







谈谈 Redis 主从复制模式
第一次主从节点同步是全量复制
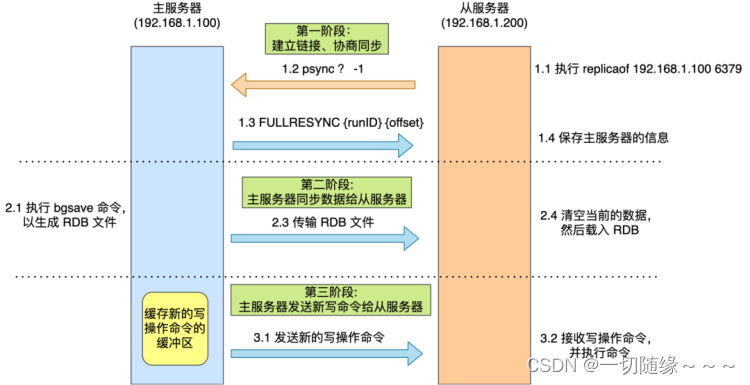
接下来,我在具体介绍每一个阶段都做了什么。
第一阶段:建立链接、协商同步
执行了 replicaof 命令后,从服务器就会给主服务器发送 psync 命令,表示要进行数据同步。
psync 命令包含两个参数,分别是主服务器的 runID 和复制进度 offset。
● runID,每个 Redis 服务器在启动时都会自动生产一个随机的 ID 来唯一标识自己。当从服务器和主服务器第一次同步时,因为不知道主服务器的 run ID,所以将其设置为 “?”。
● offset,表示复制的进度,第一次同步时,其值为 -1。
主服务器收到 psync 命令后,会用 FULLRESYNC 作为响应命令返回给对方。
并且这个响应命令会带上两个参数:主服务器的 runID 和主服务器目前的复制进度 offset。从服务器收到响应后,会记录这两个值。
FULLRESYNC 响应命令的意图是采用全量复制的方式,也就是主服务器会把所有的数据都同步给从服务器。
所以,第一阶段的工作时为了全量复制做准备。
那具体怎么全量同步呀呢?我们可以往下看第二阶段。
第二阶段:主服务器同步数据给从服务器
接着,主服务器会执行 bgsave 命令来生成 RDB 文件,然后把文件发送给从服务器。
从服务器收到 RDB 文件后,会先清空当前的数据,然后载入 RDB 文件。
这里有一点要注意,主服务器生成 RDB 这个过程是不会阻塞主线程的,因为 bgsave 命令是产生了一个子进程来做生成 RDB 文件的工作,是异步工作的,这样 Redis 依然可以正常处理命令。
但是,这期间的写操作命令并没有记录到刚刚生成的 RDB 文件中,这时主从服务器间的数据就不一致了。
那么为了保证主从服务器的数据一致性,主服务器在下面这三个时间间隙中将收到的写操作命令,写入到 replication buffer 缓冲区里:
● 主服务器生成 RDB 文件期间;
● 主服务器发送 RDB 文件给从服务器期间;
● 「从服务器」加载 RDB 文件期间;
第三阶段:主服务器发送新写操作命令给从服务器
在主服务器生成的 RDB 文件发送完,从服务器收到 RDB 文件后,丢弃所有旧数据,将 RDB 数据载入到内存。完成 RDB 的载入后,会回复一个确认消息给主服务器。
接着,主服务器将 replication buffer 缓冲区里所记录的写操作命令发送给从服务器,从服务器执行来自主服务器 replication buffer 缓冲区里发来的命令,这时主从服务器的数据就一致了。
至此,主从服务器的第一次同步的工作就完成了。
从服务器在完成第一次同步后,双方之间就会维护一个 TCP 连接。
后续主服务器可以通过这个连接继续将写操作命令传播给从服务器,然后从服务器执行该命令,使得与主服务器的数据库状态相同。
而且这个连接是长连接的,目的是避免频繁的 TCP 连接和断开带来的性能开销。
上面的这个过程被称为基于长连接的命令传播,通过这种方式来保证第一次同步后的主从服务器的数据一致性。
分摊主服务器的压力
在前面的分析中,我们可以知道主从服务器在第一次数据同步的过程中,主服务器会做两件耗时的操作:生成 RDB 文件和传输 RDB 文件。
主服务器是可以有多个从服务器的,如果从服务器数量非常多,而且都与主服务器进行全量同步的话,就会带来两个问题:
● 由于是通过 bgsave 命令来生成 RDB 文件的,那么主服务器就会忙于使用 fork() 创建子进程,如果主服务器的内存数据非大,在执行 fork() 函数时是会阻塞主线程的,从而使得 Redis 无法正常处理请求;
● 传输 RDB 文件会占用主服务器的网络带宽,会对主服务器响应命令请求产生影响。
Redis 也是一样的,从服务器可以有自己的从服务器,我们可以把拥有从服务器的从服务器当作经理角色,它不仅可以接收主服务器的同步数据,自己也可以同时作为主服务器的形式将数据同步给从服务器。
增量复制
如果遇到网络延迟、断开,增量复制就可以上场了,不过这个还跟 repl_backlog_size 命令积压缓冲区这个大小有关系。
repl_backlog_buffer,可以理解成是一个「环形」缓冲区
如果它配置的过小,主从服务器网络恢复时,可能发生「从服务器」想读的数据已经被覆盖了,那么这时就会导致主服务器采用全量复制的方式。所以为了避免这种情况的频繁发生,要调大这个参数的值,以降低主从服务器断开后全量同步的概率。
优点
● 有了主从,提高了Redis整体的可用性,当主节点(master)挂了,可以把从节点(slave)手动升级为主节点继续服务。
缺点
● master 挂了整个 Redis 将失去写操作的能力,仅具备读操作,需要运维半夜爬起来手动升级,中间的请求失败数据丢失无法容忍。
解决办法
● 可以有一种方式自动升级slave为master ------【哨兵】
















 924
924











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











