






整体架构
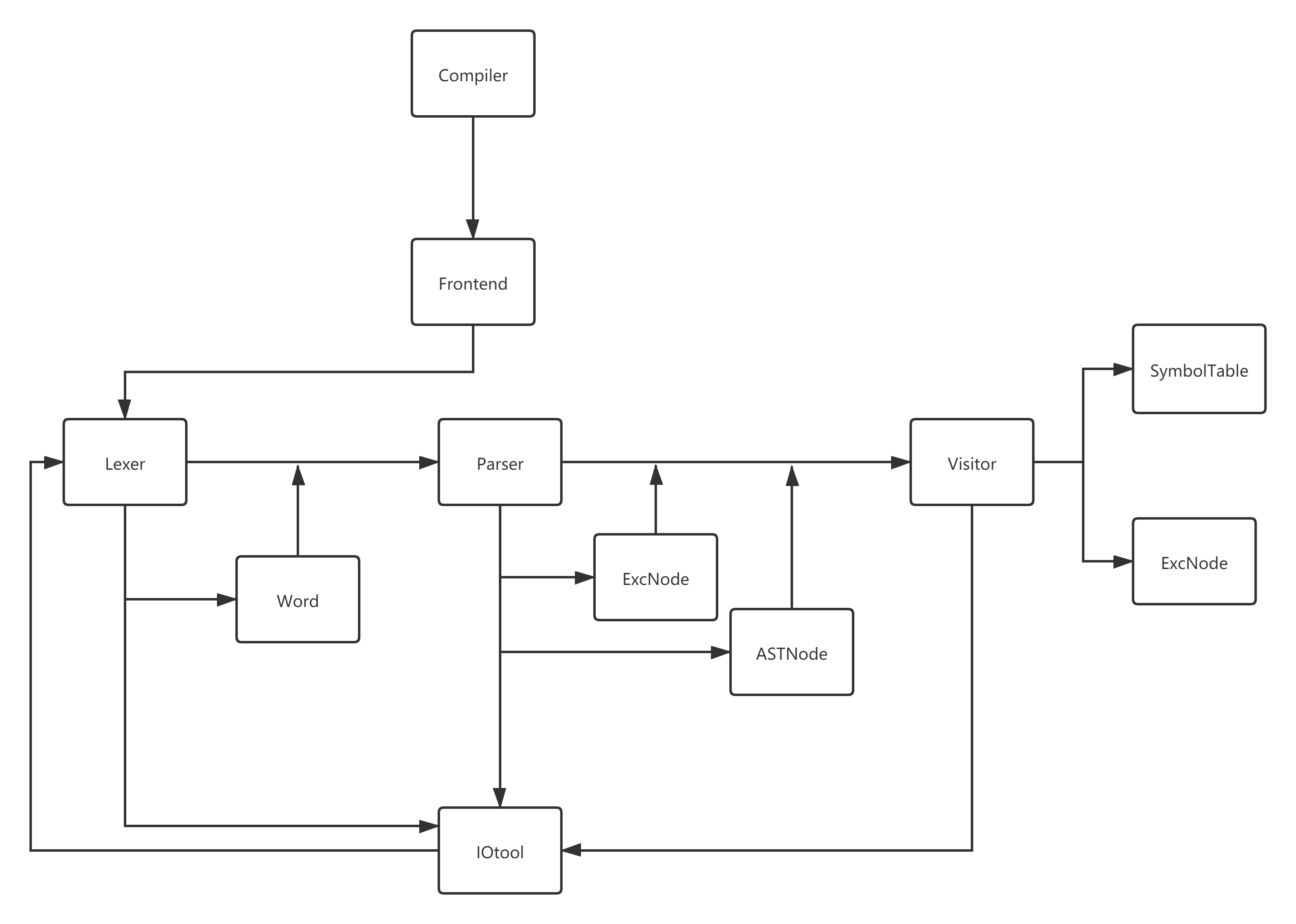
本阶段编译器总体设计如上图所示。顶层为Compiler类,由Frontend类进行前端各个类之间的处理流程和数据传输。首先先利用IOtool类获得输入,之后将输入的代码送入Lexer 进行词法分析,由词法分析将代码转换成token形式的单词表,用Word类存储,将这个Word类的列表作为Parser语法分析的输入数据,Parser进行语法分析并处理a/i/j/k 四个简单错误,输出抽象语法树和一个错误节点的列表,作为Visitor的输入,Visitor遍历语法树建立符号表并处理其他的语义层面和符号相关错误,输出完整的错误列表和符号表。整个过程中由各个类完成输出字符串拼接,由IOtool 类输出字符串到文件。
词法分析
词法分析主要通过两个类实现,分别是Lexer和Word,其中Lexer为词法分析程序,Word为单词类,存储每个单词的一些信息。
Word类
Word类主要用三个参数:line, sym_type, content分别表示每个单词所在行数,单词类别,单词内容,通过Lexer进行生成及初始化。
Lexer类
Lexer类有几个容器,str2sym_type表示单词内容对应的单词种类,用于识别终结符,由于是一对一,所以用以单词种类为key,终结符类型为value的HashMap存储;characters用以存储现在已经分析过的单词序列;errors用以存储词法分析过程中发现的一些错误。同时有个mode表示当前模式,主要用于过滤注释。
Lexer工作的流程主要为:初始化 → 读入一行 →分析一行 →读入下一行 …→读完整个程序→返回单词序列
初始化
主要将所给的一些终结符及对应的类型存入HashMap中,
词法分析
每次将程序文件的一行读入,逐个分析字符:
-
如果读入的字符为字母或下划线便一直读入并拼接直至不是,然后判断这串字符是否存储在str2sym_type中,如果存在直接新建对应单词,否则表示该单词为Ident。
-
如果读入字符为’/',表示接下来将会是注释,读入下一个字符来辨别是单行注释还是多行注释,如果是单行注释,mode为1,本行接下来读入的字符全部过滤;如果是多行注释,mode为2,不停地过滤字符,直至读入’*/‘的连续字符才终止。
-
如果读入的字符为'"',表示接下来为FormatString,直至下一个'""'出现前为FormatString的内容。
-
如果是其他字符(除了'"','/'),根据单词表及所读入字符分析是什么类别的单词,同时,注意到部分单词的第一位相同,比如!和!=,所以读入一位后再读入一位判断区分二者
将所有分析到的单词都加入单词列表中,完成词法分析任务。
语法分析
语法分析主要通过两个类实现,分别是Parse和Node,其中Parse类用于语法分析生成语法树而Node类为树结点类,表示语法树的结点,存储了相应的信息。
Node类
Node类主要用三个属性:isEnd表示当前是否为终结符,type用以表示非终结符的类别,token用以表示终结符的单词信息,同时每个Node有个列表用以存储自己的子结点。
Parse类
Parse类主要负责语法分析,我主要采用的是递归下降的方法,先把文法中的左递归消除,然后划分出每个非终结符的First集,尽量避免回溯进行分析。
主要工作流程为:将词法分析输出的单词表导入→利用递归下降分析→得到语法树
递归下降
主要讲下是如何通过递归下降生成的语法树,根据分法我们可以知道语法树的根节点一定是CompUnit,所以以CompUnit为起点开始向下分析,每个非终结符的分析对应一个返回值为Node的函数,如Decl(),这样便可以在父层直接利用father.addSon(Decl())建立父子关系。每次进入一个非终结符的分析函数时,通过根据所分析的First集及当前读入单词来判断该结点要对应哪条文法,进而进一步递归。
递归下降之前需要将文法的左递归消除,举一个例子,我们可以将
LAndExp → EqExp | LAndExp '&&' EqExp修改为
LAndExp → EqExp {'&&' EqExp}便可消除。
在文法分析过程中,发现有一处不得不需要回溯,
Stmt → LVal '=' Exp ';' | [Exp] ';' | LVal '=' 'getint''('')'';'可以看到,Stmt非终结符对应的这三个关系的First集都有Ident,并且Exp的子结点中First含有Ident的只有Lval和UnaryExp,且UnaryExp的Ident后一定跟的是'(',LVal的Ident只会跟着'['或没单词,所以就可以区分了。我们先记录当前pos位置,接着预读一个LVal,然后判断当前单词是什么,如果是'=',表明为第一种或者第三种,再根据下一个单词是否为'getint'便可区分;如果不是'=',进行回溯,回到之前记录的pos位置,表明当前对应的是第二种情况,接着读Exp即可。
错误处理
首先分析错误类型,判断每个类型的错误在哪个阶段可以检测出来,可以发现a类错误在词法分析阶段可以检测,i、j、k类错误在语法分析阶段可以检测,其余错误通过分析语法分析生成的语法树进行分析。每个错误利用工具类Error记录其行号和错误类型。
Lexer词法分析阶段错误
词法分析阶段可以发现a类错误,当读到\或者%时向前偷看一个符号,\后面只能是n,%后只能是d,否则生成错误,并且标记该行已出错,不再解析错误。同时对于FormatString读取的每一个字符,判断其是否在合法字符集合中,若属于合法字符集合便生成错误。
Parse语法分析阶段错误
语法分析阶段可以发现i、j、k类错误,在递归下降过程中对可能出现错误的非终结符分析是否缺少相应符号。
对于i类错误,有如下几个规则可能出现错误
ConstDecl → 'const' BType ConstDef { ',' ConstDef } ';'
VarDecl → BType VarDef { ',' VarDef } ';'
Stmt → LVal '=' Exp ';' | [Exp] ';'| 'break' ';' | 'continue' ';'| LVal '=' 'getint''('')'';' | 'printf''('FormatString{,Exp}')'';'
由于分号出现在每个规则末尾,以第一个规则为例,在读取完最后一个ConstDef后,判断当前符号是否为';',若不是便生成错误。
对于j类错误,有如下几个规则可能出现错误
FuncDef → FuncType Ident '(' [FuncFParams] ')' Block
MainFuncDef → 'int' 'main' '(' ')' Block
Stmt →'if' '(' Cond ')' Stmt [ 'else' Stmt ]| 'while' '(' Cond ')' Stmt
| LVal '=' 'getint''('')'';'| 'printf''('FormatString{,Exp}')'';'
UnaryExp → Ident '(' [FuncRParams] ')'
对于k类错误,有如下几个规则可能出现错误
ConstDef → Ident { '[' ConstExp ']' } '=' ConstInitVal
VarDef → Ident { '[' ConstExp ']' } | Ident { '[' ConstExp ']' } '=' InitVal
FuncFParam → BType Ident ['[' ']' { '[' ConstExp ']' }]
LVal → Ident {'[' Exp ']'}
j、k类错误相似,都是括号匹配,对于出现在规则末尾的右括号,与缺少分号的判断方法一致,读取完括号前一个符号后判断当前是否为右括号,不是便生成错误。特殊地,若括号间有无法预知数量的结点,需要根据右括号下一个字符的First集中的符号来进行判断,以FuncDef → FuncType Ident '(' [FuncFParams] ')' Block为例。
Block的First集中只有'{',而FuncFParams的First集为‘int',当我们读完左括号,若当前符号为右括号,正常进行;若当前字符为'{',表示已经不再有FuncFParams并且开始读Block了,但是并没有读到右括号,生成错误;生育情况便先读一个FuncFParams,然后再判断当前符号是否为右括号来判断是否缺少。
Visitor错误处理
用Visitor类,遍历语法树分析其余错误。Visitor类中有如下几个HashMap容器:floor2Table表示深度对应的符号表,funcName2Symbol表示函数名字对应的函数符号,记录了相应信息。
符号类Symbol记录了富豪的名字、类型及作为一些类型应该有的属性(如函数符号的参数列表,常量的常量值等)。符号表类Table记录了当前符号表是否在循环内,是否需要返回值,及该符号表内的所有符号(利用name2Symbol HashMap存储,名字对应Symbol方便查重)。
从语法树的根节点出发,遍历语法树。
对于b类错误,每当遇到一个新的定义,便在当前深度的符号表中查询是否存在同名符号,若存在便生成错误。
对于c类错误,对于每个ident结点,从内往外找符号表,若未找到该ident名字对应的符号便生成错误。
对于d类错误,只可能出现在<UnaryExp>→<Ident>‘(’[FuncRParams ]‘)’
读到UnaryExp结点时,若子结点个数>=3,表示读到函数调用了,通过查表可以得到ident对应的函数的参数个数realCnt,接着解析UnaryExp结点的FuncRParams计算实际使用的参数个数cnt,若不存在该结点表示cnt=0;若存在便计算FuncRParams的子结点有几个Exp,每个Exp对应一个参数,最后得到使用的参数个数cnt,比较realCnt和cnt,若不相等便生成错误。
对于e类错误,出现情况和d类似,由于我们的参数类型只有int,不匹配的情况只有维度不匹配。通过ident得到函数符号,进而得到其的参数列表,在解析UnaryExp结点的FuncRParams过程中每读到一个Exp,便从参数列表取一个新的参数符号,对比两个符号的维度,若不同便生成错误。求Exp的维度的方法就是一直往下搜,直到子结点个数大于1,若当前结点是LVal,便可查符号表得到维度,若当前结点为UnaryExp,表明为函数调用,查符号表看该函数类型,若为void直接生成错误,若为int表明维度为0,其余情况Exp维度均为0,便可得到Exp的维度。
对于f、g类错误,我给每个符号表Table设置了一个FuncName属性,如果当前符号表于函数中便为其设置其所在函数名。当<Stmt>→‘return’ {‘[’Exp’]’}‘;’读到这一步时根据当前深度符号表的FuncName查表得到相应函数符号,进而查询函数类型,若函数类型为void而return 后跟着Exp或函数类型为int而return 后跟着';'便生成相应错误。其中g类错误只考虑其最后一句。
对于h类错误,当读到<Stmt>→<LVal>‘=’ <Exp>‘;’|<LVal>‘=’ ‘getint’ ‘(’ ‘)’ ‘;’时,对LVal子结点中ident查表,得到相应符号,判断符号类型,若为const便生成错误。
对于l类错误,当读到Stmt →‘printf’‘(’FormatString{,Exp}’)’‘;’时,通过子结点计算表达式个数,在词法分析过程中已经提前根据%d的个数计算了需要的表达式个数,两者比较若不同便生成错误。
对于m类错误,给每个符号表设置了loop属性判断其是否在循环中,每当读到while接下来深度大于当前符号表都处于循环中,结束这个while后再设置为出循环。若读到continue或break时,根据当前深度符号表的loop属性判断,若loop为false便生成错误。
三个类中的错误分别用三个列表存储,最后根据行号归并排序,输出到error文件中。
中间代码生成
与错误处理类似,遍历语法树对相应的结点生成对应的中间代码。利用的类有自己的NameSpace工具类及各种中间代码类,NameSpace根据flag判断种类分为四种,常数、临时变量、左值表达式LVal及函数返回值,并记录其相关信息如临时寄存器编号、数组维度、是否为全局变量等。
中间代码类
中间代码由若干个类继承一个IRSentence父类,各子类介绍如下
| 类名 | 属性 | 作用 |
|---|---|---|
| And | NameSpace arg1 NameSpace arg2 NameSpave target | 与指令 |
| Array1 | String ident NameSpace value int size int index boolean isConst | 两种作用,定义一维数组及一维数组初始化 |
| Array2 | String ident NameSpace value int size1 int size2 int index boolean isConst | 两种作用,定义二维数组及二维数组初始化 |
| BlockTag | int floor //深度 int type //begin or end | 标记每个块的开始及结束 |
| Decl | String ident int type //标记常变量定义或函数定义 int flag//标记常变量/函数类型 NameSpace assign | 用于常量变量定义或函数定义 |
| FuncCall | String funcName NameSpace para int type //标记是函数调用还是push参数 boolean flag//标记push参数时是否为取地址 | 用于函数调用/push参数 |
| FuncEndLabel | String funcName | 标记函数结束 |
| JType | String jumpType//跳转指令类型 String target//目标位置 NameSpace arg1 NameSpace arg2 | 跳转指令 |
| Label | String label | 标签 |
| Para | String ident int dim Symbol symbol | 函数所需要的参数 |
| int type //标记是str还是%d NameSpace value //%d String str | print输出 | |
| Quadruple | NameSpace result NameSpace arg1 NameSpace arg2 String op | 四元式 |
| RelExpSlt | NameSpace target NameSpace arg1 NameSpace arg2 int type// slt sltiu sltu | slt指令,主要用于RelExp中的比较 |
| Ret | boolean haveValue NameSpace value boolean mainEnd//标记是否为主函数结束 | 用于函数返回值 |
| XOr | NameSpace target NameSpace arg1 NameSpace arg2 | 异或指令 |
具体生成方式
与错误处理类似,遍历语法树,并建立相应符号表,不同的是生成中间代码需要对相应的语法树结构生成相应的中间代码,下面对主要的几个点做出叙述。
对于各种与Exp有关结点,从Exp结点开始向下深入递归,再从内向外返回NameSpace类,有如下几种可能:
LVal结点,根据ident查表得到符号Symbol,再根据Symbol的类型判断是常数还是变量再根据子结点的个数判断维度,生成相应NameSpace
UnaryExp结点,当对应函数调用时,先查表找到该函数符号,接着不断读入后续输入参数,挨个与函数参数维度进行比较,如果不同表示需要取地址,生成相应的FuncCall中间代码,并返回一个新的临时变量NameSpace,并在中间代码中生成相应四元式让其等于2号寄存器的函数返回值。
MulExp和AddExp结点,由于语法分析过程中已经消除左递归,其子结点都是若干个RelExp和MulExp,从左往右挨个生成NameSpace并在每两个NameSpace中加入相应的运算符并生成四元式即可,并返回最终结果的NameSpace。
RelExp结点,对子结点从左往右挨个生成NameSpace,根据相邻两个间的符号生成相应的中间代码,具体如下表格:
| 符号 | 中间代码 |
|---|---|
| < | slt target arg1 arg2 |
| > | slt target arg2 arg1 |
| <= | slt target arg2 arg1 xori target target 1 |
| >= | slt target arg1 arg2 xori target target 1 |
最终返回target
对于Decl结点,根据ident查表得到Symbol,进而得到维数,通过前面所述读取init初始化得到初始化结果的NameSpace,针对不同维数生成相应中间代码。特殊地,对于常量,在编译阶段便可计算出其结果。
RelExp结点,
Cond结点,读取cond需要传入参数outLabel,stmtLabel分别表示条件判断失败和成功时跳转目标标签,用于短路求值。
EqExp结点,若子结点个数为一,直接返回读取子节点的结果;否则从左往右读取子节点,先将arg1与arg2异或结果存入tmp中,然后用sltu tmp $0 tmp即可得到arg1是否不同于arg2,若符号为'==',再对将tmp异或个1即可得到是否相同结果。
LAndExp结点,若子结点个数为一,直接返回读取子节点的结果;否则从左往右读取子节点,对于每个子结点返回NameSpace的结果tmp,利用beq,beq tmp $0 nextLabel,其中nextLabel为条件判断结束的目标标签或下一个或运算位置的标签,实现短路求值。
LOrExp结点,若子结点个数为一,直接将用beq,若其等于0便跳到条件判断结束的目标标签;否则从左往右读取子节点,对于每个子节点返回NameSpace的结果tmp,若是最后一个子结点了,利用beq tmp $0 outLabel跳到条件判断结束标签;若不是就利用bne tmp $0 stmtLabel,让其成立时跳进条件成立时目标标签。
Stmt结点,有几种情况:
LVal = Exp / getint 直接用生成相应四元式
return Exp;根据是否有返回值生成相应Ret
while语句 先生成while begin 标签,然后读取Cond并设置其outLabel和stmtLabel为while out 和 while stmt。接着添加while stmt标签,表示条件成立跳转位置,接着独居Stmt内容,然后生成跳转指令跳转至while begin,最后设置while out标签。
break/continue结点,直接生成相应跳转指令跳转至循环结束位置/开始位置的标签
if语句 根据子结点个数可以判断是否有else,如果没有else直接读取Cond并设置其outLabel和stmtLabel为if out和stmtLabel,然后生成stmtLabel表示条件成立时目标标签,接着读取stmt,最后生成if out标签表示if结束位置标签;如果有else,先读取Cond并设置其outLabel和stmtLabel为if else和stmtLabel,然后生成stmtLabel表示条件成立时目标标签,接着读取stmt,接着生成跳转指令跳转到if out标签出if,生成if else标签,然后读取stmt语句,最后生成if out标签。
print语句 先获取输出的formatString,接着遍历该字符串,每当遇到一个'%',就将其前面的字符作为一部分生成Print字符,接着生成一个Print变量,直至读完整个formatString。
FnuncDef结点,基本与错误处理类似,新增识别到函数各个参数后生成中间代码Para,接着读取Block,对于void类型函数,如果在Block中没有return需要自己生成一个无返回值的Ret。
目标代码生成
根据前面生成的中间代码,传入Translator类中,翻译成目标代码。
先介绍下内存分布,将全局变量以及可能需要print的字符存在以0x10010000为起始地址的全局数据区中,将局部变量存在以0x10040000为起始地址的堆数据区中,调用函数时会有所不同,后续介绍。
Translator根据传入的中间代码列表逐个分析,根据特判其属于IRCode的哪个子类来进行不同的读取。
整体框架为:全局变量->print 输出的字符str->函数->利用跳转指令j main跳转至主函数->主函数
寄存器分配
对于各种数据的获取与传递需要利用寄存器,我利用简单的寄存器分配原则,在我们的实验中,5-28号寄存器都是可以使用的,利用FIFO原则,每次需要一个新的寄存器,返回上次使用的寄存器编号+1,超过28便返回5。仅临时变量和函数参数对寄存器有一定的使用周期,利用一个HashMap存储临时变量编号对应的寄存器编号,当此次所取寄存器编号已被其它临时变量使用,将原来的临时变量存入内存,再返回这个寄存器。函数形参类似,生命周期仅在函数中,且不可被取代,因为没有给他分配地址。
读取NameSpace
许多中间代码需要用到工具类NameSpace,所有有个专门用来获取NameSpace信息的函数,返回值为一个寄存器编号。前面讲过,根据flag可以将NameSpace分为四种,常数、临时变量、左值表达式LVal及函数返回值。
对于常数,直接利用li指令将其存到一个新的寄存器中返回,特别地对应常数0返回0号寄存器;
对于临时寄存器,获取一个新的寄存器,并将临时变量编号及寄存器编号存入前面讲的临时变量编号对应的寄存器编号的HashMap中;
对于左值表达式LVal,如果是取值,在符号表中找到该符号记录,根据NameSpace的dim信息可以知道维度信息,对于普通0维变量,直接将其lw到一个新寄存器中,对于1维数组,symbol中存有其起始地址,NameSpace中存有其偏移量,进行相应计算得到地址并lw到一个新寄存器中,对于二维数组,与一维类似,最后返回寄存器编号。如果是取LVal地址,考虑到函数参数取地址可能的情况:对于一维数组参数int a[],可能有一维数组b或二维数组b[x],对于二维数组参数,只能由二维数组b。所以,先查符号表获取起始地址,若所需要的为一维数组参数,根据查表得到的符号信息查看符号对应维数,如果Symbol为二维而NameSpace为一维,表示为取二维数组的一维作为参数;如果Symbol为一维且NameSpace也为一维,表示取数组元素的地址;如果Symbol为一维或者二维而NameSpace为一维,表示作为一维数组参数或二维数组参数,直接返回首地址;如果NameSpace为二维表示取二维数组元素的地址,根据偏移量计算即可。
对于函数返回值,直接返回二号寄存器。
读取Decl
有一个main函数开始的Label,在此Label之前main函数还未开始,读入的都为全局变量或函数的局部变量、形参。
所以,对于全局变量,直接存入.data段,并更新符号表,为其设置相应地址。
对于局部变量,根据是否为函数的局部变量分两种存储方式,对于main中的局部变量,直接存入堆中;而对于函数中的局部变量,存入sp指针的下方。特别地,对于函数中定义的数组局部变量,其首地址在最下方,使得其与正常main函数的数组变量取值方式相同。
读取Quadruple四元式
根据Quadruple的种类判断,如果是普通四元式,根据arg1,arg2,result得到相应寄存器,根据op确定运算符,直接输出即可;如果是LVal=getInt型,查符号表可确定地址,将系统调用返回值v0存入即可;如果是LVal=exp型,同样查符号表得到地址,将exp对应临时寄存器存入即可。特别地,如果LVal是函数实参且不是数组参数,则不用存入内存,只需要修改相应寄存器的值即可。
读取JType跳转指令类型
根据JType类型判断为直接跳转还是条件跳转。如果为直接跳转,直接调用已重写的toString方法;如果为条件跳转,读取两个比较的参数及目标标签,输出即可。
读取Move、And、XOr、Slt类型
都是根据这几个类中几个参数属性调用readNameSpace获得相应寄存器生成不同指令,不再赘述。
读取Print
print分为两种,输出字符和输出%d,对于前者,利用一个位置标记print的字符存储的地址(.data段),每次读到一个print字符,在标记的地址中存入,并且通过计数器计算为第几个输出字符strcnt,直接利用la strcnt及系统调用即可;对于后者,直接读取%d对应的value,再用move指令将其移到2号寄存器进行输出。
读取FuncCall函数调用
调用函数时的内存分布大致如图:
| 内存分布 |
|---|
| needReg(保存现场所保存的寄存器) |
| para(函数调用参数) |
| sp |
| local(函数内局部变量) |
每当读取到一个函数调用类型,先保存现场,我只需要保存现在已经分配给临时变量的寄存器的值以及函数参数,将他们存在sp上方,然后push参数,最后jal跳转至目标函数。回来的时候需要恢复现场,跳过函数参数后将原来保存现场存入内存的重新按反向lw出来即可恢复。
而读取函数的时候,由于参数入栈从左往右,所以在sp上方从上往下,而我读取参数的时候从sp上方从下往上读,所以本质上是从右往左读取的函数参数。
特殊地,当调用函数所用的参数也是一个函数调用时,先标记最外层函数名,每当读到一个FuncCall,若其跳转的函数为标记的函数名,则结束,否则为函数调用嵌套,需要先恢复现场并将内部函数调用参数移除再继续读取参数。
读取Ret函数返回
如果为主函数结束,直接系统调用终止。
若为有返回值函数的返回值,利用move指令将返回值移到2号寄存器,接着调用jr返回。
若为无返回值函数的返回,直接调用jr。















 6991
6991











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









