







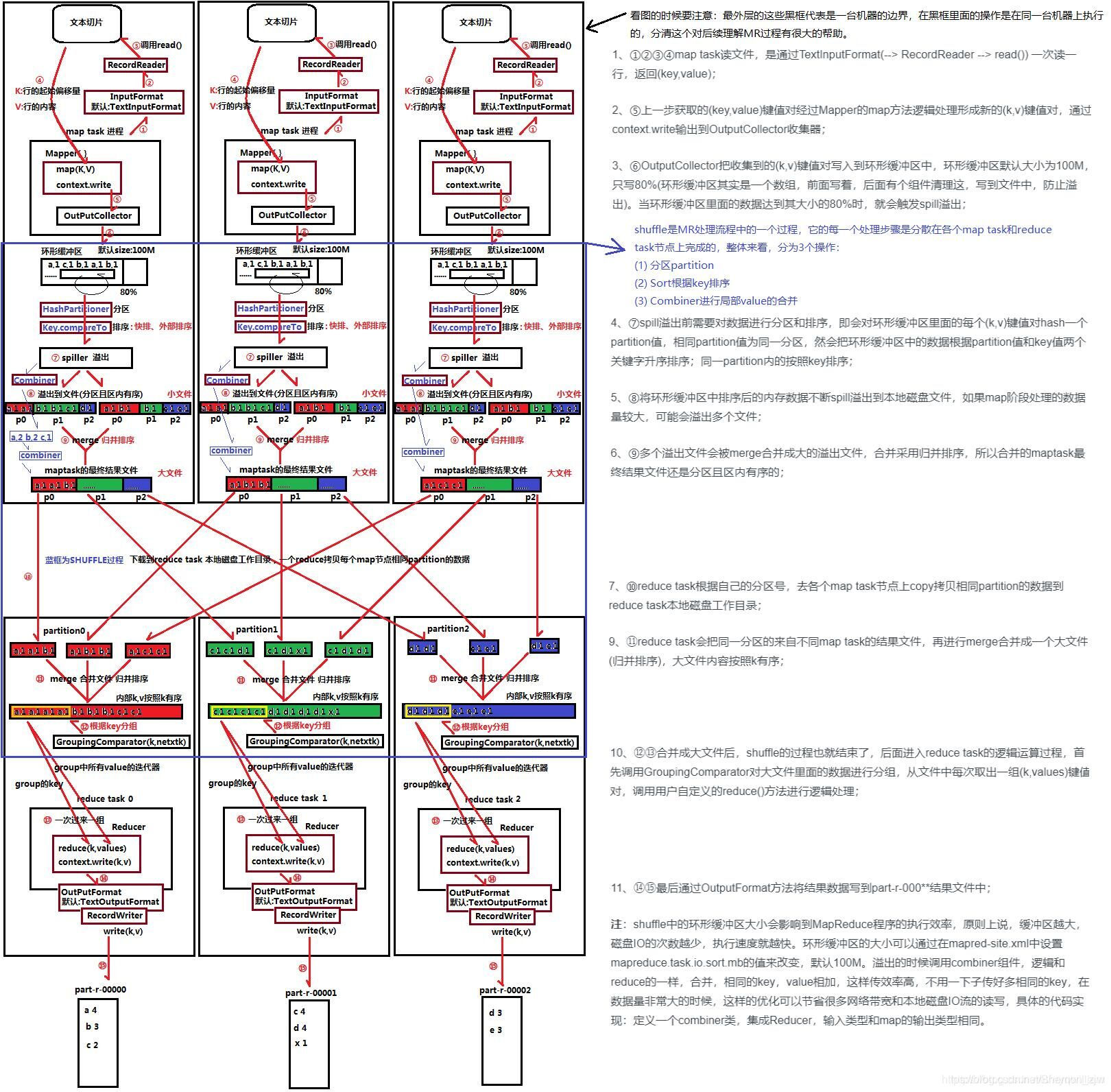
MapReduce一共分为map和reduce两个阶段
(1234)map task流程是通过TextInputFormat->RecordReadeer->read()一次读一行,返回到(key,value)
(5)获取(key,value)单行数据,进行数据分割,生成新的(key,value),通过context.write()把新的(key,value)输出到OutpuCollector收集器中。
(6789)OutputCollector会把(key,value)放入缓冲区如果缓冲区的数据超出容量的80%它会溢出spiller(默认100M)在此期间会对(key,value)进行分区、排序。同个分区内通过compareTo根据key对其进行排序,可以自定义规则。
将分区中有序的(key,value)进行合并到一个大集合中,map task数据存放到一个大文件中。
(10)map task中的分区为partition()的文件集合到一起
(11)merge合并文件并归排序,task中所有数据合并到一个文件中
(12)通过GroupingComparator(key,value)根据key进行分组,把group中所有的value放入到一个迭代器,key为键,value为key所有值的迭代器。
(13)reduce阶段,对group之后传递的每一组(key,values)进行reduce()方法统计,并生成新的(key,value)以context.write输出。
(14)reduce输出的结果保存在TextOutPutFormat中
(15)通过RecrdWriter调用write(key,value)方法,把(key,value)输出到文件中
- 以我自己的理解来说
MapReduce流程:input->Splitting->Mapping->Combine->Shuffling->Reducing-> result - Mapreduce程序读取的数据,都是存储在HDFS的数据,最后的结果也是要保存在HDFS中,因此,MapReduce要解决的第一个问题就是数据的切分问题。
MapReduce采用‘分而治之’的思想,把对大规模数据集的操作,分发给一个主节点管理下的各个分节点共同完成,然后通过整合各个节点的中间结果,得到最终结果。简单地说,MapReduce就是"任务的分解与结果的汇总"。
- 假设一个文件Document有三行英文单词作为 MapReduce 的Input(输入),这里经过 Splitting过程把文件分割为3块。分割后的3块数据就可以并行处理,每一块交给一个 map 线程处理。
- 每个map线程中,以每个单词为key,以1作为词频数value,然后输出。
- 每个map的输出都会交给一个Combine先行统计汇总,然后输出。
- 每个Combine的输出要经过shuffling(混洗),将相同的单词key放在一个桶里面,然后交给reduce处理。
- reduce接受到shuffle后的数据,会将相同的单词进行合并,得到每个单词的词频数,最后将统计好的每个单词的词频数作为输出结果。
- 上述就是 MapReduce 的大致流程,前两步可以看做map阶段,后两步可以看做reduce 阶段。














 3949
3949











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









