



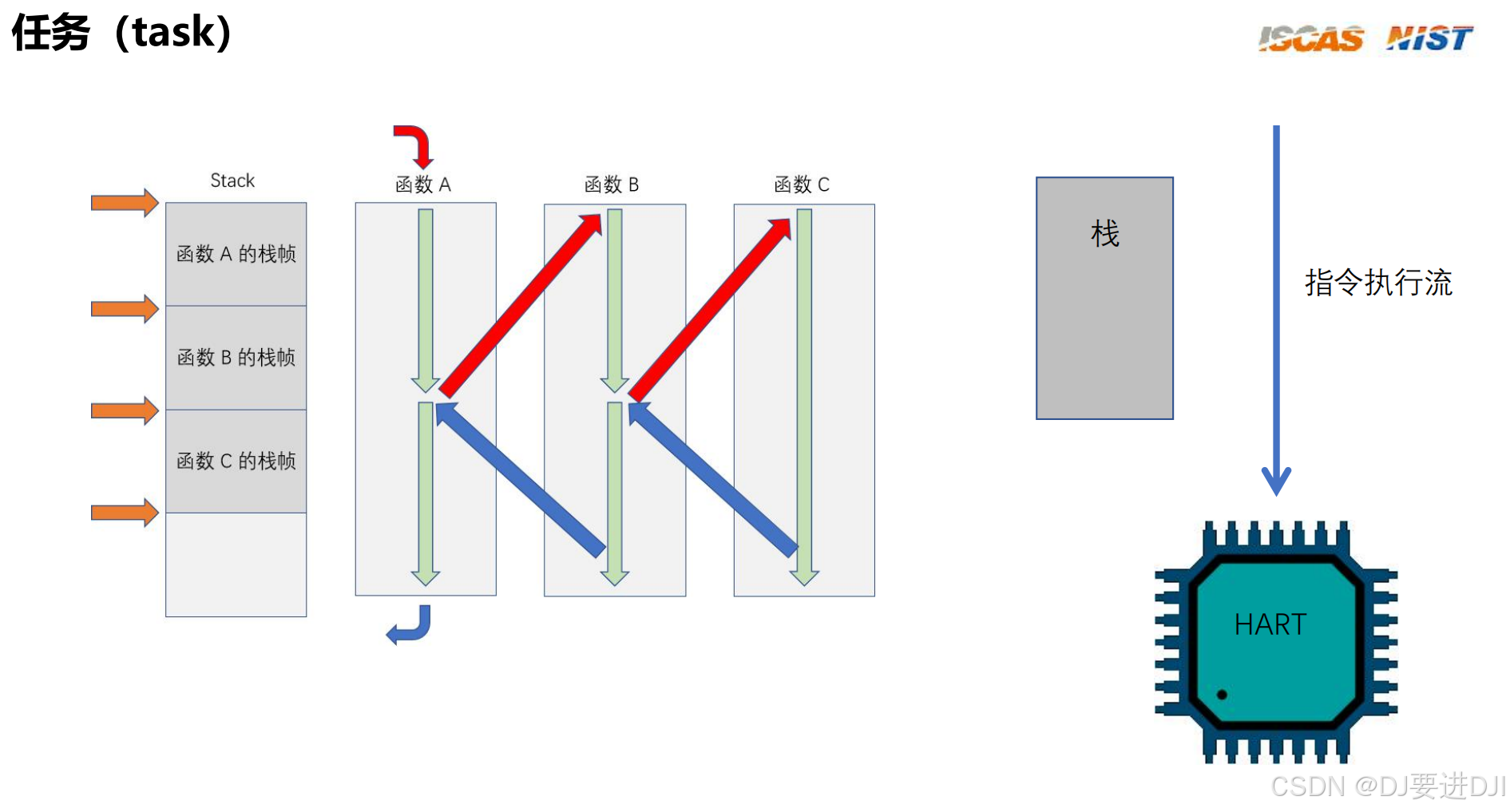
首先我们这次是做一个协作式多任务的切换,任务会自己放弃CPU从而提供给其他任务使用

一、前置知识:RISC-V 底层核心架构(上下文切换的基石)
要理解上下文切换,必须先吃透 RISC-V 的特权级、寄存器体系和指令集特性,这些是 OS 底层实现的 “地基”。
1. RISC-V 的特权级(Privilege Level)
RISC-V 定义了 4 个特权级(从高到低),本实验的内核运行在M-mode(机器模式),这是最高特权级,可访问所有资源:
| 特权级 | 缩写 | 用途 | 关键 CSR(控制状态寄存器) |
|---|---|---|---|
| 机器模式 | M-mode | 底层固件 / 内核(本实验) | mhartid、mscratch、mstatus 等 |
| 监督模式 | S-mode | 普通操作系统内核 | sscratch、sstatus、stvec 等 |
| 客户模式 | U-mode | 用户程序 | 无特权 CSR |
| 超级 visor 模式 | H-mode | 虚拟化场景 | 虚拟化相关 CSR |
因为是极简 OS,跳过 S-mode 的复杂权限管控,直接用 M-mode 实现内核,降低入门难度;但真实 OS 会用 S-mode 隔离内核和用户态。
2. RISC-V 的寄存器体系(上下文的载体)
RISC-V 的寄存器分为通用寄存器和CSR(控制状态寄存器),上下文切换的核心就是操作这两类寄存器。
(1)通用寄存器(32 个,x0~x31,32 位 / 64 位)
RISC-V 的通用寄存器有严格的功能约定(不是硬件强制,是软件调用约定),这直接决定了上下文切换时哪些寄存器需要保存:
| 寄存器别名 | 编号 | 功能 | 保存要求(上下文切换) |
|---|---|---|---|
| zero | x0 | 硬连线为 0,不可修改 | 无需保存(值固定) |
| ra | x1 | 返回地址(函数调用的返回点) | 必须保存(任务暂停的指令指针) |
| sp | x2 | 栈指针(指向栈顶,RISC-V 栈向下生长) | 必须保存(任务独立栈的标识) |
| gp | x3 | 全局指针(指向全局数据区) | 本实验未用,仅占位 |
| tp | x4 | 线程指针(本实验存 hartid) | 无需保存(全局唯一,不随任务变) |
| t0~t2 | x5~x7 | 临时寄存器(caller-saved) | 本实验选择保存(增强兼容性) |
| s0/fp | x8 | 保存寄存器 / 帧指针(callee-saved) | 必须保存(函数调用后需保留原值) |
| s1 | x9 | 保存寄存器(callee-saved) | 必须保存 |
| a0~a7 | x10~x17 | 参数 / 返回值寄存器(caller-saved) | 本实验选择保存 |
| s2~s11 | x18~x27 | 保存寄存器(callee-saved) | 必须保存 |
| t3~t6 | x28~x31 | 临时寄存器(caller-saved) | t6 特殊处理(下文详解) |
核心区别:caller-saved vs callee-saved
- caller-saved(调用者保存):如 t0~t2、a0~a7、t3~t6,函数 A 调用函数 B 时,A 需要自己保存这些寄存器的值(因为 B 可能会覆盖);
- callee-saved(被调用者保存):如 s0~s11,函数 B 调用前必须保存这些寄存器的值,返回后恢复(保证 A 的这些寄存器值不变)。
上下文切换的保存逻辑:为了 “无缝恢复任务”,即使是 caller-saved 寄存器,本实验也全部保存(除 gp/tp/x0),避免数据丢失。
caller-saved 和 callee-saved 的保存逻辑
“为什么要保存两次”,其实是对 **“保存主体” 和 “保存范围”** 理解有偏差 ——根本不是对同一批寄存器保存两次,而是两类寄存器的 “保存责任主体” 不同,咱们分两层讲:
1. 先明确 “谁的寄存器”:A 和 B 的寄存器是同一组硬件寄存器
RISC-V 的通用寄存器是CPU 的硬件资源,不是 “属于 A” 或 “属于 B” 的。比如 A 函数执行时,s0 里存的是 A 的局部变量;当调用 B 函数后,B 如果要使用 s0,就会覆盖 A 的 s0 值,导致 A 返回后 s0 的值丢失。
2. caller-saved 和 callee-saved 的 “单次保存” 责任划分
这是 RISC-V软件调用约定(不是硬件强制),目的是保证函数调用后 “关键数据不丢失”,但两类寄存器的保存责任完全不同,不存在 “保存两次 A 的上下文”:
(1)caller-saved 寄存器(t0~t2、a0~a7、t3~t6):调用者 A 保存
- 这类寄存器的特点是被调用者 B 可以随意覆盖(B 默认 A 已经保存了这些寄存器的值)。
- 场景:A 要调用 B,且 A 后续还需要用 a0 的值,那么 A 必须在调用 B前,把 a0 的值存到自己的栈里;B 执行时可以随便改 a0,A 返回后再从栈里恢复 a0 即可。
- 这里的 “保存” 是A 为自己保存,和 B 无关。
(2)callee-saved 寄存器(s0~s11):被调用者 B 保存
- 这类寄存器的特点是B 必须保证调用前后值不变(B 如果要使用 s0,必须先保存,返回前恢复)。
- 场景:A 的 s0 里存了重要的局部变量,调用 B 后,B 如果要用到 s0,必须先把 s0 当前值(A 的 s0 值)存到 B 自己的栈里;B 用完 s0 后,再从栈里恢复 s0 的值,这样 A 返回后 s0 的值还是原来的。
- 这里的 “保存” 是B 为 A 的 s 寄存器保存,不是 A 自己保存,且只保存一次。
3. 上下文切换的 “一次性保存”(和函数调用的区别)
印象里的 “只保存一次 A 的上下文” 是任务级的上下文切换,和 “函数调用的寄存器保存” 是两个场景:
- 函数调用的保存:是临时、局部的(比如 B 只保存自己要用的 s 寄存器,不用的不保存),且执行完 B 就恢复;
- 上下文切换的保存:是完整、持久的(把任务 A 的所有通用寄存器都存到 context 里),因为任务 A 会被暂停,下次恢复时需要完整的执行状态,和函数调用的 “局部保存” 本质不同。
总结:不存在 “保存两次 A 的上下文”,caller-saved 是 A 自己保自己的临时寄存器,callee-saved 是 B 帮 A 保保存寄存器,责任主体和范围都不同,是 “分工保存” 而非 “重复保存”。
(2)CSR(控制状态寄存器)
CSR 是 RISC-V 的 “特权寄存器”,用于控制 CPU 状态,本实验核心用到 3 个:
- mhartid:M-mode 的 CPU 核 ID 寄存器,多核系统中区分不同 hart,start.S 中用
csrr t0, mhartid读取; - mscratch:M-mode 的 “临时保存寄存器”,本实验用它存当前任务的 context 指针(关键!因为汇编指令不能直接访问内存,必须用通用寄存器当基址,而 mscratch 不参与任务执行,不会被覆盖);
- mstatus:M-mode 状态寄存器(本实验未直接用,但真实 OS 会用它控制中断使能、特权级切换)。
(3)RISC-V 的指令对齐要求
RISC-V 的指令地址必须 4 字节对齐(32 位指令),栈指针 sp 必须 16 字节对齐(调用约定强制要求),代码中__attribute__((aligned(16))) task_stack就是为了满足 sp 的对齐要求。
3. RISC-V 的 CSR 操作指令(上下文切换的关键指令)
操作 CSR 的指令是上下文切换的 “核心工具”,本实验用到csrr/csrw/csrrw:
| 指令 | 功能 | 示例(本实验) |
|---|---|---|
csrr rd, csr | 读 CSR 到通用寄存器 rd | csrr t6, mscratch(读 mscratch 到 t6) |
csrw csr, rs | 写通用寄存器 rs 到 CSR | csrw mscratch, a0(写 a0 到 mscratch) |
csrrw rd, csr, rs | 原子交换:先读 csr 到 rd,再写 rs 到 csr | csrrw t6, mscratch, t6(交换 t6 和 mscratch 的值) |
原子性的意义:csrrw是原子操作,不会被中断打断,保证上下文切换时 CSR 操作的完整性。
二、系统启动的底层细节(start.S + kernel.c,RISC-V M-mode 启动流程)
系统启动的每一步都和 RISC-V 的底层架构强绑定,我们逐行拆解:
1. start.S:M-mode 的硬件入口(0x80000000)
QEMU 将内核加载到0x80000000(platform.h 定义的内存布局),并从_start开始执行,这是 RISC-V 的硬件启动约定。
总的代码:
#include "platform.h" // 平台相关头文件,包含MAXNUM_CPU等硬件配置宏定义
# 每个硬件线程(hart)的栈大小为1024字节
# hart是RISC-V中硬件线程的核心单元,多核心/多线程系统中每个hart独立执行指令
.equ STACK_SIZE, 1024 // 定义栈大小常量,等价于C语言#define STACK_SIZE 1024
.global _start // 声明_start为全局符号,作为程序入口点(链接器识别的入口)
.text // 代码段开始,RISC-V汇编中.text段存放可执行指令,只读且可执行
_start:
# 暂停所有hart ID不等于0的硬件线程(仅保留hart 0执行核心逻辑)
csrr t0, mhartid # 读取当前hart的ID到t0寄存器
# csrr是RISC-V特权指令,用于读取控制状态寄存器(CSR)
# mhartid是机器模式下的hart ID寄存器,每个hart有唯一ID(从0开始)
mv tp, t0 # 将hart ID保存到tp寄存器(线程指针),供后续使用
# tp寄存器在RISC-V ABI中约定为线程私有数据指针,常用于存储hart ID/线程上下文
bnez t0, park # 如果当前hart ID非0(t0≠0),跳转到park标签处挂起
# bnez是分支指令:Branch if Not Equal to Zero
# 多核心启动时通常只让hart 0执行初始化,其余hart先挂起
# 将BSS段的所有字节清零
# BSS段用于存放未初始化的全局变量和静态变量,标准要求程序启动时必须清零
la a0, _bss_start # 加载BSS段起始地址到a0寄存器
# la是伪指令(Load Address),实际会翻译成auipc+addi组合指令
la a1, _bss_end # 加载BSS段结束地址到a1寄存器
bgeu a0, a1, 2f # 如果起始地址≥结束地址(无BSS段),跳转到2号标签(跳过清零)
# bgeu是无符号大于等于分支,2f表示向前(forward)查找2号标签
1: # 1号标签:BSS清零循环体入口
sw zero, (a0) # 将0写入a0指向的内存地址(4字节)
# sw是存储字指令(Store Word),zero寄存器恒为0
addi a0, a0, 4 # a0 += 4(指向下一个4字节地址)
bltu a0, a1, 1b # 如果a0 < a1(未清零完),跳回1号标签继续循环
# bltu是无符号小于分支,1b表示向后(backward)查找1号标签
2: # 2号标签:BSS清零完成后的执行点
# 设置栈指针(栈从高地址向低地址生长,因此将栈指针指向栈空间的末尾)
# RISC-V栈遵循满递减栈(Full Descending):sp指向最后一个已使用的栈地址,压栈时先sp-=size再存储
slli t0, t0, 10 # 将hart ID左移10位(等价于乘以1024)
# slli是逻辑左移指令(Shift Left Logical Immediate),10位对应2^10=1024
la sp, stacks + STACK_SIZE # 加载栈空间起始地址+STACK_SIZE到sp(hart 0的栈顶)
# stacks是栈空间的基地址,hart 0的栈范围:stacks ~ stacks+STACK_SIZE
# sp初始指向栈空间末尾(栈顶),符合RISC-V栈生长方向
add sp, sp, t0 # 调整sp到当前hart对应的栈顶位置
# 多hart栈空间布局:hart N的栈 = stacks + N*STACK_SIZE ~ stacks + (N+1)*STACK_SIZE
# 例如hart 1的栈顶 = stacks+STACK_SIZE + 1*STACK_SIZE
j start_kernel # hart 0跳转到C语言实现的start_kernel函数执行
# j是无条件跳转指令(Jump),跳转到全局符号start_kernel
park: # 非0号hart的挂起循环
wfi # 等待中断指令(Wait For Interrupt)
# wfi会让hart进入低功耗状态,直到有中断/异常触发才唤醒
# 挂起的hart会在此处无限循环,直到被中断唤醒
j park # 跳回park标签,持续挂起
# RISC-V标准调用约定(ABI)要求:栈指针sp必须保持16字节对齐
# 对齐要求:函数调用时sp需是16的倍数,保证浮点寄存器/向量指令的内存访问对齐
.balign 16 # 对齐指令:后续数据按16字节边界对齐
stacks: # 栈空间的基地址标签
.skip STACK_SIZE * MAXNUM_CPU # 为所有hart分配栈空间(跳过指定字节数,即预留内存)
# .skip是汇编伪指令,分配指定大小的未初始化内存
# MAXNUM_CPU是平台最大支持的hart数量(来自platform.h)
.end # 汇编文件结束标记
这里有一个小细节,就是栈不是向下生长的吗,但是代码中提到了一个问题,就是
la sp, stacks + STACK_SIZE
这句话其实是直接给所有的hart分配了栈空间,然后在把sp寄存器往上移动,回到栈的起始地址,注意这里是分配空间,而不是使用空间,因为我们分配了空间,所以要回到我们分配的空间的起始位置,所以就是往高地址+++,
la sp, stacks + STACK_SIZE // stacks是所有hart栈的起始地址,stacks+STACK_SIZE是0号hart的栈顶初始地址
add sp, sp, t0 // t0是hartid×1024(即hartid×STACK_SIZE),为每个hart分配独立栈
- 0 号 hart:t0=0 → sp=stacks+1024+0 → 对应 0 号 hart 的栈顶;
- 1 号 hart:t0=1024 → sp=stacks+1024+1024 → 对应 1 号 hart 的栈顶;
- 代码里
stacks是所有 hart 栈的起始低地址,stacks + STACK_SIZE是 0 号 hart 栈的最高地址,初始 sp 指向这里,完全符合栈向下生长的规则: - 假设
stacks的地址是0x80001000,STACK_SIZE=1024,则stacks+STACK_SIZE=0x80001400(高地址); - 0 号 hart 初始化时 sp=0x80001400(栈顶初始位置);
- 当执行压栈操作(比如保存寄存器)时,先把数据存入
sp-4=0x800013FC,再把 sp 更新为 0x800013FC(sp 递减,栈向下生长)。
(1)多核 hart 的初始化与休眠
csrr t0, mhartid // 读M-mode的hartid到t0(RISC-V架构指令,仅M-mode可访问mhartid)
mv tp, t0 // tp寄存器永久存hartid(tp是线程指针,RISC-V约定tp不随任务切换)
bnez t0, park // 非0号hart跳转到park标签,进入休眠
- 为什么只让 0 号 hart 工作? 本实验是单核 OS,多核需处理缓存一致性、锁等复杂问题,先简化为单核;
- park 标签的休眠逻辑:
park:
wfi // RISC-V的“等待中断”指令,CPU进入低功耗,直到中断唤醒(本实验0号hart不会唤醒其他hart)
j park // 无限循环,保持休眠
(2)BSS 段清零(RISC-V 数据段约定)
RISC-V 的 ELF 文件中,BSS 段是未初始化的全局变量(如task_stack),硬件不会自动清零,必须手动初始化:
la a0, _bss_start // 加载BSS段起始地址到a0(la是RISC-V的“加载地址”伪指令,实际是auipc+addi)
la a1, _bss_end // 加载BSS段结束地址到a1
bgeu a0, a1, 2f // 如果a0 >= a1(BSS为空),跳转到2:
1:
sw zero, (a0) // 把a0指向的内存写0(sw是RISC-V的“存储字”指令,32位)
addi a0, a0, 4 // 地址+4(32位系统,按字对齐)
bltu a0, a1, 1b // 未到结束地址则循环
2:
- RISC-V 的地址指令:
la是伪指令,会被汇编器转为auipc(高位地址)+addi(低位偏移),因为 RISC-V 的立即数指令范围有限,无法直接加载 32 位地址。
(3)0 号 hart 的初始栈设置(RISC-V 栈对齐要求)
slli t0, t0, 10 // t0(hartid)左移10位,等价于*1024(STACK_SIZE=1024)
la sp, stacks + STACK_SIZE // 加载栈区起始地址+栈大小到sp(sp指向栈顶,RISC-V栈向下生长)
add sp, sp, t0 // 0号hart的sp = stacks+1024 + 0,满足16字节对齐
j start_kernel // 跳转到C语言的start_kernel(RISC-V的无条件跳转指令)
- 栈的 16 字节对齐:RISC-V 调用约定强制要求 sp 必须 16 字节对齐,
stacks标签用.balign 16保证对齐,否则函数调用会出错; - stacks 的内存布局:
.balign 16
stacks:
.skip STACK_SIZE * MAXNUM_CPU // 预分配8个hart的栈空间(每个1024字节)
2. kernel.c:C 语言的内核入口(M-mode 到 C 的过渡)
start_kernel是 C 代码的起点,每一步初始化都服务于后续的任务切换,总代码:
void start_kernel(void)
{
uart_init(); // 初始化UART(RISC-V的内存映射IO,地址0x10000000,见platform.h)
uart_puts("Hello, RVOS!\n");
page_init(); // 初始化页式内存(本实验未用任务的动态内存,先忽略)
sched_init(); // 关键!初始化mscratch=0(M-mode CSR,为第一次上下文切换做准备)
os_main(); // 创建用户任务(task0和task1)
schedule(); // 触发第一次上下文切换(从内核切换到task0)
uart_puts("Would not go here!\n");// 一旦切换到任务,PC不会再回到这里(ra已被覆盖)
while (1) {};
}
- UART 的底层原理:UART 是内存映射 IO,RISC-V 通过读写
0x10000000地址的寄存器(如 THR/RHR)实现串口通信,无需专门的 IO 指令(RISC-V 是 “内存 - IO 统一编址”,区别于 x86 的独立 IO 空间)。
三、任务管理的底层实现(sched.c,RISC-V 任务的 “诞生” 与调度)
任务的创建和调度,本质是为任务分配独立的 “寄存器上下文” 和 “栈空间”,我们逐行拆解:
1. 任务栈与上下文的初始化(task_create 函数)
每个任务需要独立的栈和初始寄存器上下文,这是任务独立执行的基础:
#include "os.h" // 操作系统核心头文件,包含reg_t(寄存器类型)、context结构体等核心定义
/*
* 声明外部函数switch_to:由汇编实现的上下文切换核心函数
* 拓展:switch_to是任务调度的关键,会修改CPU的寄存器(如sp/ra),实现从当前任务切到下一个任务
* 入参:next - 下一个待执行任务的上下文结构体指针
*/
extern void switch_to(struct context *next);
// 系统最大支持的任务数(FIFO调度队列的最大长度)
#define MAX_TASKS 10
// 每个任务的栈大小:1024字节(符合RISC-V栈16字节对齐要求)
#define STACK_SIZE 1024
/*
* RISC-V标准调用约定(ABI)强制要求:栈指针sp必须始终保持16字节对齐
* __attribute__((aligned(16))):GCC属性,强制数组按16字节边界对齐
* 拓展:栈对齐保证浮点指令/向量指令的内存访问正确性,避免总线错误
*/
uint8_t __attribute__((aligned(16))) task_stack[MAX_TASKS][STACK_SIZE];
/*
* 任务上下文数组:每个元素保存一个任务的核心执行上下文
* 拓展:struct context是架构相关的结构体(通常在os.h中定义),至少包含:
* - sp:任务的栈指针(栈顶地址)
* - ra:任务的返回地址(任务入口/切出时的执行点)
* 还可能包含通用寄存器(a0-a7/t0-t6)、状态寄存器(mstatus)等
*/
struct context ctx_tasks[MAX_TASKS];
/*
* 静态全局变量:调度器核心状态
* _top:标记ctx_tasks中已创建任务的最大下标(也表示当前总任务数)
* _current:指向当前正在执行的任务在ctx_tasks中的下标(初始-1表示无任务)
*/
static int _top = 0;
static int _current = -1;
/*
* 写RISC-V机器模式的mscratch寄存器
* 拓展:mscratch(Machine Scratch Register)是RISC-V机器模式专用寄存器:
* 1. 用于保存临时数据(机器模式下中断/异常处理时,避免覆盖通用寄存器)
* 2. 通常存放当前任务的上下文指针或中断栈地址
* 入参:x - 要写入mscratch的数值
*/
static void w_mscratch(reg_t x)
{
// 内联汇编实现CSR写操作:csrw(Control and Status Register Write)
// 格式:asm volatile("指令模板" : 输出约束 : 输入约束 : 破坏列表)
// "r"(x):表示将变量x放入通用寄存器,作为输入传递给汇编指令
asm volatile("csrw mscratch, %0" : : "r" (x));
}
/*
* 调度器初始化函数
* 功能:初始化调度器核心状态,清空mscratch寄存器(初始无任务)
* 调用时机:系统启动时(hart 0初始化完成后)
*/
void sched_init()
{
w_mscratch(0); // 将mscratch置0,表示当前无任务上下文关联
}
/*
* 实现简单的循环FIFO(先进先出)调度器
* 核心逻辑:按任务创建顺序循环执行,无优先级,属于非抢占式调度
* 拓展:FIFO调度是最基础的调度算法,优点是简单、无饥饿问题,缺点是响应性差
*/
void schedule()
{
// 边界检查:如果无已创建的任务,触发panic(系统致命错误)
if (_top <= 0) {
panic("Num of task should be greater than zero!"); // panic是OS核心函数,终止系统并打印错误
return;
}
// 计算下一个要执行的任务下标:循环取模(实现FIFO循环)
// 例如:_current=2, _top=3 → 下一个=3%3=0;_current=0, _top=3 → 下一个=1
_current = (_current + 1) % _top;
// 获取下一个任务的上下文指针
struct context *next = &(ctx_tasks[_current]);
// 跳转到汇编实现的上下文切换函数,切换到next任务执行
// 拓展:switch_to执行时会保存当前任务上下文,恢复next任务的寄存器(sp/ra等)
switch_to(next);
}
/*
* 【任务创建接口】
* 功能:创建一个新任务,初始化其上下文(栈指针、入口地址)
* 入参:start_routin - 任务的入口函数(无参无返回值)
* 返回值:0-成功;-1-失败(任务数达到上限)
* 拓展:任务创建的核心是初始化上下文,让调度器能找到任务的执行起点和栈空间
*/
int task_create(void (*start_routin)(void))
{
// 检查是否还有空闲任务槽位(未达到最大任务数)
if (_top < MAX_TASKS) {
/*
* 初始化新任务的栈指针:指向任务栈的末尾(栈顶)
* RISC-V栈是满递减栈(Full Descending):
* - 栈空间范围:task_stack[_top][0] ~ task_stack[_top][STACK_SIZE-1]
* - sp初始指向栈末尾(最高地址),压栈时先sp-=size再存储数据
*/
ctx_tasks[_top].sp = (reg_t) &task_stack[_top][STACK_SIZE];
/*
* 初始化新任务的返回地址:指向任务入口函数
* 拓展:ra寄存器在RISC-V中保存函数返回地址,此处设置ra为任务入口,
* 当switch_to恢复ra后,ret指令会跳转到start_routin执行
*/
ctx_tasks[_top].ra = (reg_t) start_routin;
// 任务数+1(_top既是下标也是任务总数)
_top++;
return 0; // 创建成功
} else {
return -1; // 任务数达到上限,创建失败
}
}
/*
* 【任务主动让出CPU接口】
* 功能:当前任务主动放弃CPU使用权,触发调度器切换到下一个任务
* 拓展:属于非抢占式调度的核心接口,任务需主动调用才能切换,
* 抢占式调度则由定时器中断触发schedule()
*/
void task_yield()
{
// 调用调度器,切换到下一个任务
schedule();
}
/*
* 【简单的任务延时函数】
* 功能:通过忙等消耗CPU周期,实现粗略的延时(无定时器中断时的临时方案)
* 入参:count - 延时计数(越大延时越长)
* 拓展:
* 1. volatile关键字:防止编译器优化掉空循环(编译器会认为count未被使用,直接删除循环)
* 2. 忙等缺点:CPU利用率100%,无低功耗,实际OS中应使用定时器中断+休眠
* 3. count *= 50000:放大计数,让延时效果更明显(适配不同主频的CPU)
*/
void task_delay(volatile int count)
{
count *= 50000;
while (count--); // 空循环消耗CPU
}
// 预分配10个任务的栈,每个1024字节,16字节对齐(满足RISC-V调用约定)
uint8_t __attribute__((aligned(16))) task_stack[MAX_TASKS][STACK_SIZE];
// 每个任务的上下文(寄存器快照)
struct context ctx_tasks[MAX_TASKS];
static int _top = 0; // 已创建任务数
static int _current = -1;// 当前运行的任务ID
int task_create(void (*start_routin)(void))
{
if (_top < MAX_TASKS) {
// 关键1:设置任务的sp(栈指针),指向栈的最末端(栈向下生长,初始栈顶在高地址)
ctx_tasks[_top].sp = (reg_t) &task_stack[_top][STACK_SIZE];
// 关键2:设置任务的ra(返回地址),指向任务的入口函数(如user_task0)
ctx_tasks[_top].ra = (reg_t) start_routin;
_top++;
return 0;
} else {
return -1;
}
}
- RISC-V 栈的生长方向:栈从高地址向低地址生长,因此初始 sp 要指向
task_stack[_top][STACK_SIZE](栈的最高地址),任务执行时 sp 会逐渐减小; - ra 的底层意义:ra 寄存器保存的是函数的返回地址,这里把 ra 设为任务入口函数的地址,当第一次切换到该任务时,
ret指令会跳转到 ra 指向的地址(即任务开始执行)。
2. 调度器的底层逻辑(schedule 函数)
调度器的核心是选择下一个任务的上下文,并调用switch_to完成寄存器的切换:
void schedule()
{
if (_top <= 0) panic("任务数不能为0");
// 循环调度(FIFO):_current从-1→0→1→0→1...(取模实现循环)
_current = (_current + 1) % _top;
struct context *next = &ctx_tasks[_current];
switch_to(next); // 核心:切换到next任务的上下文(汇编实现)
}
- 为什么用 FIFO 调度? 协作式多任务的调度策略很简单,因为任务会主动调用
task_yield让出 CPU,无需复杂的优先级调度; - _current 的初始值 - 1:第一次调度时,
_current+1=0,切换到 task0,符合任务创建顺序。
3. 协作式多任务的核心(task_yield 函数)
协作式多任务的本质是任务主动放弃 CPU,task_yield是任务 “主动让权” 的接口:
void task_yield()
{
schedule(); // 调用调度器,触发上下文切换
}
- 协作式的底层局限性:如果任务不调用
task_yield(比如死循环),会永久霸占 CPU,其他任务无法执行;真实 OS 会用抢占式多任务(通过定时器中断强制切换),这需要 RISC-V 的mtvec(中断向量表)和mstatus(中断使能)支持,后续可扩展学习。
四、上下文切换的底层核心(entry.S,RISC-V 汇编的逐行精解)
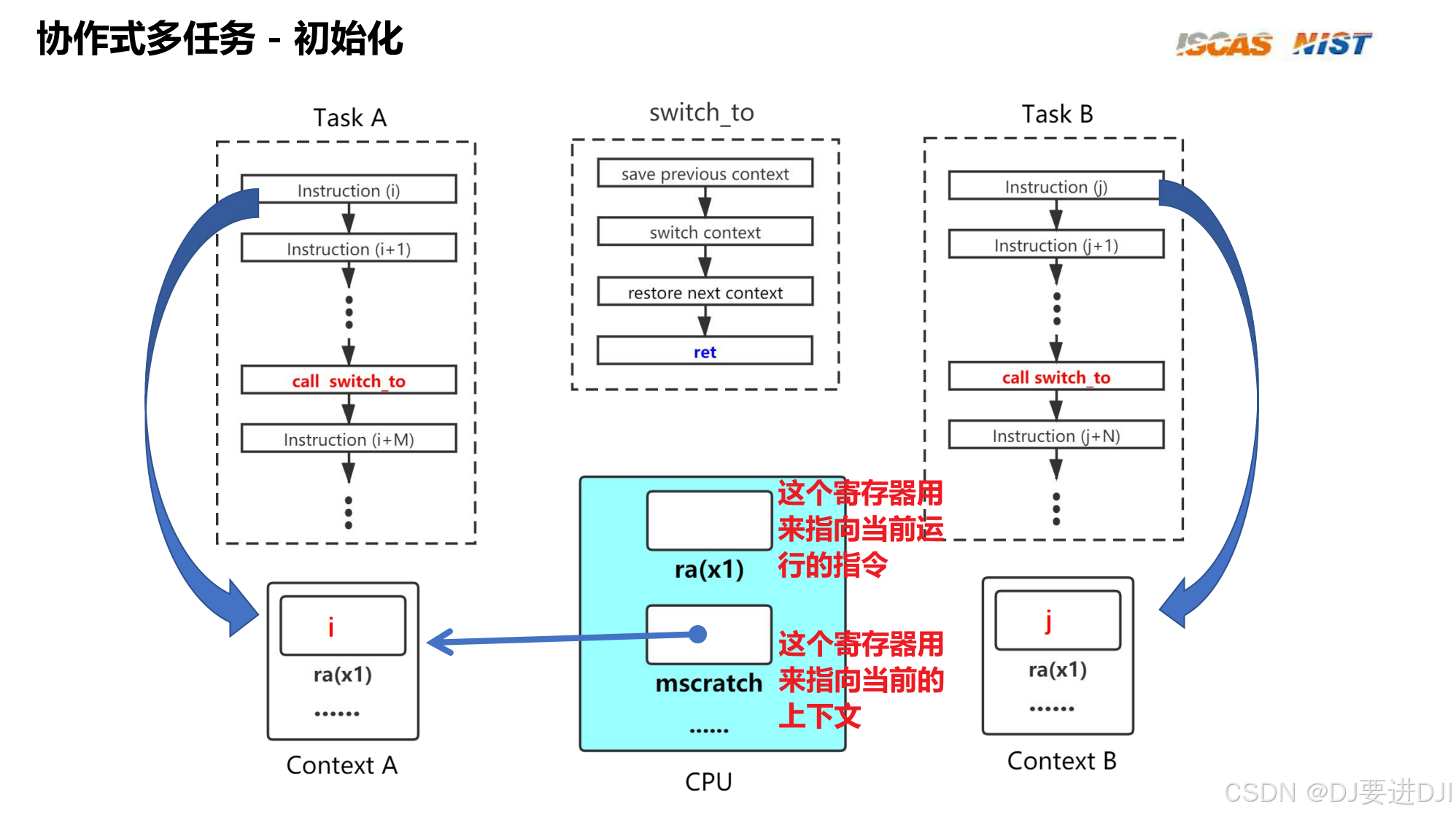
switch_to是整个实验的最核心、最底层的函数,用 RISC-V 汇编实现寄存器的 “保存” 与 “恢复”,我们逐行拆解,结合 RISC-V 架构原理分析:
1. 先理解两个核心宏(reg_save/reg_restore)
这两个宏是批量操作寄存器的 “工具”,本质是把通用寄存器按固定偏移存入 / 读出 context 结构体,先看struct context的内存布局(和宏的偏移严格对应):
| struct context 成员 | 偏移(字节) | reg_save/restore 的操作 | 对应 RISC-V 寄存器 |
|---|---|---|---|
| ra | 0*4=0 | STORE ra, 0*SIZE_REG(base) | x1 |
| sp | 1*4=4 | STORE sp, 1*SIZE_REG(base) | x2 |
| gp | 2*4=8 | 未操作(本实验不用) | x3 |
| tp | 3*4=12 | 未操作(全局唯一) | x4 |
| t0 | 4*4=16 | STORE t0,4*SIZE_REG(base) | x5 |
| ...(中间寄存器省略) | ... | ... | ... |
| t6 | 30*4=120 | 单独保存(reg_save 未处理) | x31 |
总的代码:
# 宏定义:统一内存访问指令和寄存器宽度
# LOAD:定义为lw(Load Word),4字节加载指令(适配32位RISC-V)
# STORE:定义为sw(Store Word),4字节存储指令
# SIZE_REG:通用寄存器宽度(4字节,对应RV32架构;若为RV64则改为8,指令换为ld/sd)
#define LOAD lw
#define STORE sw
#define SIZE_REG 4
# 宏:将除gp、tp外的所有通用寄存器(GP)保存到上下文结构体
# 功能等价于C代码:
# struct context *base = &ctx_task; // base是上下文结构体指针(传入的参数)
# base->ra = ra; // 依次保存各寄存器到上下文的对应偏移位置
# ......
# 拓展说明:
# 1. 不保存gp(全局指针)和tp(线程指针)的原因:
# - gp:用于访问全局数据区,系统中所有任务共享,无需任务间切换
# - tp:RVOS中固定存储hartid(硬件线程ID),全局唯一且不会变化
# 2. RISC-V寄存器分类(ABI约定):
# - 调用者保存寄存器(t0-t6/a0-a7):函数调用时由调用者保存,上下文切换必须保存
# - 被调用者保存寄存器(s0-s11):函数调用时由被调用者保存,上下文切换也需保存
# - 特殊寄存器(ra/sp/gp/tp):ra/sp是任务执行核心,必须保存;gp/tp无需保存
.macro reg_save base
# 按上下文结构体的偏移顺序保存寄存器,偏移=序号*4字节
STORE ra, 0*SIZE_REG(\base) # ra(x1):返回地址,偏移0
STORE sp, 1*SIZE_REG(\base) # sp(x2):栈指针,偏移4
# 跳过x3(gp)、x4(tp),无偏移2、3
STORE t0, 4*SIZE_REG(\base) # t0(x5):临时寄存器,偏移16
STORE t1, 5*SIZE_REG(\base) # t1(x6):临时寄存器,偏移20
STORE t2, 6*SIZE_REG(\base) # t2(x7):临时寄存器,偏移24
STORE s0, 7*SIZE_REG(\base) # s0(x8):保存寄存器,偏移28
STORE s1, 8*SIZE_REG(\base) # s1(x9):保存寄存器,偏移32
STORE a0, 9*SIZE_REG(\base) # a0(x10):参数/返回值寄存器,偏移36
STORE a1, 10*SIZE_REG(\base) # a1(x11):参数寄存器,偏移40
STORE a2, 11*SIZE_REG(\base) # a2(x12):参数寄存器,偏移44
STORE a3, 12*SIZE_REG(\base) # a3(x13):参数寄存器,偏移48
STORE a4, 13*SIZE_REG(\base) # a4(x14):参数寄存器,偏移52
STORE a5, 14*SIZE_REG(\base) # a5(x15):参数寄存器,偏移56
STORE a6, 15*SIZE_REG(\base) # a6(x16):参数寄存器,偏移60
STORE a7, 16*SIZE_REG(\base) # a7(x17):参数寄存器,偏移64
STORE s2, 17*SIZE_REG(\base) # s2(x18):保存寄存器,偏移68
STORE s3, 18*SIZE_REG(\base) # s3(x19):保存寄存器,偏移72
STORE s4, 19*SIZE_REG(\base) # s4(x20):保存寄存器,偏移76
STORE s5, 20*SIZE_REG(\base) # s5(x21):保存寄存器,偏移80
STORE s6, 21*SIZE_REG(\base) # s6(x22):保存寄存器,偏移84
STORE s7, 22*SIZE_REG(\base) # s7(x23):保存寄存器,偏移88
STORE s8, 23*SIZE_REG(\base) # s8(x24):保存寄存器,偏移92
STORE s9, 24*SIZE_REG(\base) # s9(x25):保存寄存器,偏移96
STORE s10, 25*SIZE_REG(\base) # s10(x26):保存寄存器,偏移100
STORE s11, 26*SIZE_REG(\base) # s11(x27):保存寄存器,偏移104
STORE t3, 27*SIZE_REG(\base) # t3(x28):临时寄存器,偏移108
STORE t4, 28*SIZE_REG(\base) # t4(x29):临时寄存器,偏移112
STORE t5, 29*SIZE_REG(\base) # t5(x30):临时寄存器,偏移116
# 注意:此处未保存t6(x31),因为t6被用作base(上下文指针)
# t6的保存需要在reg_save宏外部单独处理,避免覆盖base导致地址错误
.endm
# 宏:从上下文结构体恢复除gp、tp外的所有通用寄存器
# 功能与reg_save相反:将上下文数据加载回对应寄存器
# struct context *base = &ctx_task;
# ra = base->ra;
# ......
.macro reg_restore base
# 按偏移顺序恢复寄存器,与reg_save一一对应
LOAD ra, 0*SIZE_REG(\base) # 恢复返回地址ra
LOAD sp, 1*SIZE_REG(\base) # 恢复栈指针sp(核心:切换任务栈)
LOAD t0, 4*SIZE_REG(\base) # 恢复临时寄存器t0
LOAD t1, 5*SIZE_REG(\base) # 恢复t1
LOAD t2, 6*SIZE_REG(\base) # 恢复t2
LOAD s0, 7*SIZE_REG(\base) # 恢复保存寄存器s0
LOAD s1, 8*SIZE_REG(\base) # 恢复s1
LOAD a0, 9*SIZE_REG(\base) # 恢复参数寄存器a0
LOAD a1, 10*SIZE_REG(\base) # 恢复a1
LOAD a2, 11*SIZE_REG(\base) # 恢复a2
LOAD a3, 12*SIZE_REG(\base) # 恢复a3
LOAD a4, 13*SIZE_REG(\base) # 恢复a4
LOAD a5, 14*SIZE_REG(\base) # 恢复a5
LOAD a6, 15*SIZE_REG(\base) # 恢复a6
LOAD a7, 16*SIZE_REG(\base) # 恢复a7
LOAD s2, 17*SIZE_REG(\base) # 恢复s2
LOAD s3, 18*SIZE_REG(\base) # 恢复s3
LOAD s4, 19*SIZE_REG(\base) # 恢复s4
LOAD s5, 20*SIZE_REG(\base) # 恢复s5
LOAD s6, 21*SIZE_REG(\base) # 恢复s6
LOAD s7, 22*SIZE_REG(\base) # 恢复s7
LOAD s8, 23*SIZE_REG(\base) # 恢复s8
LOAD s9, 24*SIZE_REG(\base) # 恢复s9
LOAD s10, 25*SIZE_REG(\base) # 恢复s10
LOAD s11, 26*SIZE_REG(\base) # 恢复s11
LOAD t3, 27*SIZE_REG(\base) # 恢复t3
LOAD t4, 28*SIZE_REG(\base) # 恢复t4
LOAD t5, 29*SIZE_REG(\base) # 恢复t5
LOAD t6, 30*SIZE_REG(\base) # 恢复t6(x31),偏移120(30*4)
.endm
# 保存/恢复寄存器的关键注意事项:
# 1. 使用mscratch寄存器存储当前任务的上下文指针:
# mscratch是RISC-V机器模式专用CSR,用于临时存储数据,不会被普通指令覆盖
# 2. 使用t6作为reg_save/reg_restore的base(上下文指针):
# - t6是通用寄存器中编号最大的(x31),加载/存储过程中不会被其他指令覆盖
# - 注意:CSR寄存器(如mscratch)不能作为load/store指令的基址寄存器,
# 因此必须先将mscratch的值换到通用寄存器(t6)中才能使用
.text # 代码段开始,存放可执行指令
# 全局函数:void switch_to(struct context *next);
# 功能:上下文切换核心函数,将CPU从当前任务切换到next任务
# 入参约定(RISC-V ABI):a0寄存器存放next指针(下一个任务的上下文地址)
.globl switch_to # 声明为全局符号,供C代码调用
.balign 4 # 指令按4字节对齐(RISC-V指令固定4字节)
switch_to:
# 核心步骤1:交换t6和mscratch的值(csrrw=CSR Read and Write)
# 指令功能:先将mscratch的当前值读入t6,再将t6的原值写入mscratch
# 作用:t6现在指向“当前任务”的上下文指针(mscratch中存储的旧值)
csrrw t6, mscratch, t6
# 核心步骤2:处理第一次调用switch_to的特殊情况
# beqz t6, 1f:如果t6为0(第一次调用),跳转到1号标签
# 背景:sched_init()中初始化mscratch为0,第一次调用时csrrw会让t6=0,
# 此时无“前一个任务”需要保存,直接跳转到恢复新任务的逻辑
beqz t6, 1f
# 核心步骤3:保存前一个任务的上下文(非第一次调用时执行)
# reg_save t6:将当前CPU的所有通用寄存器保存到t6指向的上下文(前一个任务)
reg_save t6
# 核心步骤4:单独保存t6寄存器(因为reg_save中未保存)
mv t5, t6 # t5暂存当前任务的上下文指针(避免被覆盖)
csrr t6, mscratch # 从mscratch中读回t6的原始值(交换前的t6)
STORE t6, 30*SIZE_REG(t5) # 将t6的值保存到当前任务上下文的t6偏移位置
1: # 1号标签:恢复下一个任务的上下文
# 核心步骤5:更新mscratch为下一个任务的上下文指针
# csrw:将a0(next指针)写入mscratch,后续切换时可通过mscratch获取新任务上下文
csrw mscratch, a0
# 核心步骤6:恢复下一个任务的所有寄存器
mv t6, a0 # t6指向新任务的上下文指针(a0=next)
reg_restore t6 # 从t6指向的上下文恢复所有通用寄存器
# 关键:恢复sp(栈指针)后,CPU的栈已切换到新任务;恢复ra后,ret会跳转到新任务的执行点
# 核心步骤7:完成上下文切换(ret指令)
# ret等价于jr ra:跳转到ra寄存器指向的地址(新任务的入口/切出时的执行点)
# 此时ra已被reg_restore恢复为新任务的返回地址,执行ret即切换到新任务运行
ret
.end # 汇编文件结束
当前任务A → switch_to(next=B) → 任务B执行
├─ 保存A的寄存器到A的上下文(mscratch→t6→reg_save)
├─ 更新mscratch为B的上下文指针
├─ 从B的上下文恢复所有寄存器(包括sp/ra)
└─ ret跳转到B的ra地址,B开始执行
(1)reg_save 宏(保存寄存器到 context)
.macro reg_save base // base是context结构体的指针(通用寄存器)
STORE ra, 0*SIZE_REG(\base) // ra存入base+0
STORE sp, 1*SIZE_REG(\base) // sp存入base+4
STORE t0, 4*SIZE_REG(\base) // t0存入base+16(跳过gp/tp的偏移2/3)
STORE t1, 5*SIZE_REG(\base) // t1存入base+20
...(中间寄存器省略)
STORE t5, 29*SIZE_REG(\base) // t5存入base+116
# 不保存t6:因为t6被用作base,保存t6会覆盖base,需单独处理
.endm
- 为什么跳过 gp/tp? gp 本实验未用,tp 存 hartid(全局不变),无需保存,因此宏中跳过偏移 2 和 3 的位置;
- t6 的特殊处理:t6 被用作 base(context 指针),如果在宏中保存 t6,会把 base 的值覆盖,因此需要在宏外单独保存。
(2)reg_restore 宏(从 context 恢复寄存器)
.macro reg_restore base
LOAD ra, 0*SIZE_REG(\base) // 从base+0恢复ra
LOAD sp, 1*SIZE_REG(\base) // 从base+4恢复sp
LOAD t0, 4*SIZE_REG(\base) // 从base+16恢复t0
...(中间寄存器省略)
LOAD t6, 30*SIZE_REG(\base) // 从base+120恢复t6(单独处理的t6)
.endm
- 恢复顺序的意义:恢复顺序和保存顺序一致,保证寄存器的值和暂停时完全相同;t6 在最后恢复,避免覆盖 base。
2. switch_to 函数的逐行拆解(结合 RISC-V 架构)
函数原型:void switch_to(struct context *next),RISC-V 调用约定中,函数参数通过a0寄存器传递,因此a0是下一个任务的 context 指针。
.globl switch_to // 声明为全局函数,供C语言调用
.balign 4 // 指令4字节对齐(RISC-V强制要求)
switch_to:
# 步骤1:原子交换t6和mscratch的值(核心!获取当前任务的context指针)
csrrw t6, mscratch, t6 // 1. 读mscratch到t6;2. 写原t6到mscratch;原子操作
beqz t6, 1f // 如果t6=0(第一次切换,mscratch初始为0),跳转到1:标签
- 第一次切换的特殊情况:
sched_init()把 mscratch 设为 0,因此第一次执行csrrw后 t6=0,直接跳过 “保存上一个任务上下文” 的步骤(因为还没有任务需要保存)。
# 步骤2:保存上一个任务的上下文(非第一次切换时执行)
reg_save t6 // 调用宏,把上一个任务的寄存器保存到t6指向的context
mv t5, t6 // t5暂存上一个任务的context指针(防止t6被覆盖)
csrr t6, mscratch // 从mscratch读回原t6的值(步骤1交换的原t6)
STORE t6, 30*SIZE_REG(t5) // 单独保存t6到context的30*4=120偏移处(reg_save未处理)
- 为什么要单独保存 t6? 步骤 1 中 t6 被替换为 mscratch 的值(context 指针),原 t6 的值被存到 mscratch,因此需要读回并单独保存,保证 t6 寄存器的快照完整。
1:
# 步骤3:更新mscratch为下一个任务的context指针
csrw mscratch, a0 // mscratch现在指向next任务的context(后续切换时可通过mscratch获取)
# 步骤4:恢复下一个任务的上下文
mv t6, a0 // t6指向next任务的context(作为reg_restore的base)
reg_restore t6 // 调用宏,从context恢复所有寄存器(包括t6)
# 步骤5:完成切换,跳转到next任务的ra地址
ret // RISC-V的ret指令:PC = ra(next任务的ra是入口函数/暂停点)
- ret 指令的底层作用:ret 指令会把 ra 寄存器的值加载到 PC(程序计数器),从而让 CPU 执行 next 任务的指令:
- 第一次切换时:next 任务的 ra 是
user_task0的地址,ret 后 PC 跳转到 user_task0,task0 开始执行; - 非第一次切换时:next 任务的 ra 是上次暂停时的地址(如 task0 的 task_yield 之后),ret 后 task0 从暂停点继续执行。
- 第一次切换时:next 任务的 ra 是
3. 上下文切换的完整内存映射(以 task0→task1 为例)
假设 task0 的 context 在内存0x80010000,task1 的 context 在0x80010100,切换时的内存变化:
- 保存 task0 的 ra(
user_task0中 task_yield 的下一条指令地址)到0x80010000; - 保存 task0 的 sp(
task_stack[0][1024]的当前值)到0x80010004; - 其他寄存器依次存入
0x80010008~0x80010078; - 恢复 task1 的 ra(
user_task1的暂停点)到 ra 寄存器; - 恢复 task1 的 sp 到 sp 寄存器;
- ret 指令让 PC=ra,task1 开始执行。

















 672
672

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









