








论文精华解读 | 第一期
推荐阅读
13min
学术论坛第一期活动举办后,我们收到了很多大家对云智慧公开的《TransLog: A Unified Transformer-based Framework for Log Anomaly Detection》一文的关注,因此隆重推出了论文精华解读系列文章。
在第一期,我们邀请了南加州大学硕士生蔺同学来解读该文章,接下来让我们一起来看看吧~
章节目录
一、前言
二、Translog模型
三、方法
四、实验结果
五、总结
一、前言
AIOps(Artificial Intelligence for IT Operations)即智能运维,基于已有的运维数据(日志、监控信息、应用信息等),将AI应用于运维领域,来解决自动化运维无法解决的问题。日志异常检测作为AIOps中的一个重要研究方向,旨在通过日志了解系统运行中的异常。由于日志数据的数据量巨大,因此一旦发生日志异常,运维人员需要在大量的日志数据中查找异常,这是一个工作量巨大并非常消耗成本的工作。因此通过将人工智能引入到日志异常检测中可以有效减少运维人员的工作量。有关日志异常检测更为详细的内容,可以参照云智慧学术论坛第一期的内容。
二、Translog模型
尽管现在已经有很多利用日志序列(log sequence)中的语义信息,进行日志异常检测的深度学习模型,如HDFS、BGL或Thunderbird,但这些模型都只能在单一日志源上进行,语义信息仅适用于当前日志,无法泛化到其他日志源。而当前大型系统通常由多个不同组件构成,且不同组件打印的日志不尽相同,因此异常检测时需要针对每个日志源分别训练一个新模型,即保存多个模型的拷贝,参数量巨大。同时,当系统更新或升级引入新日志模式的组件时,现有的模型将无法适配新组件打印的日志。

为解决上述问题,论文首先指出,虽然日志的来源不同但实际上却有着相同的异常类型。尽管它们在词法和句法上有所不同,但在语义上却是相似的。如上图中三个来源的日志(BGL,Thunderbird,Red Storm)都有着”unusual end of program“类型的异常。因此,该论文认为如果模型能够学习到不同日志源间可共享的异常语义知识,就能够在所有日志源中识别出这一类型的异常。
基于此,该论文基于迁移学习的思想提出了一种名为Translog的日志异常检测框架。与现有针对新日志源需要从零开始训练一个新的模型的异常检测方法不同,该框架通过adapter结构中的少量参数(<1M),将语义上的异常知识迁移到目标日志源,或通过继续学习适配新的日志源,使得模型在多个日志源上都能有很好的表现。
三、方法

整体框架如上图所示。日志异常检测分为pretraining与adapter-based tuning两个阶段。对于新引入的日志源,模型首先在当前日志源上学习日志序列中可共享异常语义信息,再通过adapter-based tuning方式在新日志源上进行微调,学习新的知识。需要说明的是,在这里默认日志已经过解析处理,即模型的输入为每条日志所对应的模板。
在Feature Extractor部分,论文使用sentence-bert提取每个日志所对应模板的语义信息,将模板序列转换为具有相同维度的向量序列。目前已有的方法中有的直接通过BERT对日志进行编码,以达到减少日志模式解析过程中的信息损失的目的,但是考虑到海量的日志数据,用BERT对每一条日志进行词嵌入是不现实的。
Translog模型的主要结构是多层transformer encoder。之所以选用多层transformer encoder结构,一是因为该结构已经被BERT证实可以学习到通用的语言特征,并且可以被不同的下游任务所使用;二是因为在transformer结构中插入adapter进行扩展更加易操作。
在pretraining阶段,因为已经对模板进行了语义信息提取,模型会从语义层面学习异常。这一阶段训练时的目标函数是二分类的BCE loss,所有transformer中的参数都会更新,这些参数将会共享至下一阶段中,提供异常的语义知识,并不再更新。
在adapter-based tuning阶段,为了适应目标日志源,将会在transformer中插入adapter,并且在训练过程中仅有adapter中的参数进行更新。由于transformer的参数包含了原日志源中异常的语义信息,同时adapter中具有残差连接结构,adapter中的参数将重点学习target domain中独有的异常信息。其结构的灵活性还可以不断插入更多的adapter以适应不断新引入的日志源。
四、实验结果
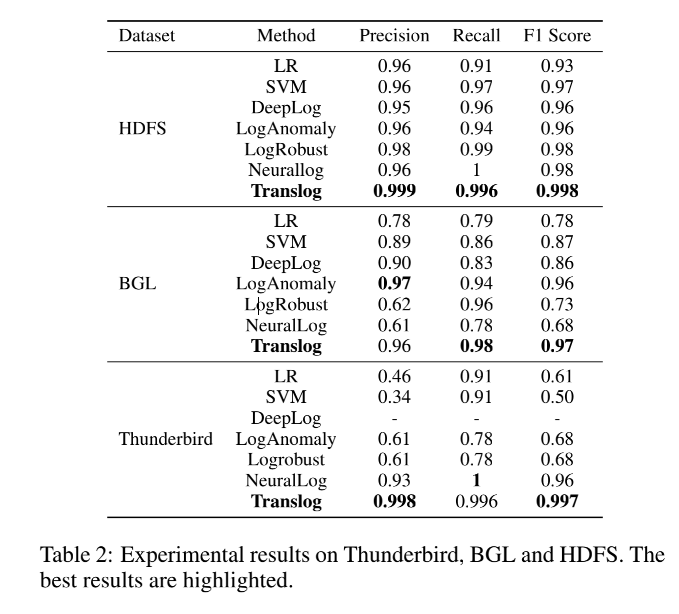
论文首先展示了模型pretraining阶段的表现。从上图可以看到,即使没有经过adapter-based tuning,Translog在三个数据集上都取得了最高的F1 score,这证明了模型主要框架的有效性。
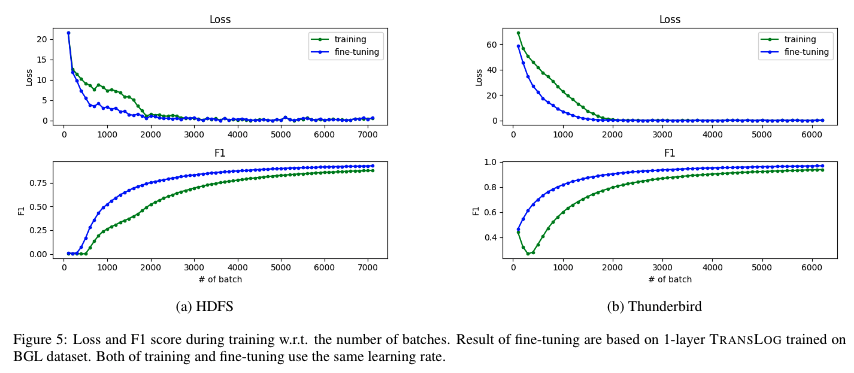
论文首次讨论了不同日志源之间迁移的可行性。为了进一步了解模型在pretraining阶段是否学习到了可共享的异常语义信息,作者选取了由随机参数和预训练的参数初始化的两个模型,通过实验对两个模型在新引入的日志源上训练过程的loss与F1进行了对比。在训练过程中对模型的全部参数进行更新。实验结果表明由于Translog框架的优异表现,两者最终都能够取得>0.99的F1 score,难以通过最终结果进行比较,因此本论文通过对训练过程中的表现进行对比分析。
通过上图可以发现,使用预训练参数初始化的模型在两个数据集上都表现出更快的收敛速度并且收敛过程更加平滑。可能是由于Thunderbird与BGL日志都来自于超级计算机,知识可以很好地共享,这一表现在Thunderbird数据集上更为突出。上述结果表明通过第一阶段预训练得到的参数,具有可共享的异常语义知识,使得模型在不同数据集之间迁移成为可能。
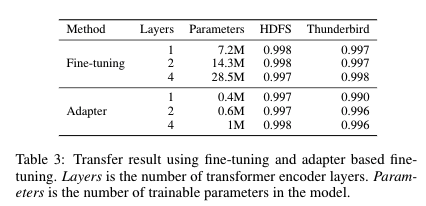
在上述实验虽然使用了预训练参数进行知识迁移,但仍需要微调整个模型,不仅训练开销大,还很容易在新的日志源上过拟合并遗忘之前的知识。因此,论文继续尝试使用adapter,通过增加少量的参数使原模型适应新的日志源,并讨论通过adapter适应新日志源的可行性。
实验对比了fine-tuning与adapter-based tuning在迁移到新日志源时的表现。上图为两种方法在不同层数transformer下的结果,参数栏为模型需要更新的参数量。对比发现,插入adapter后,仅用大约3%-5%的可训练参数,就能够取得与fine-tuning相似的成绩。单层Transformer就能够取得很好的表现,继续堆叠更多的Transformer作用不大。
上述结果表明每个日志源中的异常信息十分有限,只需要adapter中的少量参数就足以达到微调整个模型的表现,由此可得,通过adapter使原模型适应新日志源的方法是可行且高效的。
五、总结
该研究展示了日志异常检测领域中,不同日志源之间进行知识迁移的可能性。让我们更期待日志领域出现更多大型预训练模型,可以对多种日志源进行融合处理,使得日志异常检测不再局限于单一日志源。
注:本文为对论文初稿的解读,不代表该论文的最终品质。
本期论文解读就到这里啦~
大家对本篇论文的有哪些意见或者想法,
可以在下方评论一起沟通交流呀~
同时欢迎大家推荐优质论文~
让我们一起学习探讨智能运维领域最新学术发展~

点击下方获取论文全文
↓↓↓
https://arxiv.org/abs/2201.00016![]() https://arxiv.org/abs/2201.00016
https://arxiv.org/abs/2201.00016















 1969
1969











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









