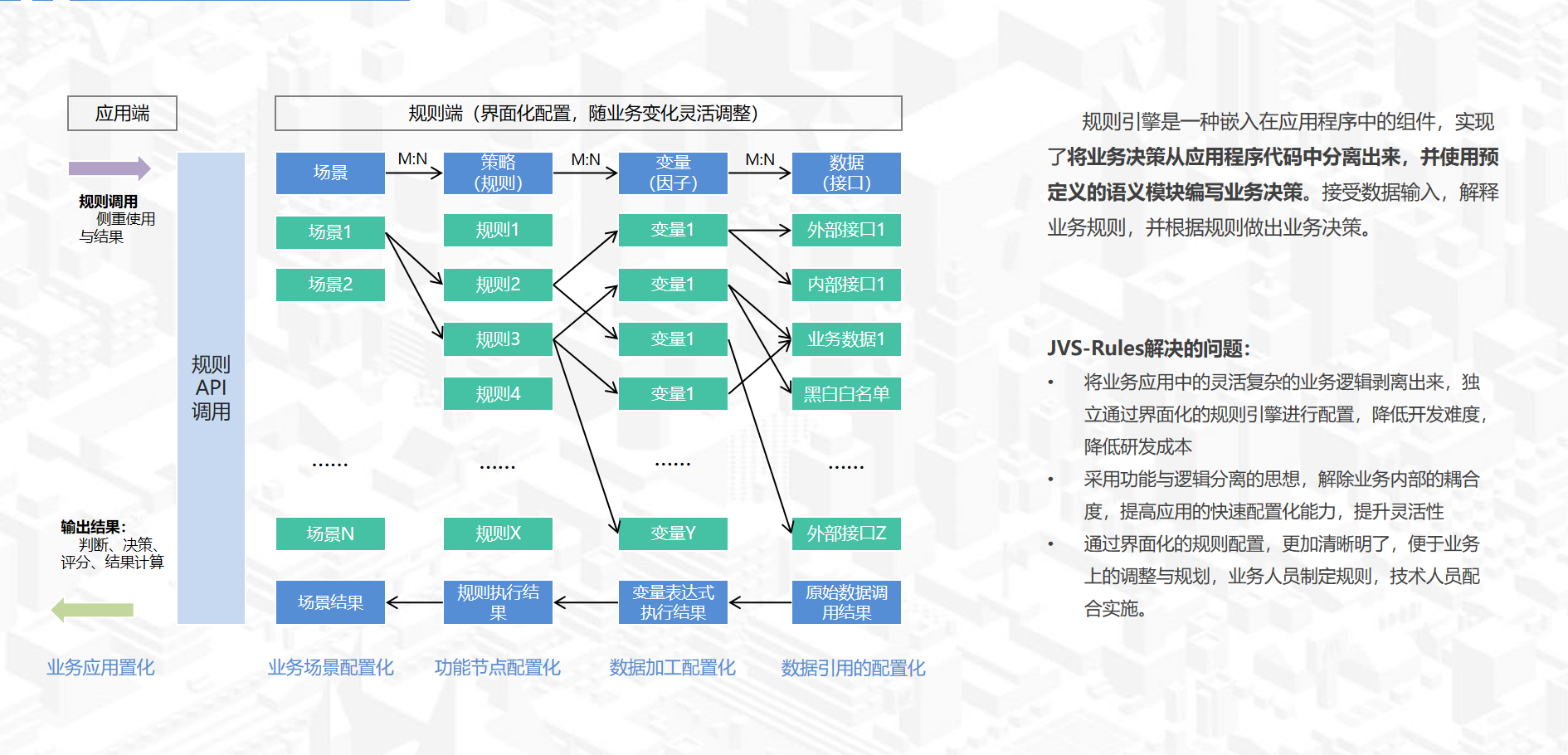
JVS-Rules=决策编排+规则表达+函数计算 三个核心部件构成
决策编排,用于将规则、策略、变量、衍生变量有机的组装成可以正确表达业务目标的可被重复执行的程序集合。
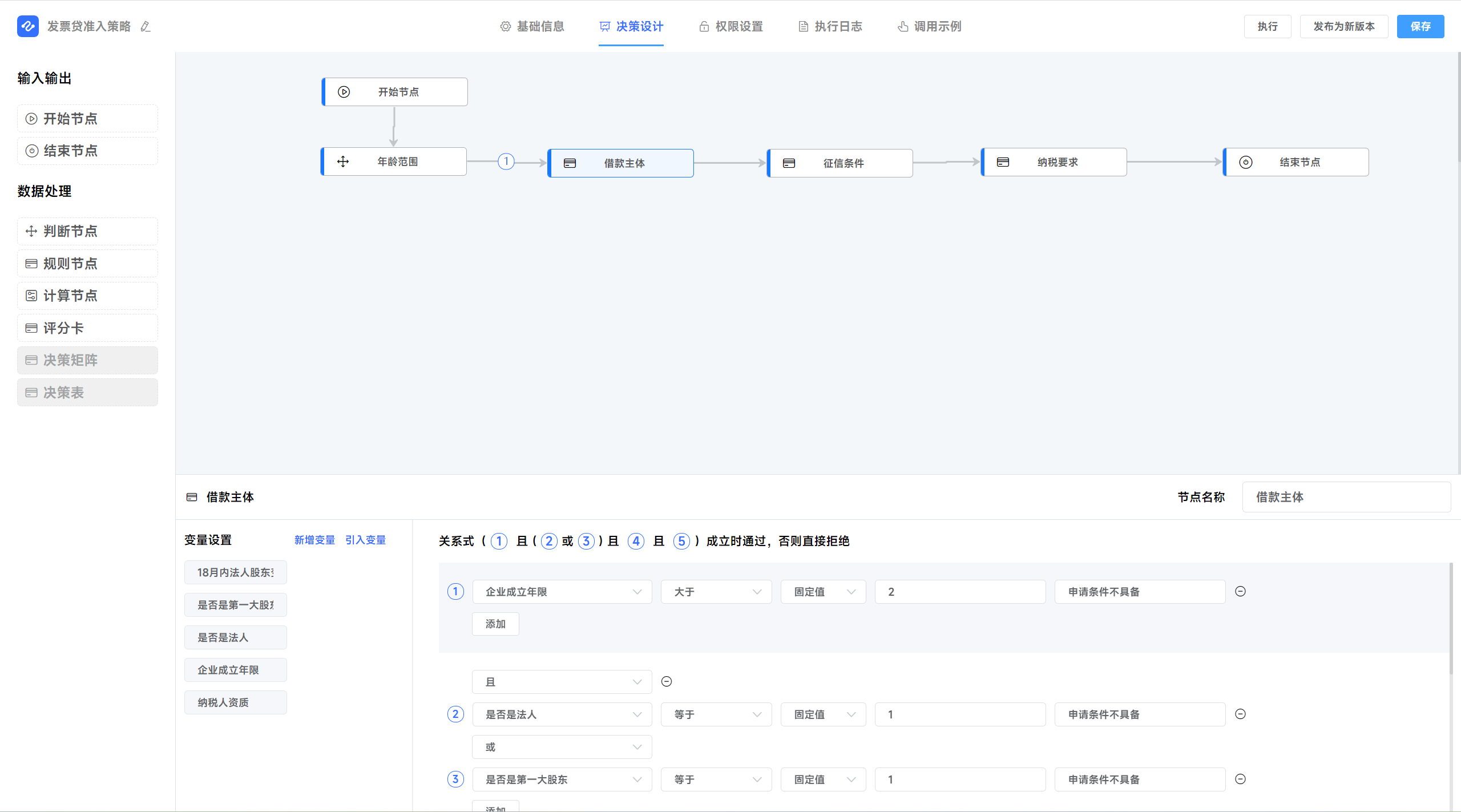
决策设计器的特点:
- 支持多种场景的决策设计,贷前用户筛查与额度授信、贷中在线决策、贷后周期管理、营销组合支持等等;
- 界面化的拖拽配置,更加清晰的表达判断逻辑,将业务规则与技术实现分离,业务只依赖技术底层变量的提供,规则层面的变化可以界面化的配置,大大提升了系统柔性的服务能力;
- 配置方式的优化,业务人员可以先配置逻辑、策略、规则等,完成后,再由技术相关的人员去实施变量的衍生与变量的绑定,真正让业务人员深度参与规则的配置,从而降低信息的损耗,提升IT支撑的效率。
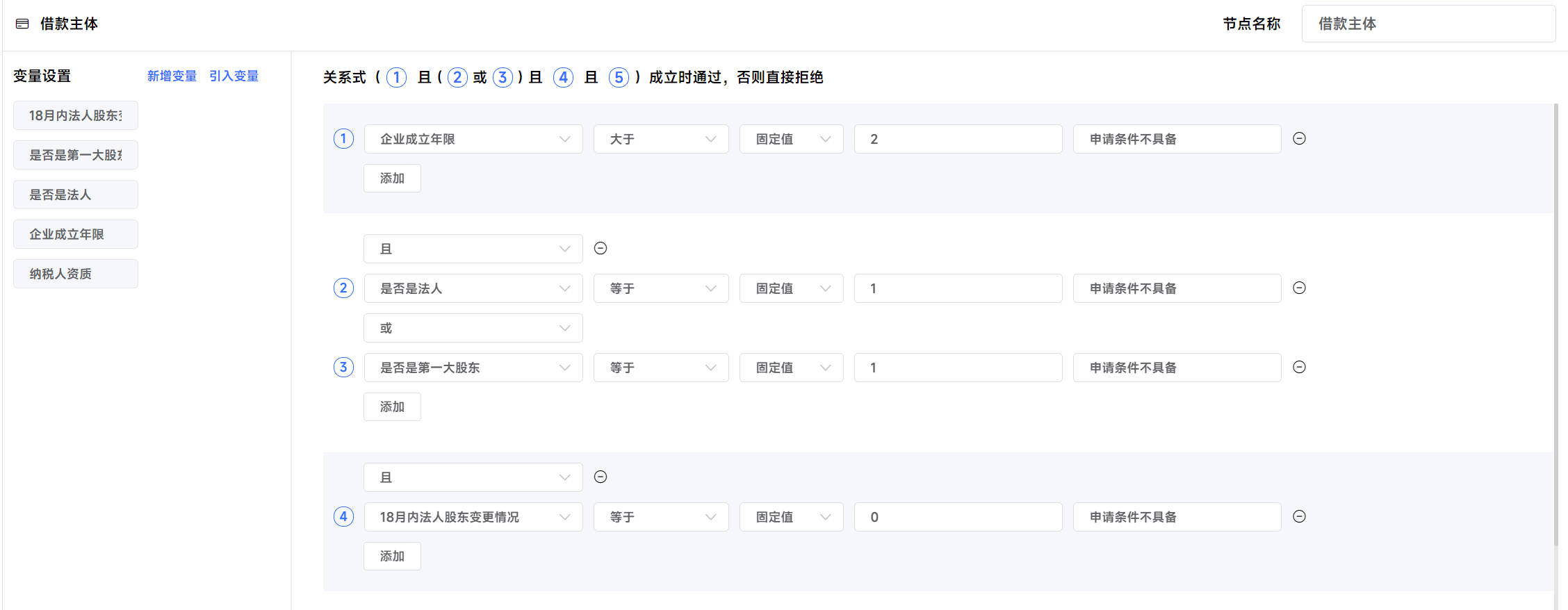
规则表达,将多个基础因子通过关系组合成有业务价值的逻辑表达式
函数计算,是将直接的底层数据加工为业务因子的配置工具
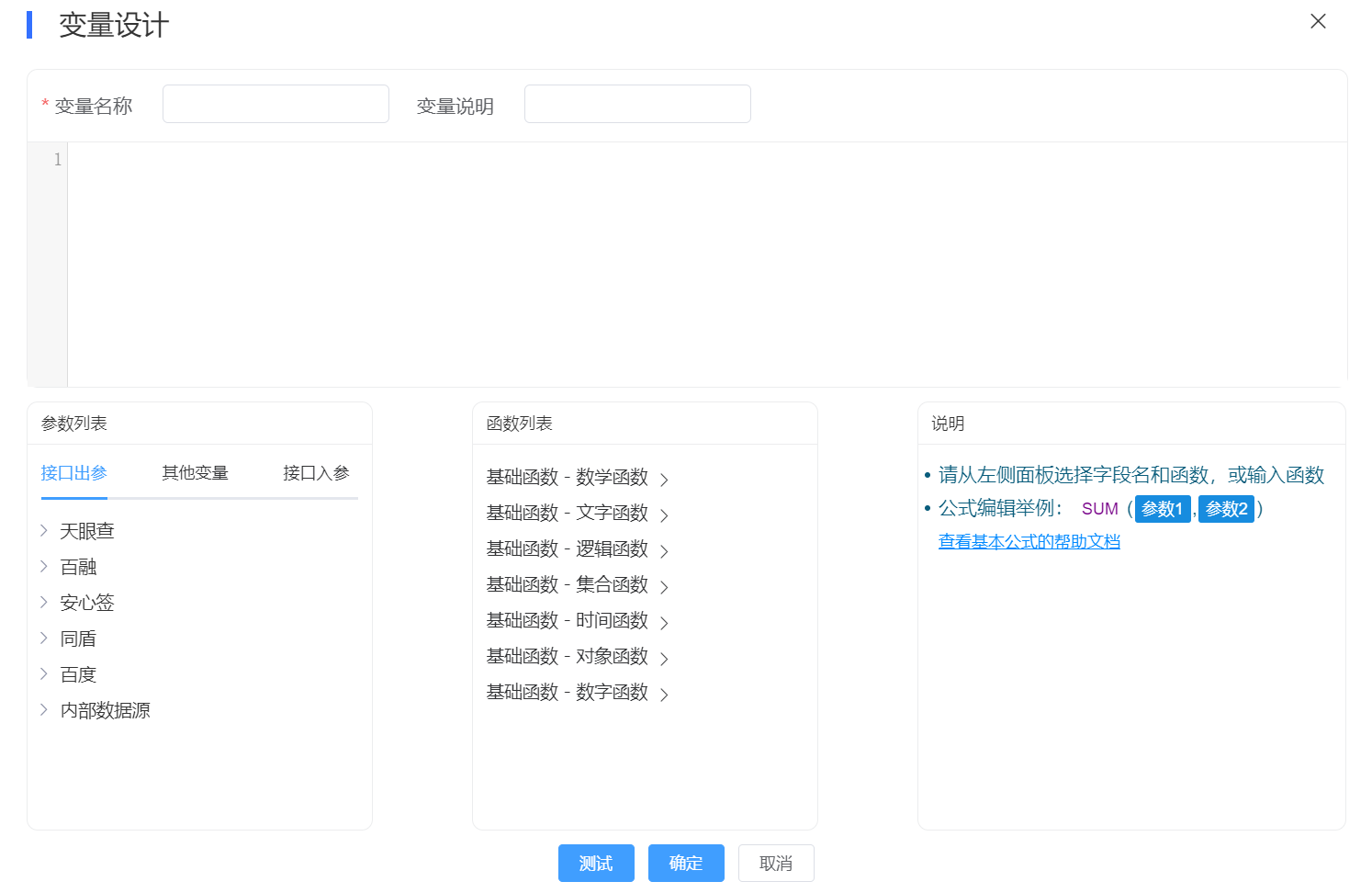
函数计算器,可以在界面化的配置变量的加工过程,业务人员在进行简单的培训后都可以上手使用,这样对技术人员的依赖度大大降低,从而降低风控运营的成本,提升风控IT服务的效率。
总结
JVS-Rules是一款真正能让业务人员可以产能与使用的规则引擎,使用简单;而非传统的规则引擎,都是需要技术人员通过编码实现关键配置逻辑。它是真正对风控或者内部经营的业务重新做了分工便捷的划分,业务人员可以更加便捷的调整业务规则,技术人员可以更加专注提供底层的技术实现,不需要非常清晰理解业务复杂的业务逻辑,清晰简单,更加执行高效。
关于规则引擎的更多功能介绍:
在线demo:http://rules.bctools.cn/















 7412
7412











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











