




 文章讨论了计算机中字符的概念,特别是与Unicode和Java中的char类型的关系。它指出Java的char类型只能表示Unicode的基本多语言平面(BMP),对于超出此范围的字符,需要使用代理对。此外,文章还提到了Unicode的组合字符和正规化问题,强调了字符在视觉和计算机内部表示之间的差异,并举例说明了如何处理这些问题。
文章讨论了计算机中字符的概念,特别是与Unicode和Java中的char类型的关系。它指出Java的char类型只能表示Unicode的基本多语言平面(BMP),对于超出此范围的字符,需要使用代理对。此外,文章还提到了Unicode的组合字符和正规化问题,强调了字符在视觉和计算机内部表示之间的差异,并举例说明了如何处理这些问题。
在这一篇, 我们谈论最后一个话题, 就是"到底怎样才算一个‘字符’"?
其实这个话题在 字符集与编码(五)–代码单元及 length 方法 中和 文本在内存中的编码(1)–乱码探源(4) 也有所涉及, 这里结合字符流的话题再综合深入探讨它一下, 并且还将涉及一个 unicode 组合字符及正规化的话题. (这在前面也没有涉及过的)
怎样算是一个字符?
初看起来, 这是个很 naive 的问题. 以前面经常举的例子来说:
“h” 是一个字符;
“i” 是一个字符;
“你” 是一个字符;
“好” 也是一个字符.
所谓"字符", 那不就是我们眼睛看到的那一个个抽象的"东西"吗? 这好像也没什么难理解的. 然而, 计算机里的一切都是很具体的, 也通常是带有某种限制的.
举个例子来说, 我们常说的"一个整数"就是一个抽象的数字, 而计算机中, 就以 Java 为例吧, 最直接对应的概念就是一个 int, 这是一个很具体的东西, 然后是带有某种限制的, 比如只有 32 bit, 还分了正负数, 所以它能表示的整数是有一个范围的, 不是你头脑中想到的每一个整数都能塞到这个 int 里面去.
那么同理, Java 中所谓的‘字符’, 包括所谓的‘字符流’这些个概念, 严格地讲, 这里的‘字符’具体指的是 char, 也就是 Java 中的那个基本数据类型 char.
基本数据类型 char 是 16 位的, 无符号的(也就是不分正负数, 都算正数), 所以它也是有范围限制的, 撑死了最多也就能表示 2^16, 也就是 65536 个不同字符.
可是另一方面我们知道, Unicode 的范围是 U+0000 ~ U+10FFFF(0 ~ 1114111), 是百万级别, 1114112 这个值可比 65536 大得多了去了.
有很多位置还是空的, 但目前已经定义的字符也有 13 万+ 了(截至 2017 年 6 月, 具体见 Unicode 10.0 版本中的介绍: http://www.unicode.org/versions/Unicode10.0.0/.
所以, 很明显, char 中根本放不下那么多. char 只能容纳 U+0000 ~ U+FFFF(0 ~ 65535)间的字符, 这段范围称为 BMP(基本多语言平面);对于 U+10000 ~ U+10FFFF 间的字符, char 表示力有不逮, 心有余而空间不足~
关于 Unicode 的介绍: 字符集与编码(四)–Unicode.
一个 BMP 外的字符
比如, 前面一再提到的那个音乐符号【𝄞】(假如你的系统字符集不支持, 这个字符将显示不出来), 如下图:
它是 U+1D11E(119070) 号字符, 大过 U+FFFF, char 这座小庙放不下这尊大神, 强行赋值给 char 会导致报错(非法字符常量: Invalid character constant):
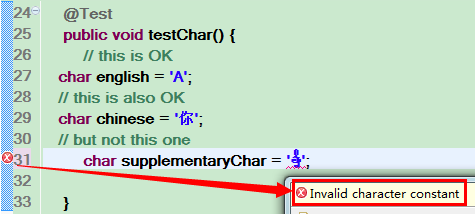
@Test
public void testChar() {
// this is OK
char english = 'A';
// this is also OK
char chinese = '你';
// but not this one
char supplementaryChar = '𝄞';
}
这个字符无论是用 utf-8, utf-16 还是 utf-32 都要占用四个字节:
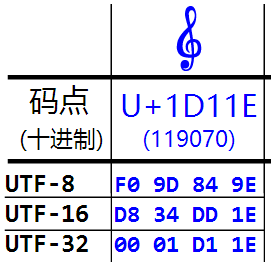
单个 char 虽然无法放置它, 但可以用两个连着的 char 放它, 这就是所谓的"代理对"了:
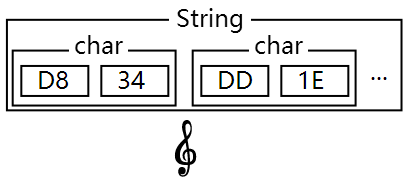
可以把它放到 String 中, 不过这么"一个"字符, 它的长度(length)却是 2:
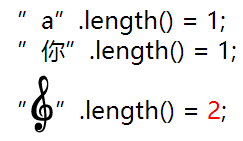
关于这些的更详细的解释, 可以参考 字符集与编码(五)–代码单元及 length 方法 中和 文本在内存中的编码(1)–乱码探源(4) 中的介绍.
字符流的局限性
那么, 由以上介绍, 我们知道了 char 的局限, 它无法跟我们用眼睛看到的"字符"划等号, 那么 Java 的字符流也会受到此局限, 它们是一脉相承的. 确切的讲, 所谓的"字符流"更准确的说法是"16 位 char 流". 比如, 如果你看一下 Reader 中 read 方法的介绍:
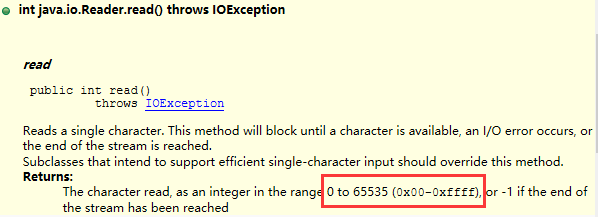
会发现, 它每 read 一下, 虽然返回是个 int, 但值的范围却是受限的, 实际上它就是返回一个 16 位的 char.
假如用一个文本文件保存着上述那个字符, 编码用 utf-8.
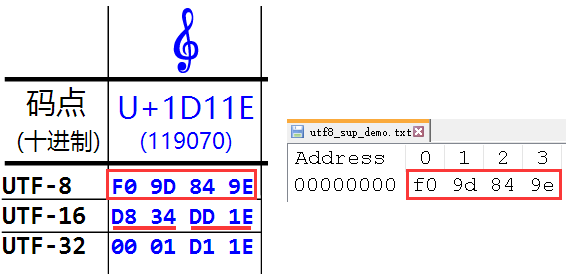
那么它的字节是 4, 如果现在用一个字符流去读取它, 那么要 read 两次:
import static org.assertj.core.api.Assertions.assertThat;
import java.io.File;
import java.io.FileNotFoundException;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.io.Reader;
import org.apache.commons.io.FileUtils;
import org.apache.commons.io.IOUtils;
import org.junit.Test;
public class ReaderTest {
/**
* 增补字符测试
*/
@Test
public void testReaderSup() {
File utf8_sup_demo = FileUtils.toFile(getClass().getResource("/encoding/utf8_sup_demo.txt"));
Reader reader = null;
try {
InputStream is = new FileInputStream(utf8_sup_demo);
reader = new InputStreamReader(is, "UTF-8");
char c = (char) reader.read();
assertThat(c).isEqualTo('\ud834');
c = (char) reader.read();
assertThat(c).isEqualTo('\udd1e');
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
IOUtils.closeQuietly(reader);
}
}
}
你可能会好奇, 这么读一下, 它到底读上来几个字节呢? 如果这个文本文件是用 utf-16 编码, 可能相对好理解一些, read 一下就是返回两字节.
但是现在是 utf-8 呢? 如果只是读取前面的 f0 9d, 是不足以转换成 d8 34 的.
事实上, 首字节 f0 的二进制为 11110000, 是以 11110 开头的, 根据 utf-8 编码规则, 读到这个字节, 就知道要一下读四个字节, 这样才算一个完整"字符(码点)", 但返回时还是分了两段, 形式上你也要 read 两次, 根源还是 char 本身的局限性.
所以, 是不是字符流读一下就能返回一个"字符"呢? 这主要具体看你怎么定义"字符"这个概念了.
组合字符(composite characters)与正规化问题(normalize)
事实上, 所谓的"一个字符"在考虑到 Unicode 中的所谓组合字符时还会更复杂一些.
比如下面有两个组合字符:
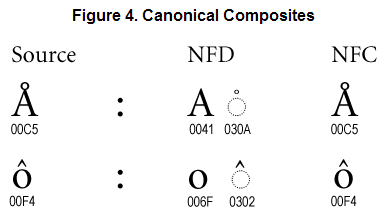
就以上面那个为例吧, 那个上面有个小圆圈的 A. 一方面, Unicode 为它单独定义了一个字符(码点), 也就是上面显示的【U+00C5】.
另一方面, 它又可以由普通的字母 A【U+0041】和一个小圆圈字符【U+030A】组合而成.
跟我们拼音上面的四声音调符号类似.
什么意思呢? 来具体看下下面的测试:
import static org.assertj.core.api.Assertions.assertThat;
import java.text.Normalizer;
import org.junit.Test;
public class UnicodeNormTest {
// https://docs.oracle.com/javase/tutorial/i18n/text/normalizerapi.html
@Test
public void testUnicodeNormalize() throws Exception {
// Å Å
System.out.println("\u00C5");
System.out.println("\u0041");
System.out.println("\u030A");
// 后两者连着输出时会发生合成
System.out.println("\u00C5 \u0041\u030A \u0041 \u030A");
}
}
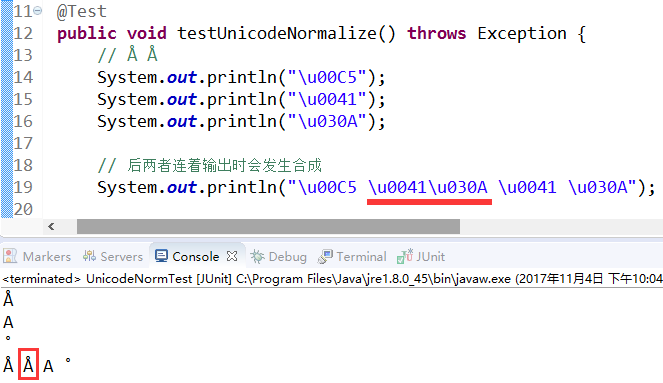
如上, 先把三个字符换行依次输出, 是三个不同的字符: 戴帽子的 A, A 以及小圆帽.
但把后两个字符(也就是普通的 A 和小圆帽)连着输出时, 它们会重叠在一起, 在眼睛看来似乎成了一个字符, 跟前面那个字符一样. 除非把它们用空格隔开, 这样它们才不会发生组合.
所以, 但我们用眼睛看到一个这样的字符时, 它的底层可能是一个字符(码点), 也可能是两个字符(码点), 这无疑会带来一些困扰, 不过 Unicode 也提供了所谓的正规化方法:
import static org.assertj.core.api.Assertions.assertThat;
import java.text.Normalizer;
import org.junit.Test;
public class UnicodeNormTest {
// https://docs.oracle.com/javase/tutorial/i18n/text/normalizerapi.html
@Test
public void testUnicodeNormalize() throws Exception {
// Å Å
System.out.println("\u00C5");
System.out.println("\u0041");
System.out.println("\u030A");
// 后两者连着输出时会发生合成
System.out.println("\u00C5 \u0041\u030A \u0041 \u030A");
// 正规化前两者是不相等的
assertThat("\u00C5".equals("\u0041\u030A")).isFalse();
assertThat("Å".equals("Å")).isFalse();
assertThat("Å".length()).isEqualTo(1);
assertThat("Å".length()).isEqualTo(2);
// 正规化后则相等
assertThat("\u00C5").isEqualTo(Normalizer.normalize("\u0041\u030A", Normalizer.Form.NFC));
}
}
如上, 如果直接比较, 结果肯定是不等的, 但经过正规化(normalize)后, 就相等了, 与我们眼睛看到的结果一致.
当然了, 虽然有这么些个方法, 但事情还是变得复杂了. 总而言之呢, 所谓的"一个字符"其实没有我们想象的那么简单, 尽管这些情况都是比较罕见的, 多数情况下你还是可以按照常规去理解, 但也应该对这些有个了解, 这也是这里介绍它们的原因.
关于字节流与字符流的话题就介绍到这里.


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









