









文章目录
1、介绍
quicklist是Redis底层最重要的数据结构之一,它是Redis对外提供的6种基本数据结构中List的底层实现。在quicklist之前,Redis采用压缩链表(ziplist)和双向链表(adlist)作为List的底层实现。当元素个数较少并且元素长度比较小时,Redis采用ziplist作为其底层存储,当元素长度较多时候,Redis采用adlist作为底层存储结构,因为修改元素的时候ziplist需要重新分配空间,这会导致效率降低。
2、quicklist
quicklist由List 和 ziplist 组合而成,ziplist在前面的文章种已经介绍了。本章将会基于ziplist继续介绍quicklist。
2.1、List
链表是一种线性结构,其中各对象按线性顺序排列。链表与数组不同点在于,数组的顺序由下标决定,链表的顺序由对象的指针决定。List是链型数据存储常用的数据结构,可以是单链表,双链表,循环链表非循环链表,有序链表,无序链表。链表相对于数组具有可以快速增加,修改的(需要重新分配内存空间),删除的优点。但是由于链表的查询效率是O(n),所以并不适用于快速查找的场景,Redis 3.2之前使用的是双向非循环链表,结构如下图所示:
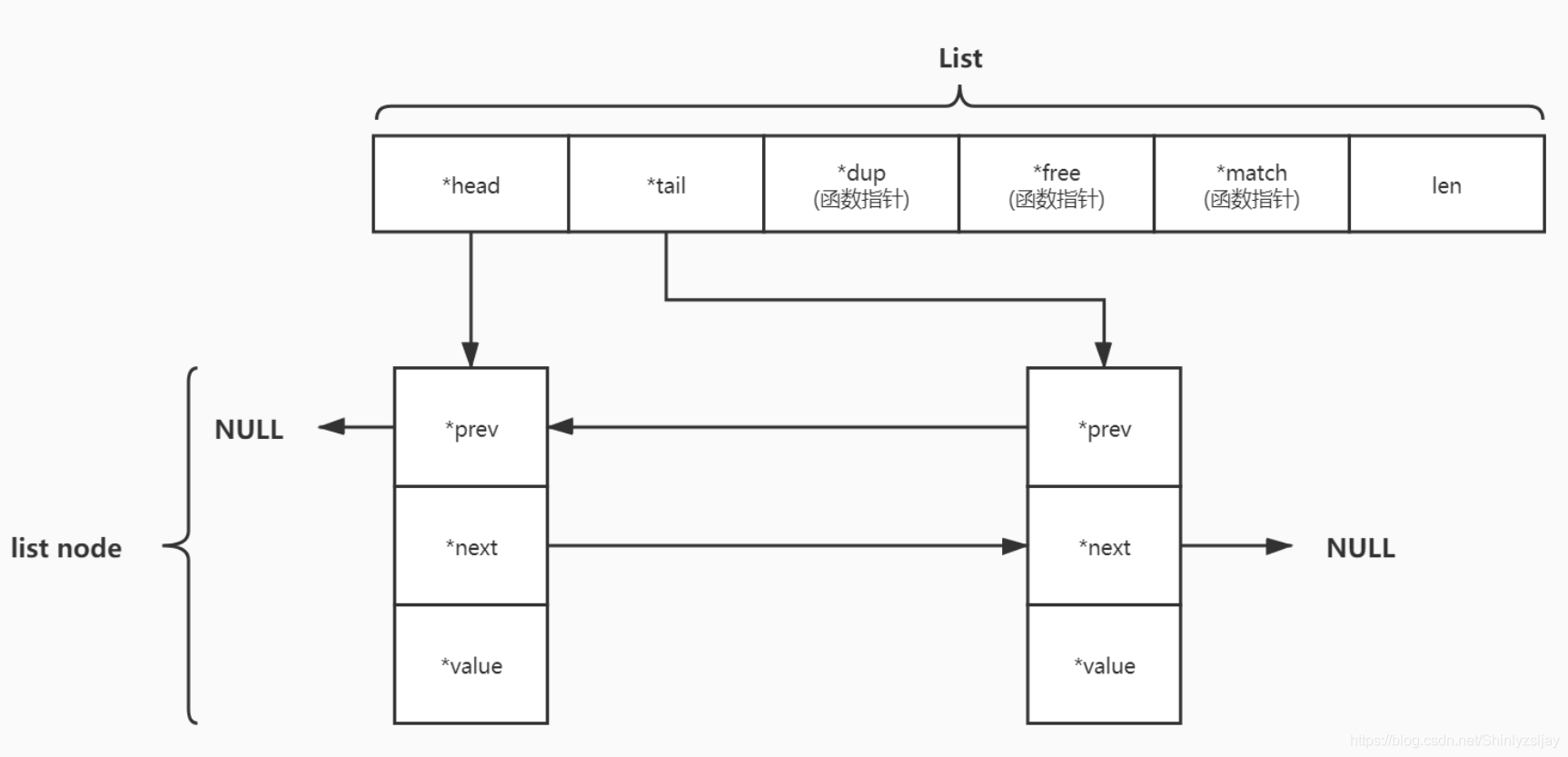
注明:函数指针指向的是一些方法函数用于操作链表
2.2、quicklist
quicklist是Redis3.2中引入的新结构,能够在时间效率和空间效率间实现较好的折中。quicklist是一个双向链表,链表中的每个节点都是一个ziplist结构,quicklist可以看成是将双向链表将若干个小型的ziplist组合在一起的数据结构。当ziplist节点个数较多的时候,quicklist退化成双向链表,一个极端的情况就是每个ziplist节点只有一个entry,即只有一个元素。当ziplist元素较少的时候,quicklist可以退化成ziplist,另一种极端的情况就是,整个quicklist中只有一个ziplist节点。结构如下图:
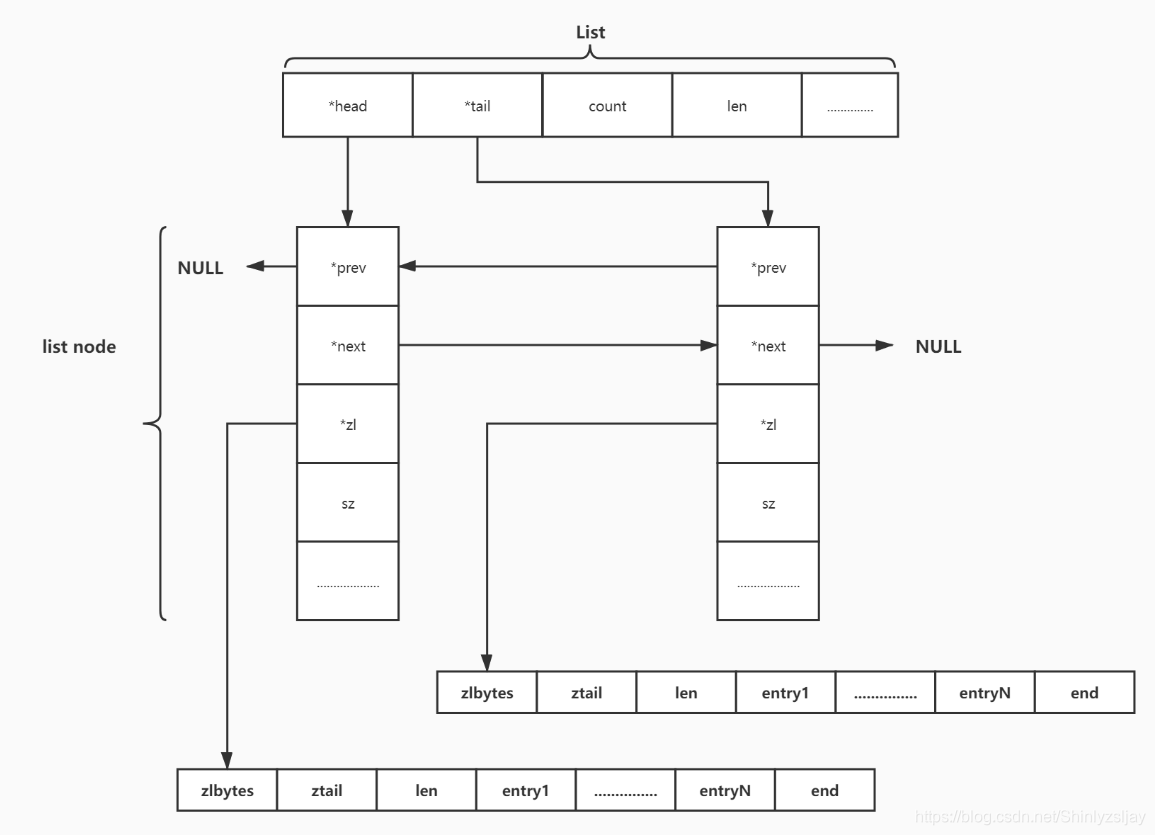
代码定义如下(quicklist.h):
typedef struct quicklist {
quicklistNode *head; //头结点
quicklistNode *tail; //尾节点
unsigned long count; //quicklist中的元素总数
unsigned long len; //quicklistNode节点个数
int fill : 16; //每个quicklistNode中的ziplist长度(或者指定大小类型)
unsigned int compress : 16; //不压缩的末端节点深度
} quicklist;
其中 head、tail 指向 quicklist 的首尾节点,count 为 quicklist 中元素总数;len 为 quicklistNode 的节点个数,fill用来指明每个quicklistNode中ziplist长度,当fill为正数时,表明每个ziplist最多含有的数据项数,当fill为负数的时含义如下:
| 数值 | 含义 |
|---|---|
| -1 | ziplist节点最大为4KB |
| -2 | ziplist节点最大为8KB |
| -3 | ziplist节点最大为16KB |
| -4 | ziplist节点最大为32KB |
| -5 | ziplist节点最大为64KB |
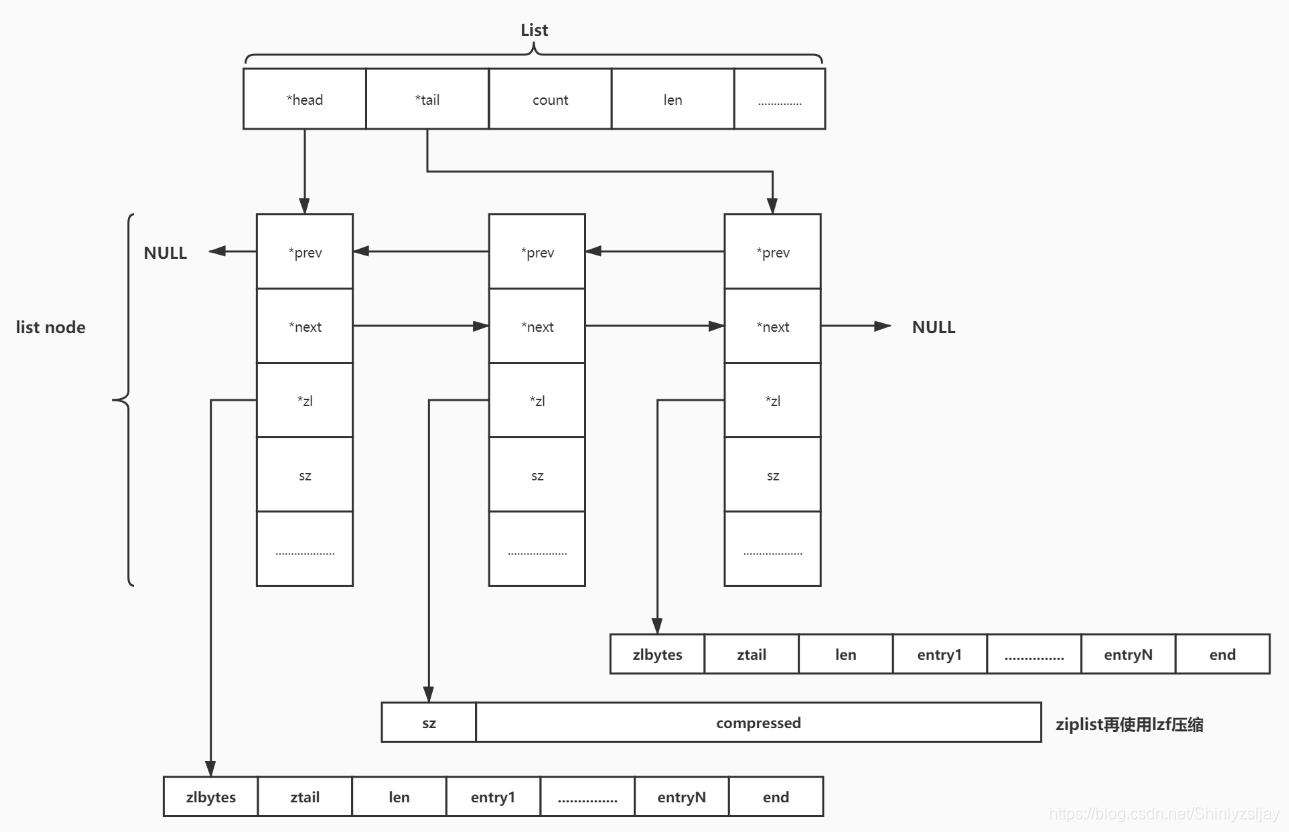
从表中可以看出来,fill取值为负数的时候,必须大于等于-5。我们可以通过Redis配置修改参数list-max-ziplist-size来配置节点占用内存大小。实际上的ziplist节点占用的空间会在这个基础上上下浮动,考虑quicklistNode节点个数较多的时候,我们经常访问的是两端的数据,为了进一步节省空间,Redis运行对中间的quicklistNode节点进行压缩,通过修改参数list-compress-depth进行配置,即设置compress参数的大小,为了更好的理解compress的含义,下面给出,当compress为1时,quicklistNode个数为3时的结构示意图:
2.2.1、quicklistNode
quicklistNode是一个quicklist中的节点,其结构如下 (quicklist.h):
typedef struct quicklistNode {
struct quicklistNode *prev; //前驱
struct quicklistNode *next; //后继
unsigned char *zl; //指向元素的指针
unsigned int sz; //整个ziplist的字节大小
unsigned int count : 16; //ziplist的元素数量
unsigned int encoding : 2; //编码方式:1原生编码 2使用LZF压缩
unsigned int container : 2; //zl指向的容器类型 1表示none 2表示使用ziplist存储
unsigned int recompress : 1;//代表这个节点之前是否是压缩节点,若是,则在使用压缩节点前先进行解压,使用后需要重新压缩,此外为1,代表是压缩节点;
unsigned int attempted_compress : 1; //attempted_compress测试时使用;
unsigned int extra : 10; //预留字段
} quicklistNode;
2.2.2、quicklistLZF
此外,当我们对ziplist利用LZF算法进行压缩的时候,quicklistNode节点指向的结构为quicklistLZF。quicklistLZF结构如上面的图片所示,其中sz表示compressed所占字节大小。结构如下:
typedef struct quicklistLZF {
unsigned int sz; //压缩后节点所占字节大小
char compressed[]; //压缩数据
} quicklistLZF;
2.2.2、quicklistEntry
当我们使用quicklistNode中ziplist中的一个节点时候,Redis提供了quicklistEntry结构以便于使用,该结构如下:
typedef struct quicklistEntry {
const quicklist *quicklist; //quicklist
quicklistNode *node; //指向当前元素所在的quicklistNode
unsigned char *zi; //指向当前元素所在的ziplist
unsigned char *value; //指向该节点的字符串内容
long long longval; //为该节点的整数值
unsigned int sz; //该节点的大小
int offset; //表明该节点相对于整个ziplist的偏移量,即该节点是ziplist的第多少个entry
} quicklistEntry;
2.2.3、quicklistIter
quicklistIter是quicklist中用于遍历的迭代器,结构如下:
typedef struct quicklistIter {
const quicklist *quicklist; //quicklist
quicklistNode *current; //指向当前遍历到的元素
unsigned char *zi; //指向元素所在的ziplist
long offset; //offset表明节点在所在的ziplist中的偏移量
int direction; //direction表明迭代器的方向
} quicklistIter;
//通过迭代器遍历 quicklist并将结果放入 quicklistEntry
int quicklistNext(quicklistIter *iter, quicklistEntry *entry) {
//初始化结构体 quicklistEntry
initEntry(entry);
if (!iter) {
D("Returning because no iter!");
return 0;
}
entry->quicklist = iter->quicklist;
entry->node = iter->current;
if (!iter->current) {
D("Returning because current node is NULL")
return 0;
}
unsigned char *(*nextFn)(unsigned char *, unsigned char *) = NULL;
int offset_update = 0;
if (!iter->zi) {
quicklistDecompressNodeForUse(iter->current);
iter->zi = ziplistIndex(iter->current->zl, iter->offset);
} else {
//刚刚开始遍历需要解码元素,并获取 zi
if (iter->direction == AL_START_HEAD) { //正向遍历
nextFn = ziplistNext; //压缩列表函数指针,用于获取下一个元素
offset_update = 1;
} else if (iter->direction == AL_START_TAIL) { //逆向遍历
nextFn = ziplistPrev; //压缩列表函数指针,用于获取上一个元素
offset_update = -1;
}
iter->zi = nextFn(iter->current->zl, iter->zi);
iter->offset += offset_update;
}
entry->zi = iter->zi;
entry->offset = iter->offset;
// if(iter->zi) 的主要目的是,判断是不是第一次遍历,还没解码,如果是先解码再解析
if (iter->zi) {
/* Populate value from existing ziplist position */
//解码将元素放入 entry
ziplistGet(entry->zi, &entry->value, &entry->sz, &entry->longval);
return 1;
} else {
quicklistCompress(iter->quicklist, iter->current);
if (iter->direction == AL_START_HEAD) {//正向遍历
D("Jumping to start of next node");
iter->current = iter->current->next;
iter->offset = 0;
} else if (iter->direction == AL_START_TAIL) { //逆向遍历
D("Jumping to end of previous node");//日志打印
iter->current = iter->current->prev;
iter->offset = -1;
}
iter->zi = NULL;
return quicklistNext(iter, entry);
}
}
3、数据压缩
quicklist每个节点的实际数据存储结构为ziplist,这种结构的主要优势在于节省内存空间。为了进一步降低ziplist占用空间,Redis允许对ziplist再进行一次压缩,Redis采用的压缩算法是LZF,压缩后数据可以分为多个片段,每个片段有两个部分,一部分是解释字段,另一部分是存放具体的数据字段。解释字段可以占用1~3个字节,数据字段可能不存在。

具体而言,LZF压缩的数据格式有三种,即解释字段有三种。
1、字面型,解释字段占用1给字节,数据字段长度由解释字段的后5位决定。如下图所示:
2、简短重复型,解释字段占用2个字节,没有数据字段,数据内容与前面数据内容重复,重复长度小于8,示例如下图所示:
3、批量重复型,解释字段占3字节,没有数据字段,数据内容与前面内容重复。如图所示:



3.1、压缩
LZF数据压缩的基本思想是:数据与前面重复的,记录重复位置以及重复长度,否则直接记录原始数据内容。压缩算法的流程如下:
1、遍历输入字符串,对当前字符及其后面2个字符进行散列运算
2、如果在Hash表中找到曾出现的记录,则计算重复字节的长度以及位置,反之直接输出数据
方法定义如下:
//in_data 和 in_len 为输入数据和长度,out_data 和 out_len 为输出数据和长度
lzf_compress (const void *const in_data, unsigned int in_len,
void *out_data, unsigned int out_len)
3.2、解压缩
根据LZF压缩后的数据格式,我们可以较为容易地实现LZF的解压缩。值得注意的是,可能存在重复数据与当前位置重叠的情况,例如在当前位置前的15个字节处,重复了20个字节,此时需要按位逐个复制。方法定义如下:
//in_data 和 in_len 为输入数据和长度,out_data 和 out_len 为输出数据和长度
lzf_decompress (const void *const in_data, unsigned int in_len,
void *out_data, unsigned int out_len)
4、基本操作
quicklist是一种数据结构,所以增、删、改、查、是必不可少的内容。由于quicklist利用ziplist结构进行实际的数据存储,所以quicklist的大部分操作实际是利用ziplist的函数接口实现的。
4.1、初始化
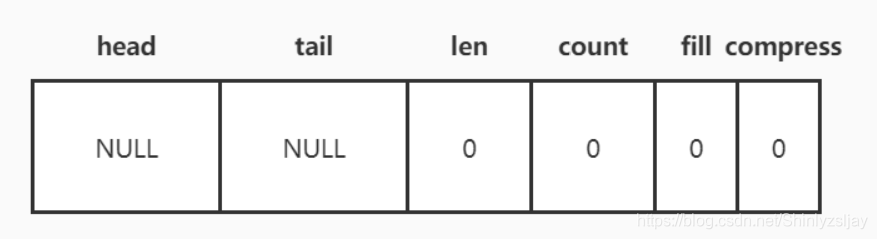
初始化是构建quicklist结构的第一步,由quicklistCreate函数完成,该函数的主要功能就是初始化quicklist结构。默认初始化的quicklist结构如图所示:
初始化代码如下:
quicklist *quicklistCreate(void) {
struct quicklist *quicklist;
quicklist = zmalloc(sizeof(*quicklist));
quicklist->head = quicklist->tail = NULL; //初始化 head 和 tail
quicklist->len = 0; // 初始化 len
quicklist->count = 0; // 初始化 count
quicklist->compress = 0; // 初始化,默认: 不压缩
quicklist->fill = -2; //默认大小限制 8kb
return quicklist;
}
从初始化代码可以看出,Redis默认quicklistNode每个ziplist的大小限制是8KB,并且不对节点进行压缩。
4.2、添加元素
quicklist提供了push作为添加元素的操作入口,对外暴露的接口为quicklistPush,可以在头部或者尾部进行插入。具体的操作函数为quicklistPushHead 与 quicklistPushTail,两者的思路基本一致,所以我们主要介绍quicklistPushHead的具体实现。
quicklistPushHead的基本思路是:查看quicklist原有的head节点是否可以插入,如果可以就直接利用ziplist的接口进行插入,否则创建一个新的quicklistNode节点进行插入。函数入参为待插入的quicklist,需要插入的数据value以及其大小sz;函数返回值代表是否新键了head节点,0代表没有新键,1代表新键了head。代码如下:
int quicklistPushHead(quicklist *quicklist, void *value, size_t sz) {
quicklistNode *orig_head = quicklist->head;
if (likely(//当前quicklistNode可以插入
_quicklistNodeAllowInsert(quicklist->head, quicklist->fill, sz))) {
quicklist->head->zl =
ziplistPush(quicklist->head->zl, value, sz, ZIPLIST_HEAD);//插入到ziplist
quicklistNodeUpdateSz(quicklist->head);
} else {//当前quicklistNode不能插入
quicklistNode *node = quicklistCreateNode();
node->zl = ziplistPush(ziplistNew(), value, sz, ZIPLIST_HEAD);//插入到ziplist
//更新ziplist的大小到sz
quicklistNodeUpdateSz(node);
//将新建的quicklistNode插入到quicklist结构体中
_quicklistInsertNodeBefore(quicklist, quicklist->head, node);
}
quicklist->count++;
quicklist->head->count++;
return (orig_head != quicklist->head);
}
_quicklistNodeAllowInsert 用来判断 quicklist 的某个quicklistNode是否可以继续插入。_quicklistInsertNodeBefore 用于在 quicklist 的某个节点之前插入quicklistNode。如果当前ziplist已经包含节点,在ziplist插入可能会导致连锁更新。
对于quicklist的一般插入可以分为能继续插入和不能继续插入:
1、当前插入的位置所在的
quicklistNode仍然可以继续插入,此时可以直接插入
2、当前插入位置所在的quicklistNode不能继续插入,此时可以分为以下几个情况:
(1)、需要向当前quicklistNode第一个位置插入时不能继续插入,但是当前 ziplist 的前一个quicklistNode可以继续插入,则将数据插入前一个quicklistNode,否则创建一个新的quicklistNode并插入。
(2)、需要向当前quicklistNode的最后一个元素插入,当前 ziplist 所在的quicklistNode的后一个quicklistNode可以插入,则将数据插入到后一个quicklistNode。如果后一个也不能插入,则新建一个quicklistNode,插入到当前quicklistNode的后面。
(3)、不满足前面两种情况的,则将当前待插入quicklistNode的位置为基准,拆分成左右两个quicklistNode。拆分的方法是:先复制一份ziplist,通过对新旧两个ziplist进行区域删除完成。具体参考ziplist的基本操作。
如下图所示:
情况一:
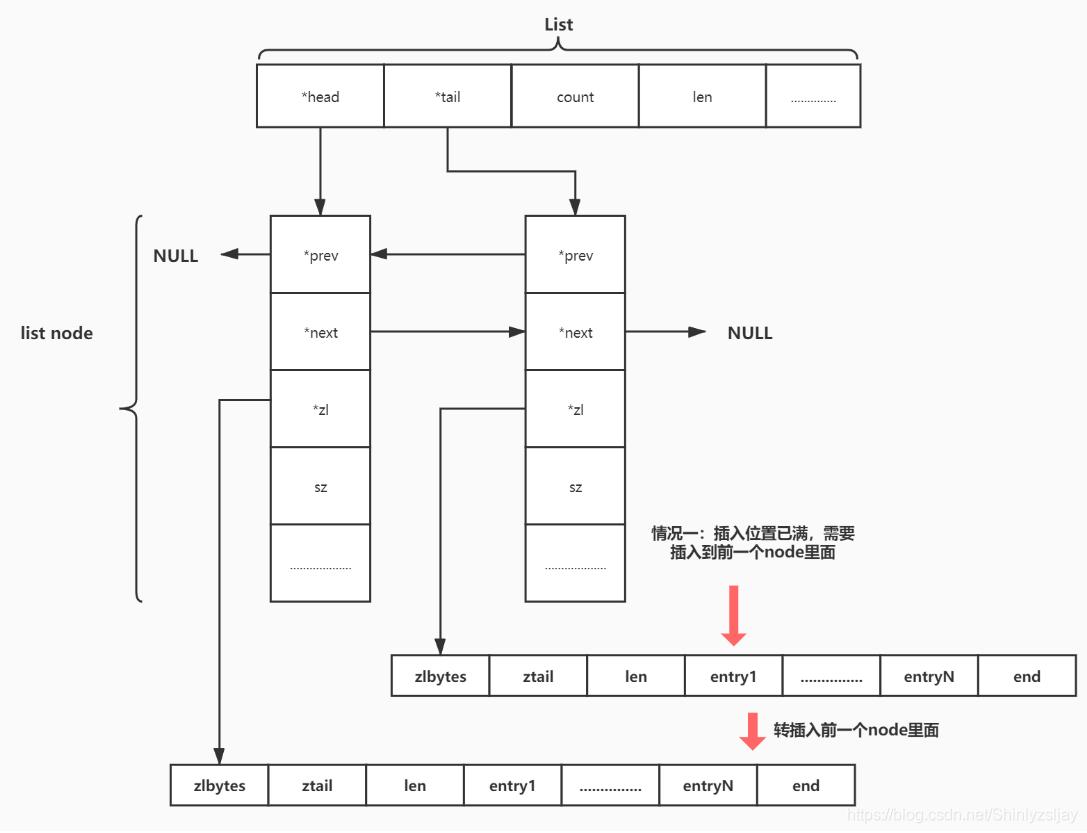
情况二:
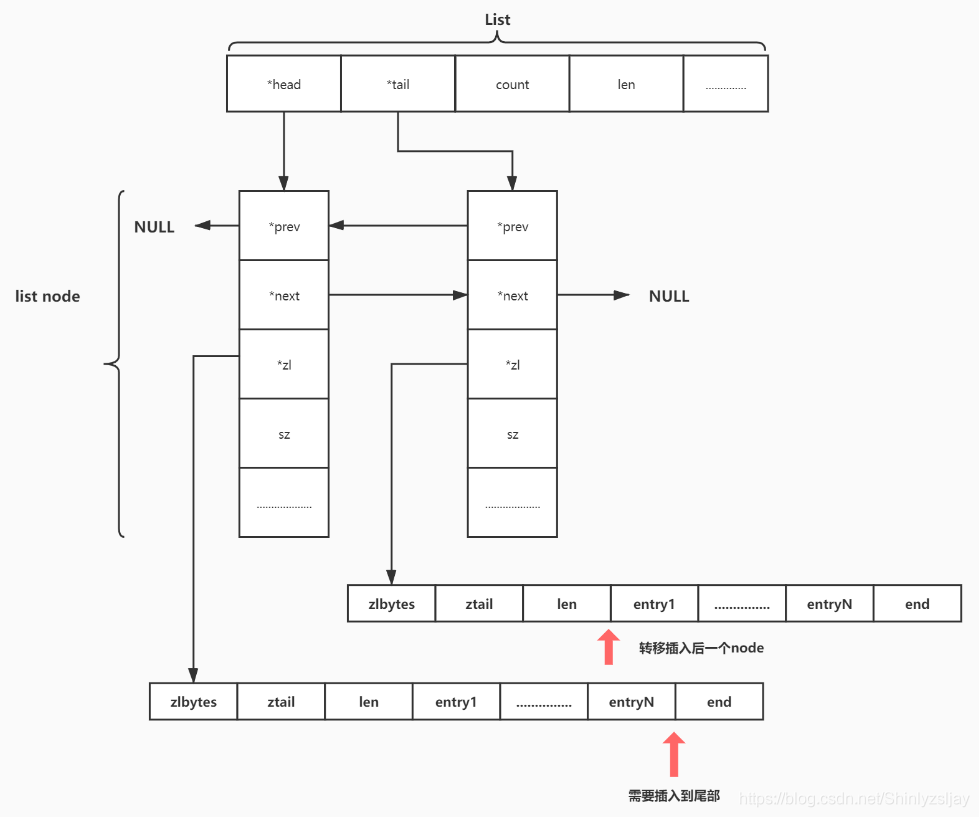
情况三:
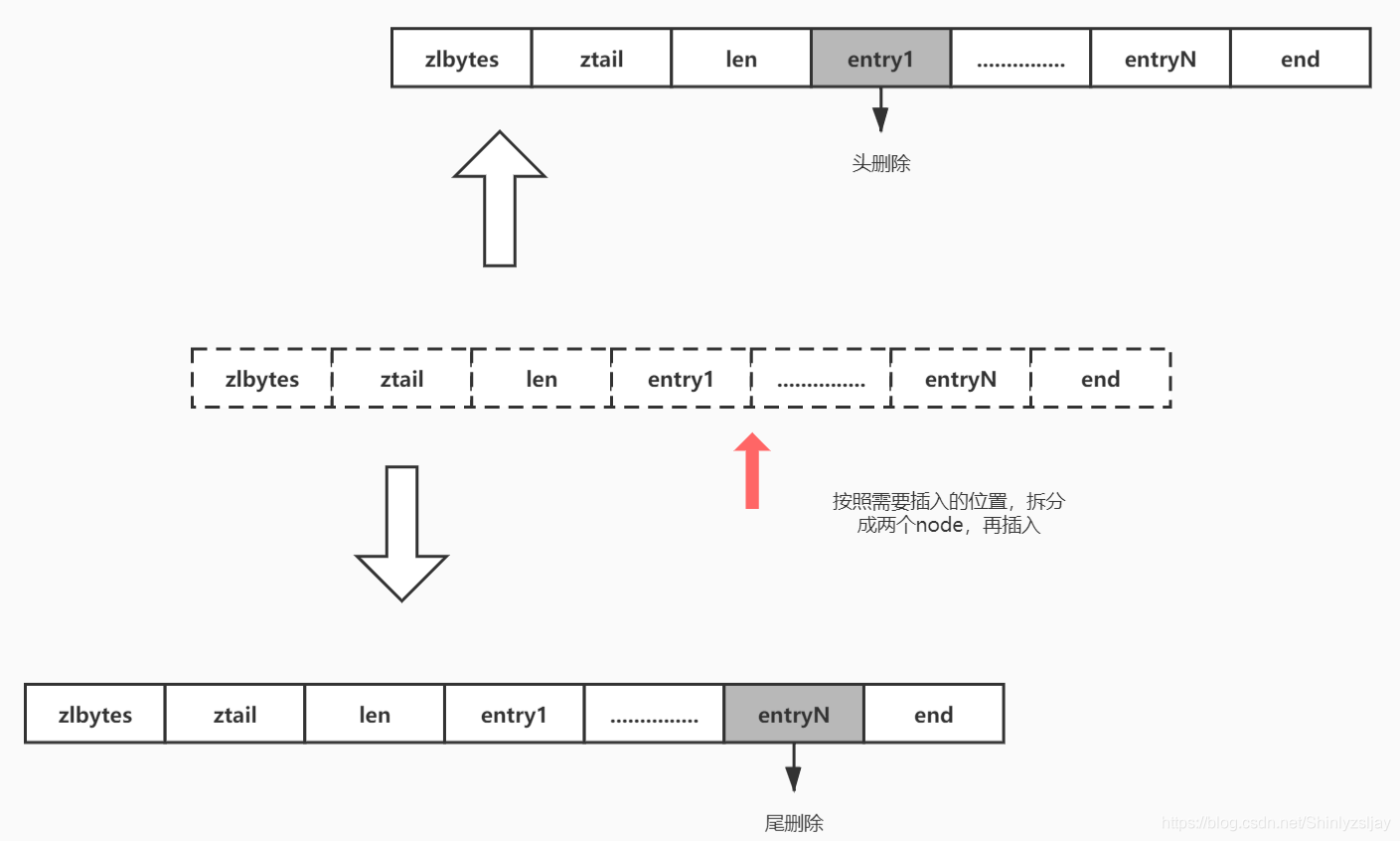
4.3、删除元素
quicklist 对于元素删除提供了 单一元素删除 和 区域元素删除 两种方案。对于单一元素删除,我们可以使用 quicklist 提供的quicklistDelEntry实现,也可以通过quicklistPop将头部元素或者尾部元素弹出。quicklistDelEntry函数调用底层quicklistDelIndex函数,该函数可以删除quicklistNode指向的 ziplist 中的某个元素,其中指针p指向 ziplist 中某个entry的起始位置。quicklistPop可以弹出头部或者尾部元素,具体实现是通过ziplist的接口获取元素值,再通过上述的quicklistDelIndex将数据删除。函数定义如下:
//指定位置删除
int quicklistDelIndex(quicklist *quicklist, quicklistNode *node,
unsigned char **p);
//元素pop
int quicklistPop(quicklist *quicklist, int where, unsigned char **data,
unsigned int *sz, long long *slong);
对于删除区间元素,quicklist提供了quicklistDelRange接口,该函数可以从指定位置删除指定数量的元素。函数定义如下:
int quicklistDelRange(quicklist *quicklist, const long start, const long count);
区间删除,不只会删除当前quicklistNode的元素,也能删除从当前quicklistNode开始往后quicklistNode的元素
核心代码如下:
//extent是需要删除的元素个数
while (extent) {
quicklistNode *next = node->next;
unsigned long del;
int delete_entire_node = 0;
if (entry.offset == 0 && extent >= node->count) {
//情况一、需要删除整个quicklistNode
delete_entire_node = 1;
del = node->count;
} else if (entry.offset >= 0 && extent >= node->count) {
//情况二、删除本节点剩余所有元素
del = node->count - entry.offset;
} else if (entry.offset < 0) {
//entry.offset < 0 代表从后向前,相反数代表这个ziplist后面剩余元素个数。
del = -entry.offset;
if (del > extent)
del = extent;
} else {
//删除本quicklistNode的部分元素
del = extent;
}
//打印日志
D("[%ld]: asking to del: %ld because offset: %d; (ENTIRE NODE: %d), "
"node count: %u",
extent, del, entry.offset, delete_entire_node, node->count);
//如果需要整个quicklistNode删除,则直接删除,否则按照情况来删除
if (delete_entire_node) {
__quicklistDelNode(quicklist, node);
} else {
quicklistDecompressNodeForUse(node);
//范围删除 当前offset 开始 到需要删除的位置
node->zl = ziplistDeleteRange(node->zl, entry.offset, del);
quicklistNodeUpdateSz(node);
node->count -= del;
quicklist->count -= del;
quicklistDeleteIfEmpty(quicklist, node);
if (node)
quicklistRecompressOnly(quicklist, node);
}
extent -= del; //剩余待删除元素个数
node = next; //下个quicklistNode
entry.offset = 0; //从下个quicklistNode起始位置开始删
}
return 1;
4.4、更改元素
quicklist 更改元素是基于index,主要的处理函数为quicklistReplaceAtIndex。其基本思路是先删除原有元素,之后插入新的元素。quicklist 不适合直接改变原有的元素,主要是由于其内部结构是ziplist (前面有提到过,压缩列表不适合更改元素) 限制的。代码如下所示:
int quicklistReplaceAtIndex(quicklist *quicklist, long index, void *data,
int sz) {
quicklistEntry entry;
if (likely(quicklistIndex(quicklist, index, &entry))) {
entry.node->zl = ziplistDelete(entry.node->zl, &entry.zi);
entry.node->zl = ziplistInsert(entry.node->zl, entry.zi, data, sz);
quicklistNodeUpdateSz(entry.node);
quicklistCompress(quicklist, entry.node);
return 1;
} else {
return 0;
}
}
4.5、查找元素
quicklist是通过index去查找元素的,实现函数是quicklistIndex,其基本思路是:
1、定位到目标元素所在的
quicklistNode节点
2、调用 ziplist 的查找接口ziplistGet得到相应的index
代码如下:
int quicklistIndex(const quicklist *quicklist, const long long idx,
quicklistEntry *entry) {
quicklistNode *n;
unsigned long long accum = 0;
unsigned long long index;
//当idx值为负数的时候,代表是从尾部向头部的便宜量,-1代表尾部元素,确定查找方向
int forward = idx < 0 ? 0 : 1; /* < 0 -> reverse, 0+ -> forward */
//初始化 quicklistEntry 最终查找到的数据会放入quicklistEntry里面
initEntry(entry);
entry->quicklist = quicklist;
//判断头查找还是尾查找
if (!forward) {
index = (-idx) - 1;
n = quicklist->tail;
} else {
index = idx;
n = quicklist->head;
}
if (index >= quicklist->count)
return 0;
//遍历quicklistNode节点,找到index对应的quicklistNode
while (likely(n)) {
if ((accum + n->count) > index) {
break;
} else {
//打印日志
D("Skipping over (%p) %u at accum %lld", (void *)n, n->count,
accum);
accum += n->count;
n = forward ? n->next : n->prev;
}
}
if (!n)
return 0;
//打印日志
D("Found node: %p at accum %llu, idx %llu, sub+ %llu, sub- %llu", (void *)n,
accum, index, index - accum, (-index) - 1 + accum);
//计算index所在的ziplist的偏移量
entry->node = n;
if (forward) {
entry->offset = index - accum;
} else {
entry->offset = (-index) - 1 + accum;
}
quicklistDecompressNodeForUse(entry->node);
entry->zi = ziplistIndex(entry->node->zl, entry->offset);
//通过ziplist获取元素存入 quicklistEntry
ziplistGet(entry->zi, &entry->value, &entry->sz, &entry->longval);
return 1;
}
对于 quicklist 的迭代器主要的实现函数如下:
//获取指向头部,依次向后的迭代器;或指向尾部,依次向前的迭代器
quicklistIter *quicklistGetIterator(const quicklist *quicklist, int direction);
//获取idx位置的迭代器,可以向前或者向后遍历
quicklistIter *quicklistGetIteratorAtIdx(const quicklist *quicklist,
int direction, const long long idx);
//获取迭代器指向的下一个元素
int quicklistNext(quicklistIter *iter, quicklistEntry *node);
5、常用API
| 函数名称 | 函数用途 | 时间复杂度 |
|---|---|---|
| quicklistCreate | 创建默认quicklist | O(1) |
| quicklistNew | 创建自定义属性quicklist | O(1) |
| quicklistPushHead | 在头部插入数据 | O(m) |
| quicklistPushTail | 在尾部插入数据 | O(m) |
| quicklistPush | 在头部或者尾部插入数据 | O(m) |
| quicklistInsertAfter | 在某个元素后面插入数据 | O(m) |
| quicklistInsertBefore | 在某个元素前面插入数据 | O(m) |
| quicklistDelEntry | 删除某个元素 | O(m) |
| quicklistDelRange | 删除某个区间的所有元素 | O(1/m+ m) |
| quicklistPop | 弹出头部或者尾部元素 | O(m) |
| quicklistReplaceAtIndex | 替换某个元素 | O(m) |
| quicklistIndex | 获取某个位置的元素 | O(n+m) |
| quicklistGetIterator | 获取指向头部或尾部的迭代器 | O(1) |
| quicklistGetIteratorAtIdx | 获取特定位置的迭代器 | O(n+m) |
| quicklistNext | 获取迭代器下一个元素 | O(m) |














 313
313











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









